

How to conduct LLM evaluation based on Arthur Bench?

Hello folks, I am Luga. Today we will talk about technologies related to the artificial intelligence (AI) ecological field - LLM evaluation.

1. Challenges faced by traditional text evaluation
In recent years, with the rapid development and improvement of large language models (LLM), traditional text evaluation The method may no longer be applicable in some respects. In the field of text evaluation, we may have heard of methods such as "word occurrence" based evaluation methods, such as BLEU, and "pre-trained natural language processing models" based evaluation methods, such as BERTScore.
Although these methods have performed well in the past, with the continuous development of LLM ecological technology, they seem to be slightly inadequate and unable to fully meet current needs.
With the rapid development and continuous improvement of LLM technology, we are facing new challenges and opportunities. LLM continues to improve in capabilities and performance levels, which makes word frequency-based evaluation methods (such as BLEU) potentially unable to fully capture the quality and semantic accuracy of LLM-generated text. LLM can generate more fluent, coherent and semantically rich text, while traditional word frequency-based evaluation methods are difficult to accurately evaluate these advantages.
In addition, evaluation methods based on pre-trained models, such as BERTScore, also face some challenges. Although pre-trained models perform well on many tasks, they may not fully take into account the special characteristics of LLM and its performance on specific tasks. LLMs may exhibit different behavior and performance than pre-trained models when handling specific tasks, so relying solely on evaluation methods based on pre-trained models may not fully assess the capabilities of LLMs.
2. Why is LLM guidance assessment required? And what challenges does it bring?
Generally speaking, in actual business environments, the value of the LLM method is mainly reflected in its "speed" and " Sensitivity", these two aspects are the most important evaluation indicators.
1. Efficient
First, generally speaking, implementation is faster. Compared to the amount of work required by previous assessment pipelines, creating a first implementation of an LLM-guided assessment is relatively quick and easy. For LLM-guided assessment, we only need to prepare two things: describe the assessment criteria in words, and provide some examples for use in the prompt template. Relative to the amount of work and data collection required to build your own pre-trained NLP model (or fine-tune an existing NLP model) to serve as an estimator, using an LLM to accomplish these tasks is more efficient. With LLM, iteration of the evaluation criteria is much faster.
2. Sensitivity
LLM usually exhibits higher sensitivity. This sensitivity may have its positive side, as LLM is more flexible in handling various situations than pre-trained NLP models and the previously discussed evaluation methods. However, this high sensitivity may also make LLM assessment results difficult to predict. Small changes in LLM's input data can have significant effects, which makes it possible to exhibit greater volatility when handling specific tasks. Therefore, when evaluating LLM, special attention needs to be paid to its sensitivity to ensure the stability and reliability of the results.
As we discussed earlier, LLM evaluators are more sensitive than other evaluation methods. There are many different ways to configure LLM as an evaluator, and its behavior can vary greatly depending on the configuration chosen. Meanwhile, another challenge is that LLM evaluators can get stuck if the evaluation involves too many inferential steps or requires processing too many variables simultaneously.
Due to the characteristics of LLM, its evaluation results may be affected by different configurations and parameter settings. This means that when evaluating LLMs, the model needs to be carefully selected and configured to ensure that it behaves as expected. Different configurations may lead to different output results, so the evaluator needs to spend some time and effort to adjust and optimize the settings of the LLM to obtain accurate and reliable evaluation results.
Additionally, evaluators may face some challenges when faced with evaluation tasks that require complex reasoning or the simultaneous processing of multiple variables. This is because the reasoning ability of LLM may be limited when dealing with complex situations. The LLM may require additional effort to address these tasks to ensure the accuracy and reliability of the assessment.
3. What is Arthur Bench?
Arthur Bench is an open source evaluation tool used to compare the performance of generative text models (LLM). It can be used to evaluate different LLM models, cues, and hyperparameters and provide detailed reports on LLM performance on various tasks.
The main features of Arthur Bench include:The main features of Arthur Bench include:
- Compare different LLM models: Arthur Bench can be used to compare the performance of different LLM models, including models from different vendors, different versions of models, and models using different training data sets.
- Evaluate Tips: Arthur Bench can be used to evaluate the impact of different tips on LLM performance. Prompts are instructions used to guide LLM in generating text.
- Testing hyperparameters: Arthur Bench can be used to test the impact of different hyperparameters on LLM performance. Hyperparameters are settings that control the behavior of LLM.
Generally speaking, the Arthur Bench workflow mainly involves the following stages, and the specific detailed analysis is as follows:
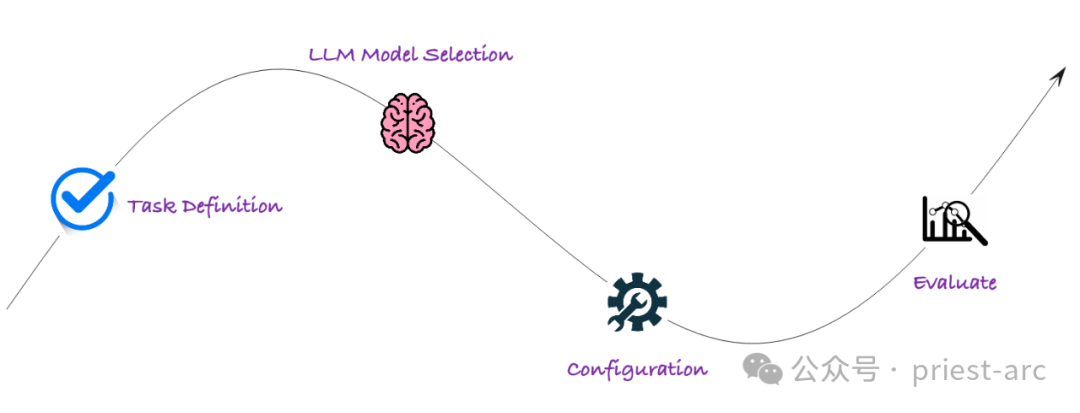
1. Task Definition
At this stage, we need to clarify our assessment goals. Arthur Bench supports a variety of assessment tasks, including:
- Q&A: Testing LLM for open-ended, challenge Ability to understand and answer ambiguous or ambiguous questions.
- Summary: Evaluate LLM's ability to extract key information from text and generate concise summaries.
- Translation: Examine LLM’s ability to translate accurately and fluently between different languages.
- Code generation: Test the ability of LLM to generate code based on natural language descriptions.
2. Model selection
At this stage, the main work is to select the evaluation objects. Arthur Bench supports a variety of LLM models, covering leading technologies from well-known institutions such as OpenAI, Google AI, Microsoft, etc., such as GPT-3, LaMDA, Megatron-Turing NLG, etc. We can select specific models for evaluation based on research needs.
3. Parameter configuration
After completing the model selection, proceed to fine-tuning. To more accurately evaluate LLM performance, Arthur Bench allows users to configure hints and hyperparameters.
- Tip: Guide LLM in the direction and content of generated text, such as questions, descriptions, or instructions.
- Hyperparameters: Key settings that control LLM behavior, such as learning rate, number of training steps, model architecture, etc.
Through refined configuration, we can deeply explore the performance differences of LLM under different parameter settings and obtain evaluation results with more reference value.
4. Assessment run: automated process
The last step is to conduct task assessment with the help of automated process. Typically, Arthur Bench provides an automated assessment process that requires simple configuration to run assessment tasks. It will automatically perform the following steps:
- Call the LLM model and generate text output.
- For specific tasks, apply corresponding evaluation indicators for analysis.
- Generate detailed reports and present evaluation results.
4. Arthur Bench usage scenario analysis
As the key to a fast, data-driven LLM evaluation, Arthur Bench mainly provides the following solutions, specifically involving:
1. Model selection and verification
Model selection and verification are crucial steps in the field of artificial intelligence and are of great significance to ensure the validity and reliability of the model. In this process, Arthur Bench's role was crucial. His goal is to provide companies with a reliable comparison framework to help them make informed decisions among the many large language model (LLM) options through the use of consistent metrics and evaluation methods.
Arthur Bench will apply his expertise and experience to evaluate each LLM option and ensure consistent metrics are used to compare their benefits and Disadvantages. He will consider factors such as model performance, accuracy, speed, resource requirements and more to ensure companies can make informed and clear choices.
By using consistent metrics and evaluation methodologies, Arthur Bench will provide companies with a reliable comparison framework, allowing them to fully evaluate the benefits and limitations of each LLM option. This will enable companies to make informed decisions to maximize the rapid advances in artificial intelligence and ensure the best possible experience with their applications.
2. Budget and Privacy Optimization
When choosing an artificial intelligence model, not all applications require the most advanced or expensive large language models (LLM). In some cases, mission requirements can be met using less expensive AI models.
This budget optimization approach can help companies make wise choices with limited resources. Instead of going for the most expensive or state-of-the-art model, choose the right one based on your specific needs. The more affordable models may perform slightly worse than state-of-the-art LLMs in some aspects, but for some simple or standard tasks, Arthur Bench can still provide a solution that meets the needs.
Additionally, Arthur Bench emphasized that bringing the model in-house allows for greater control over data privacy. For applications involving sensitive data or privacy issues, companies may prefer to use their own internally trained models rather than relying on external, third-party LLMs. By using internal models, companies can gain greater control over the processing and storage of data and better protect data privacy.
3. Translate academic benchmarks into real-world performance
Academic benchmarks refer to model evaluation indicators and methods established in academic research. These indicators and methods are usually specific to a specific task or domain and can effectively evaluate the performance of the model in that task or domain.
However, academic benchmarks do not always directly reflect the performance of models in the real world. This is because application scenarios in the real world are often more complex and require more factors to be considered, such as data distribution, model deployment environment, etc.
Arthur Bench helps translate academic benchmarks into real-world performance. It achieves this goal in the following ways:
- Provides a comprehensive set of evaluation indicators covering multiple aspects of the model's accuracy, efficiency, robustness, etc. These indicators can not only reflect the performance of the model under academic benchmarks, but also the potential performance of the model in the real world.
- Supports multiple model types and can compare different types of models. This enables enterprises to choose the model that best suits their application scenarios.
- Provides visual analysis tools to help enterprises intuitively understand the performance differences of different models. This enables businesses to make decisions more easily.
5. Arthur Bench Feature Analysis
As the key to a fast, data-driven LLM assessment, Arthur Bench has the following features:
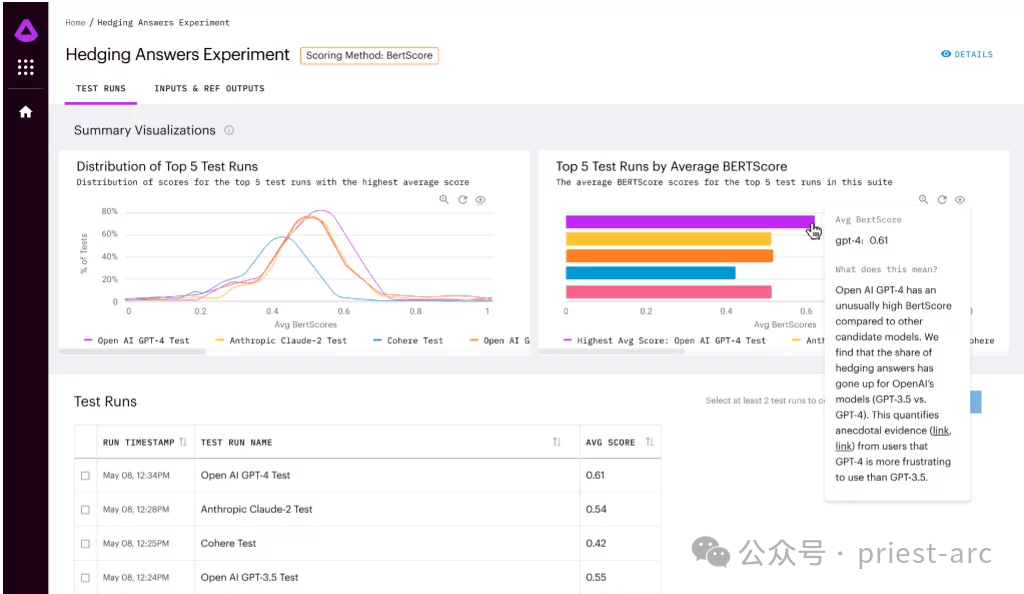
1. Full set of scores Metrics
Arthur Bench has a comprehensive set of scoring metrics covering everything from summary quality to user experience. He can use these scoring metrics at any time to evaluate and compare different models. The combined use of these scoring metrics can help him fully understand the strengths and weaknesses of each model.
The scope of these scoring indicators is very wide, including but not limited to summary quality, accuracy, fluency, grammatical correctness, context understanding ability, logical coherence, etc. Arthur Bench will evaluate each model against these metrics and combine the results into a comprehensive score to assist companies in making informed decisions.
Additionally, if a company has specific needs or concerns, Arthur Bench can create and add custom scoring metrics based on the company's requirements. This is done to better meet the company's specific needs and ensure that the assessment process is consistent with the company's goals and standards.
2. Local version and cloud-based version
For those who prefer local deployment and autonomous control, you can download the Get access to the GitHub repository and deploy Arthur Bench to your local environment. In this way, everyone can fully master and control the operation of Arthur Bench and customize and configure it according to their own needs.
On the other hand, for those users who prefer convenience and flexibility, cloud-based SaaS products are also available. You can choose to register to access and use Arthur Bench through the cloud. This method eliminates the need for cumbersome local installation and configuration, and enables you to enjoy the provided functions and services immediately.
3. Completely open source
As an open source project, Arthur Bench shows its typical open source characteristics in terms of transparency, scalability and community collaboration. This open source nature provides users with a wealth of advantages and opportunities to gain a deeper understanding of how the project works, and to customize and extend it to suit their needs. At the same time, the openness of Arthur Bench also encourages users to actively participate in community collaboration, collaborate and develop with other users. This open cooperation model helps promote the continuous development and innovation of the project, while also creating greater value and opportunities for users.
In short, Arthur Bench provides an open and flexible framework that enables users to customize evaluation indicators, and has been widely used in the financial field. Partnerships with Amazon Web Services and Cohere further advance the framework, encouraging developers to create new metrics for Bench and contribute to advances in the field of language model evaluation.
Reference:
- [1] https://github.com/arthur-ai/bench
- [2] https://neurohive.io/ en/news/arthur-bench-framework-for-evaluating-language-models/
The above is the detailed content of How to conduct LLM evaluation based on Arthur Bench?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix will display new AI-related products on August 6: 12-layer HBM3E, 321-high NAND, etc.
Aug 01, 2024 pm 09:40 PM
According to news from this site on August 1, SK Hynix released a blog post today (August 1), announcing that it will attend the Global Semiconductor Memory Summit FMS2024 to be held in Santa Clara, California, USA from August 6 to 8, showcasing many new technologies. generation product. Introduction to the Future Memory and Storage Summit (FutureMemoryandStorage), formerly the Flash Memory Summit (FlashMemorySummit) mainly for NAND suppliers, in the context of increasing attention to artificial intelligence technology, this year was renamed the Future Memory and Storage Summit (FutureMemoryandStorage) to invite DRAM and storage vendors and many more players. New product SK hynix launched last year
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
 Iyo One: Part headphone, part audio computer
Aug 08, 2024 am 01:03 AM
Iyo One: Part headphone, part audio computer
Aug 08, 2024 am 01:03 AM
At any time, concentration is a virtue. Author | Editor Tang Yitao | Jing Yu The resurgence of artificial intelligence has given rise to a new wave of hardware innovation. The most popular AIPin has encountered unprecedented negative reviews. Marques Brownlee (MKBHD) called it the worst product he's ever reviewed; The Verge editor David Pierce said he wouldn't recommend anyone buy this device. Its competitor, the RabbitR1, isn't much better. The biggest doubt about this AI device is that it is obviously just an app, but Rabbit has built a $200 piece of hardware. Many people see AI hardware innovation as an opportunity to subvert the smartphone era and devote themselves to it.
 Hinton serves as an advisor, and 'AI + materials” start-up CuspAI announces it has received US$30 million in seed round financing
Jun 19, 2024 pm 02:01 PM
Hinton serves as an advisor, and 'AI + materials” start-up CuspAI announces it has received US$30 million in seed round financing
Jun 19, 2024 pm 02:01 PM
Editor | Cactus Carbon capture material innovation is transforming as artificial intelligence accelerates the materials design process. A new company has just come out of stealth mode and announced a $30 million seed round of financing to use artificial intelligence to quickly generate and evaluate a large number of novel structures to design new materials. The startup, CuspAI, is based in Cambridge and Amsterdam and was founded by renowned professionals in the field of artificial intelligence, including former Microsoft Research and Qualcomm Distinguished Scientist and Vice President Professor Max Welling, as well as chemists involved in the commercialization of deep technologies at Google and BASF Dr. Chad Edwards. Geoffrey Hinton, known as the "Godfather of Artificial Intelligence," will serve as an advisor to the board of directors. The startup is a materials
 The first fully automated scientific discovery AI system, Transformer author startup Sakana AI launches AI Scientist
Aug 13, 2024 pm 04:43 PM
The first fully automated scientific discovery AI system, Transformer author startup Sakana AI launches AI Scientist
Aug 13, 2024 pm 04:43 PM
Editor | ScienceAI A year ago, Llion Jones, the last author of Google's Transformer paper, left to start a business and co-founded the artificial intelligence company SakanaAI with former Google researcher David Ha. SakanaAI claims to create a new basic model based on nature-inspired intelligence! Now, SakanaAI has handed in its answer sheet. SakanaAI announces the launch of AIScientist, the world’s first AI system for automated scientific research and open discovery! From conceiving, writing code, running experiments and summarizing results, to writing entire papers and conducting peer reviews, AIScientist unlocks AI-driven scientific research and acceleration
