
 Technology peripherals
AI
Unparalleled UniVision: BEV detection and Occ joint unified framework, dual SOTA!
Technology peripherals
AI
Unparalleled UniVision: BEV detection and Occ joint unified framework, dual SOTA!
Unparalleled UniVision: BEV detection and Occ joint unified framework, dual SOTA!

Written in front & personal understanding
In recent years, vision-centered 3D perception in autonomous driving technology has made rapid progress. Although various 3D perception models have many structural and conceptual similarities, there are still some differences in feature representation, data formats, and goals, which brings challenges to the design of a unified and efficient 3D perception framework. Therefore, researchers are working hard to find solutions to better integrate the differences between different models to build more complete and efficient 3D perception systems. This kind of effort is expected to bring more reliable and advanced technology to the field of autonomous driving, making it more capable in complex environments, especially the detection tasks and occupancy tasks under BEV. If you want to do a good job in joint training, It’s still very difficult, and the instability and uncontrollable effects make it a headache for many applications. UniVision is a simple and efficient framework that unifies two main tasks in vision-centric 3D perception, namely occupancy prediction and object detection. The core point is an explicit-implicit view transformation module for complementary 2D-3D feature transformation. UniVision proposes a local and global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement and Interaction.
In the data enhancement part, UniVision also proposed a joint occupancy detection data enhancement strategy and a progressive loss weight adjustment strategy to improve the efficiency and stability of multi-task framework training. Extensive experiments are conducted on different perception tasks on four public benchmarks, including scene-free lidar segmentation, scene-free detection, OpenOccupancy and Occ3D. UniVision achieved SOTA with gains of 1.5 mIoU, 1.8 NDS, 1.5 mIoU and 1.8 mIoU on each benchmark respectively. The UniVision framework can serve as a high-performance baseline for unified vision-centric 3D perception tasks.
If you are not familiar with BEV and Occupancy tasks, you are also welcome to further study our
BEV Perception Tutorialand Occupancy Occupancy Network Tutorial to learn more technical details !
The current state of the field of 3D perception3D perception is the primary task of autonomous driving systems, which aims to utilize a series of sensors (such as lidar, radar and cameras) The data obtained can be used to comprehensively understand the driving scene and be used for subsequent planning and decision-making. In the past, the field of 3D perception has been dominated by lidar-based models due to the precise 3D information derived from point cloud data. However, lidar-based systems are costly, susceptible to severe weather, and inconvenient to deploy. In contrast, vision-based systems have many advantages, such as low cost, easy deployment, and good scalability. Therefore, vision-centered three-dimensional perception has attracted widespread attention from researchers.
Recently, vision-based 3D detection has been significantly improved through feature representation transformation, temporal fusion, and supervised signal design, continuously closing the gap with lidar-based models. In addition, vision-based occupancy tasks have developed rapidly in recent years. Unlike using 3D boxes to represent some objects, occupancy can describe the geometry and semantics of the driving scene more comprehensively and is less limited to the shape and category of objects.
Although detection methods and occupancy methods share many structural and conceptual similarities, handling both tasks simultaneously and exploring their interrelationships has not been well studied. Occupancy models and detection models often extract different feature representations. The occupancy prediction task requires exhaustive semantic and geometric judgments at different spatial locations, so voxel representations are widely used to preserve fine-grained 3D information. In detection tasks, BEV representation is preferred since most objects are on the same horizontal plane with smaller overlap.
Compared with BEV representation, voxel representation is fine, but less efficient. In addition, many advanced operators are mainly designed and optimized for 2D features, making their integration with 3D voxel representation not so simple. The BEV representation is more time- and memory-efficient, but it is suboptimal for dense spatial predictions because it loses structural information in the height dimension. In addition to feature representation, different perception tasks also differ in data formats and goals. Therefore, ensuring the uniformity and efficiency of training multi-task 3D perception frameworks is a huge challenge.
UniVision Network StructureThe overall structure of the UniVision framework is shown in Figure 1. The framework receives multi-view images from N surrounding cameras as input and extracts image features through an image feature extraction network. Next, the 2D image features are upgraded to 3D voxel features using the Ex-Im view transformation module, which combines depth-guided explicit feature enhancement and query-guided implicit feature sampling. The voxel features are processed by local global feature extraction and fusion block to extract local context-aware voxel features and global context-aware BEV features respectively. Subsequently, information is exchanged between voxel features and BEV features for different downstream perception tasks through the cross-representation feature interaction module. In the training phase, the UniVision framework adopts a strategy of combined Occ-Det data enhancement and gradual adjustment of loss weights to effectively train.
1) Ex-Im View Transform
Depth-oriented explicit feature enhancement. The LSS approach is followed here:
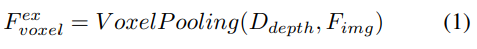
#2) Query-guided implicit feature sampling. However, there are some drawbacks in representing 3D information. The accuracy of is highly correlated with the accuracy of the estimated depth distribution. Furthermore, the points generated by LSS are not evenly distributed. Points are densely packed near the camera and sparse at distance. Therefore, we further use query-guided feature sampling to compensate for the above shortcomings.
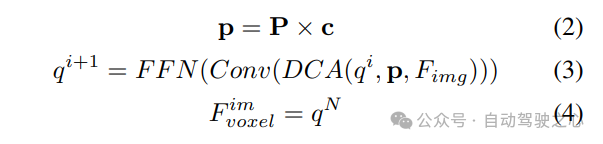
Compared to points generated from LSS, voxel queries are uniformly distributed in 3D space, and they are learned from the statistical properties of all training samples, which is consistent with The depth prior information used in LSS is irrelevant. Therefore, and complement each other, connect them as the output features of the view transformation module:
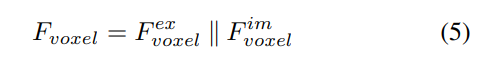
2) Local and global feature extraction and fusion
Given input voxel features, first overlay the features on the Z-axis and use convolutional layers to reduce channels to obtain BEV features:
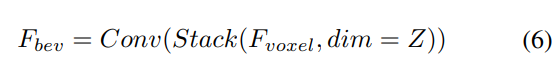
Then, The model is divided into two parallel branches for feature extraction and enhancement. Local feature extraction, global feature extraction, and the final cross-representation feature interaction! As shown in Figure 1(b).
3) Loss function and detection head
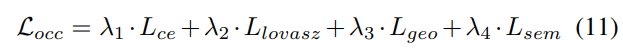
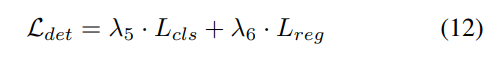
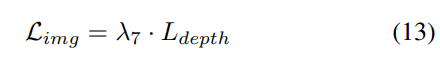
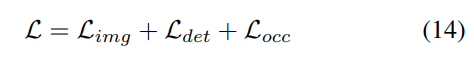
Progressive loss weight adjustment strategy. In practice, it is found that directly incorporating the above losses often causes the training process to fail and the network to fail to converge. In the early stages of training, voxel features Fvoxel are randomly distributed, and supervision in the occupancy head and detection head contributes less than other losses in convergence. At the same time, loss items such as the classification loss Lcls in the detection task are very large and dominate the training process, making it difficult to optimize the model. To overcome this problem, a progressive loss weight adjustment strategy is proposed to dynamically adjust the loss weight. Specifically, the control parameter δ is added to the non-image-level losses (i.e., occupancy loss and detection loss) to adjust the loss weight in different training epochs. The control weight δ is set to a small value Vmin at the beginning and gradually increases to Vmax over N training epochs:
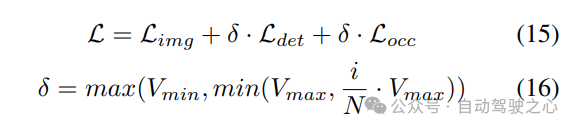
4) Combined Occ- Det spatial data enhancement
In 3D detection tasks, in addition to common image-level data enhancement, spatial-level data enhancement is also effective in improving model performance. However, applying spatial level enhancement in occupancy tasks is not straightforward. When we apply data augmentation (such as random scaling and rotation) to discrete occupancy labels, it is difficult to determine the resulting voxel semantics. Therefore, existing methods only apply simple spatial augmentation such as random flipping in occupancy tasks.
To solve this problem, UniVision proposes a joint Occ-Det spatial data enhancement to allow simultaneous enhancement of 3D detection tasks and occupancy tasks in the framework. Since the 3D box labels are continuous values and the enhanced 3D box can be directly calculated for training, the enhancement method in BEVDet is followed for detection. Although occupancy labels are discrete and difficult to manipulate, voxel features can be treated as continuous and can be processed through operations such as sampling and interpolation. It is therefore recommended to transform voxel features instead of directly operating on occupancy labels for data augmentation.
Specifically, spatial data augmentation is first sampled and the corresponding 3D transformation matrix is calculated. For the occupancy labels and their voxel indices , we calculate their three-dimensional coordinates. Then, apply and normalize it to obtain the voxel indices in the enhanced voxel feature :
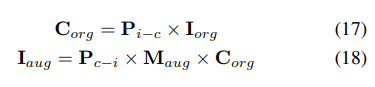
Experiment Comparison of results
Used multiple data sets for verification, NuScenes LiDAR Segmentation, NuScenes 3D Object Detection, OpenOccupancy and Occ3D.
NuScenes LiDAR Segmentation: According to the recent OccFormer and TPVFormer, camera images are used as input for the lidar segmentation task, and the lidar data is only used to provide 3D locations for querying the output features. Use mIoU as the evaluation metric.
NuScenes 3D Object Detection: For detection tasks, use the official metric of nuScenes, the nuScene Detection Score (NDS), which is the weighted sum of average mAP and several metrics, including average translation error (ATE), average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE) and Average Attribute Error (AAE).
OpenOccupancy: The OpenOccupancy benchmark is based on the nuScenes dataset and provides semantic occupancy labels at 512×512×40 resolution. The labeled classes are the same as those in the lidar segmentation task, using mIoU as the evaluation metric!
Occ3D: The Occ3D benchmark is based on the nuScenes dataset and provides semantic occupancy labels at 200×200×16 resolution. Occ3D further provides visible masks for training and evaluation. The labeled classes are the same as those in the lidar segmentation task, using mIoU as the evaluation metric!
1) Nuscenes LiDAR segmentation
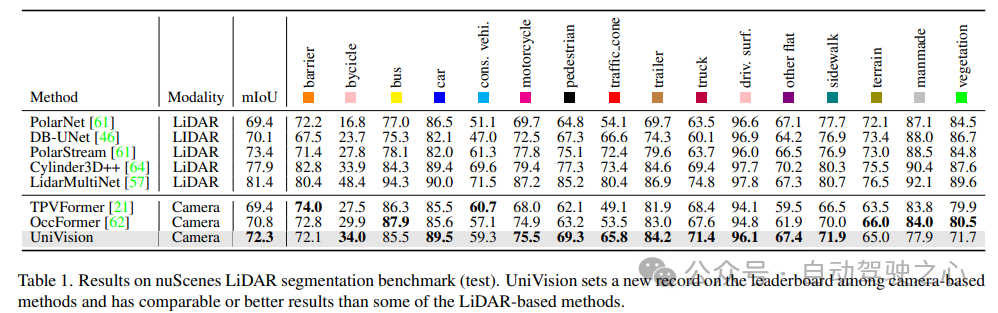
Table 1 shows the results of the nuScenes LiDAR segmentation benchmark. UniVision significantly outperforms the state-of-the-art vision-based method OccFormer by 1.5% mIoU and sets a new record for vision-based models on the leaderboard. Notably, UniVision also outperforms some lidar-based models such as PolarNe and DB-UNet.
2) NuScenes 3D object detection task
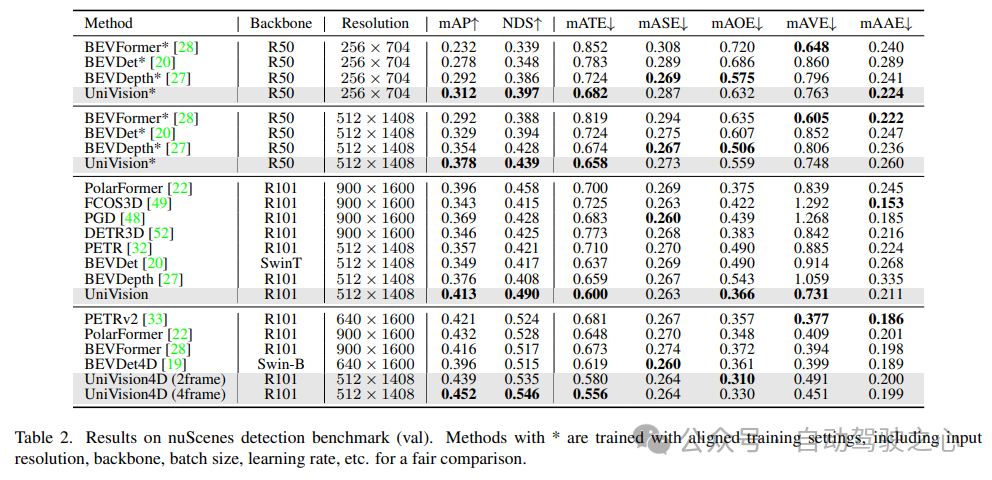
As shown in Table 2, when using the same training settings for fair comparison , UniVision was shown to outperform other methods. Compared with BEVDepth at 512×1408 image resolution, UniVision achieves gains of 2.4% and 1.1% in mAP and NDS respectively. When the model is scaled up and UniVision is combined with temporal input, it further outperforms SOTA-based temporal detectors by significant margins. UniVision achieves this with a smaller input resolution, and it does not use CBGS.
3) Comparison of OpenOccupancy results
The results of the OpenOccupancy benchmark test are shown in Table 3. UniVision significantly outperforms recent vision-based occupancy methods including MonoScene, TPVFormer, and C-CONet in terms of mIoU by 7.3%, 6.5%, and 1.5%, respectively. Furthermore, UniVision outperforms some lidar-based methods such as LMSCNet and JS3C-Net.
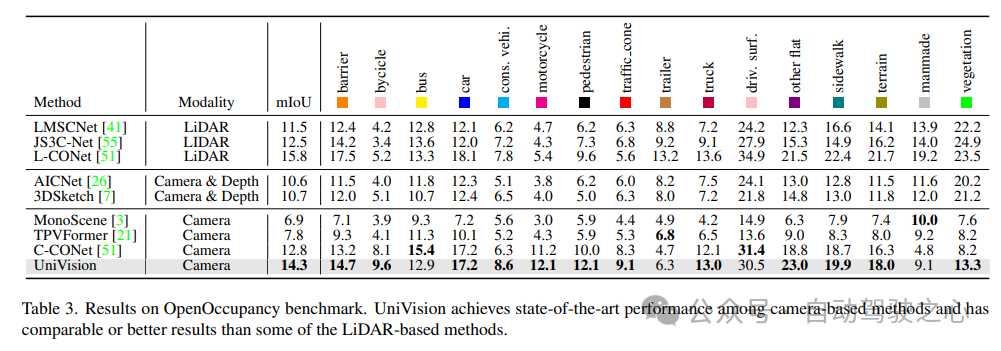
4) Occ3D experimental results
Table 4 lists the results of the Occ3D benchmark test. UniVision significantly outperforms recent vision-based methods in terms of mIoU under different input image resolutions, by more than 2.7% and 1.8% respectively. It is worth noting that BEVFormer and BEVDet-stereo load pre-trained weights and use temporal inputs in inference, while UniVision does not use them but still achieves better performance.
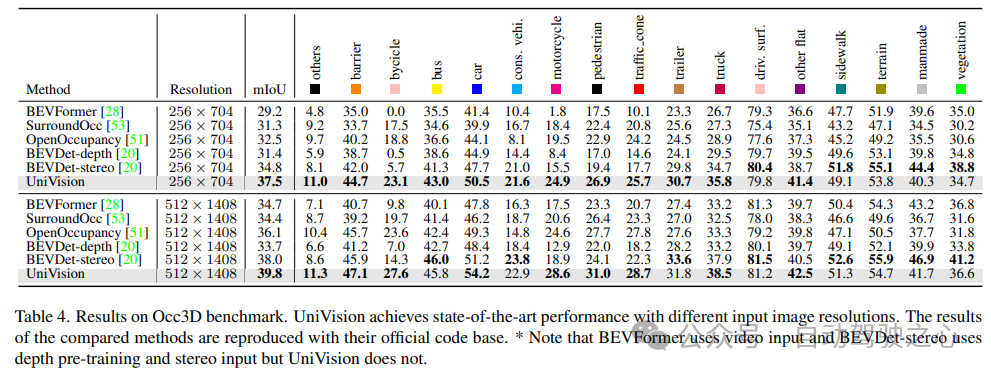
5) Effectiveness of components in detection tasks
Ablation studies on detection tasks are shown in Table 5. When the BEV-based global feature extraction branch is inserted into the baseline model, the performance improves by 1.7% mAP and 3.0% NDS. When the voxel-based occupancy task is added to the detector as an auxiliary task, the model’s mAP gain increases by 1.6%. When cross-representation interactions are explicitly introduced from voxel features, the model achieves the best performance, improving mAP and NDS by 3.5% and 4.2%, respectively, compared to the baseline;
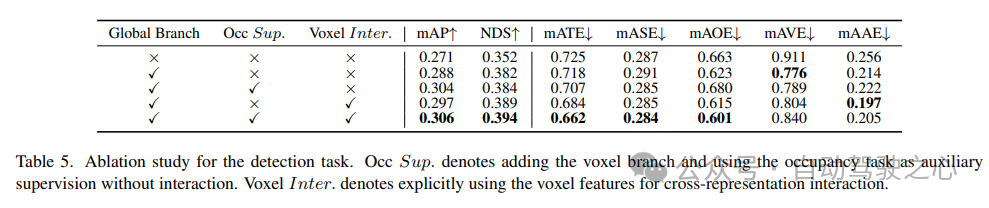
6) Effectiveness of components in the occupancy task
Ablation studies for the occupancy task are shown in Table 6. The voxel-based local feature extraction network brings an improvement of 1.96% mIoU gain to the baseline model. When the detection task is introduced as an auxiliary supervision signal, the model performance improves by 0.4% mIoU.

7) Others
Table 5 and Table 6 show that in the UniVision framework, detection tasks and occupancy tasks complement each other of. For detection tasks, occupancy supervision can improve mAP and mATE metrics, indicating that voxel semantic learning effectively improves the detector's perception of object geometry, i.e., centrality and scale. For the occupancy task, detection supervision significantly improves the performance of the foreground category (i.e., the detection category), resulting in an overall improvement.
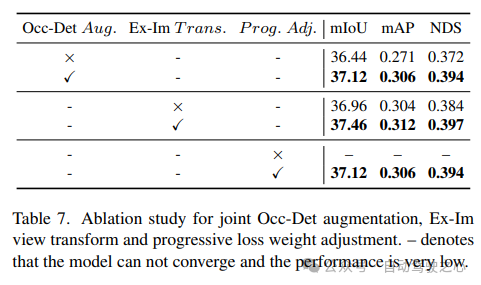
The effectiveness of the combined Occ-Det spatial enhancement, Ex-Im view conversion module and progressive loss weight adjustment strategy is shown in Table 7. With the proposed spatial augmentation and the proposed view transformation module, it shows significant improvements in detection tasks and occupancy tasks on mIoU, mAP and NDS metrics. The loss weight adjustment strategy can effectively train the multi-task framework. Without this, the training of the unified framework cannot converge and the performance is very low.
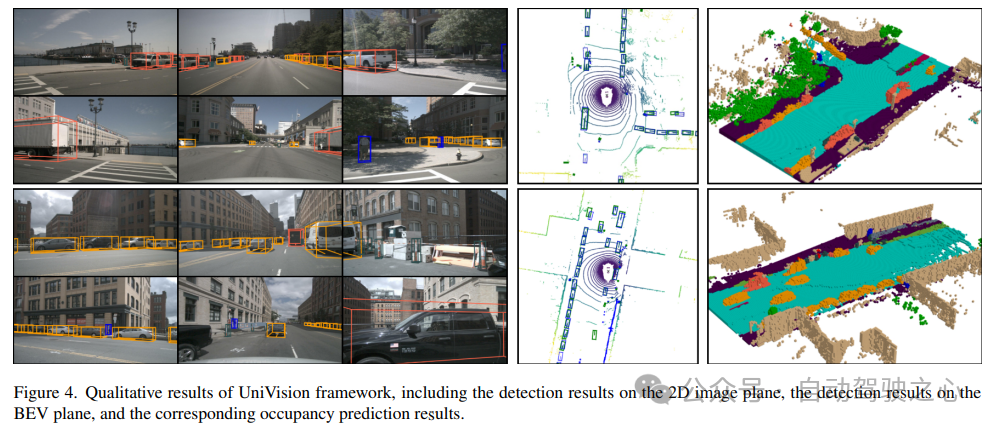
Reference
Paper link: https://arxiv.org/pdf/2401.06994.pdf
Paper title: UniVision: A Unified Framework for Vision-Centric 3D Perception
The above is the detailed content of Unparalleled UniVision: BEV detection and Occ joint unified framework, dual SOTA!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
