

Stunning! ! ! Tesla end-to-end demonstration video analysis

A user posted a video of Tesla FSD v12 on the Internet, and someone moved it to site B:
https://www.bilibili.com/video/BV1Z6421M797www.bilibili .com/video/BV1Z6421M797
This time it happens to be a purely visually complex scene: it rains and there is water on the ground, and various patterns are reflected on the water, which may produce some strange visual effects. Tesla did not hold an AI Day event last year, allegedly because competitors often provoked their slides, so it simply canceled it. In the absence of details, watching the video provides a glimpse into some of the end-to-end features. Next, let’s analyze some of the interesting points.
01:57, mistakenly detected that the car door was open, and took a large detour:

It’s not a big problem here, there is a relatively large space on the left, so It doesn’t matter if you go around a little longer.
02:09, misdetection of occ resulted in almost stopping:

The pedestrians have left and we can start moving forward. However, there was a lot of standing water on the ground, reflecting the image of the object, which could lead to false detections, so we stopped and waited for a while before moving on.
04:40, the close-range cut-in vehicle was missed


#The very close-range reversing cut-in vehicle on the left side was missed. But planning does not seem to give the intention of starting. This reflects a major advantage of end-to-end: the results of upstream errors do not necessarily lead to wrong driving behaviors. We will see more similar examples later.
05:37 False detection of occ


This may also be caused by the accumulation of water on the ground. This result was accepted end-to-end, and left and right Turn the steering wheel randomly, sometimes to the left and sometimes to the right.
05:48, misdetection of occ at close distances on the left and right
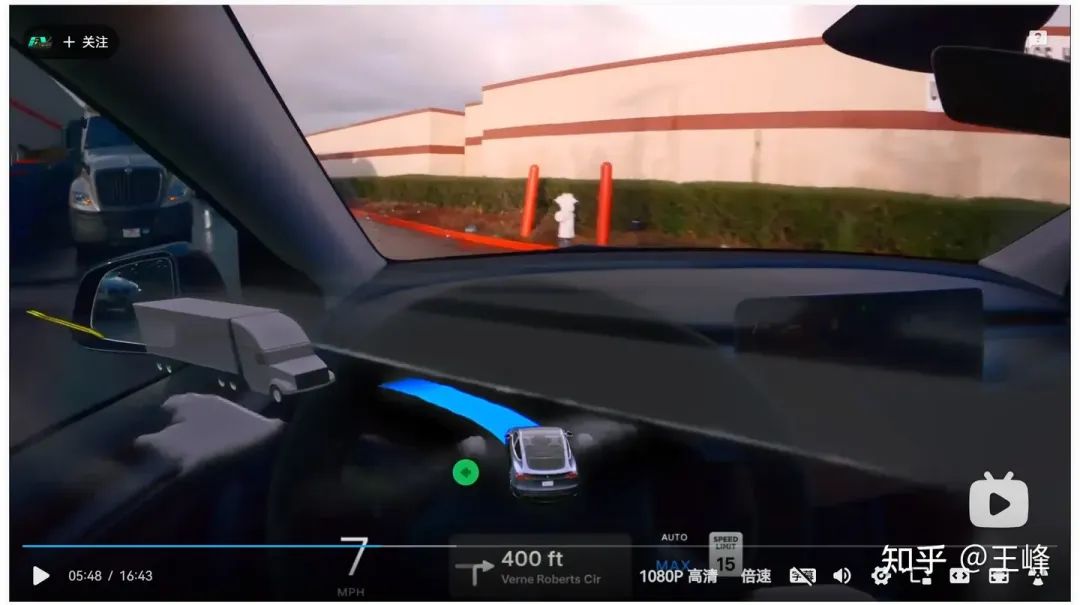
There are false detections of occ at very close positions on the left and right. If you still write according to the rules, it may be possible. You have to report it for takeover (not necessarily, after all, it is not on the driving track). Here, the two OCCs are ignored from end to end and continue driving.
06:57, False detection of a pedestrian at close range directly in front
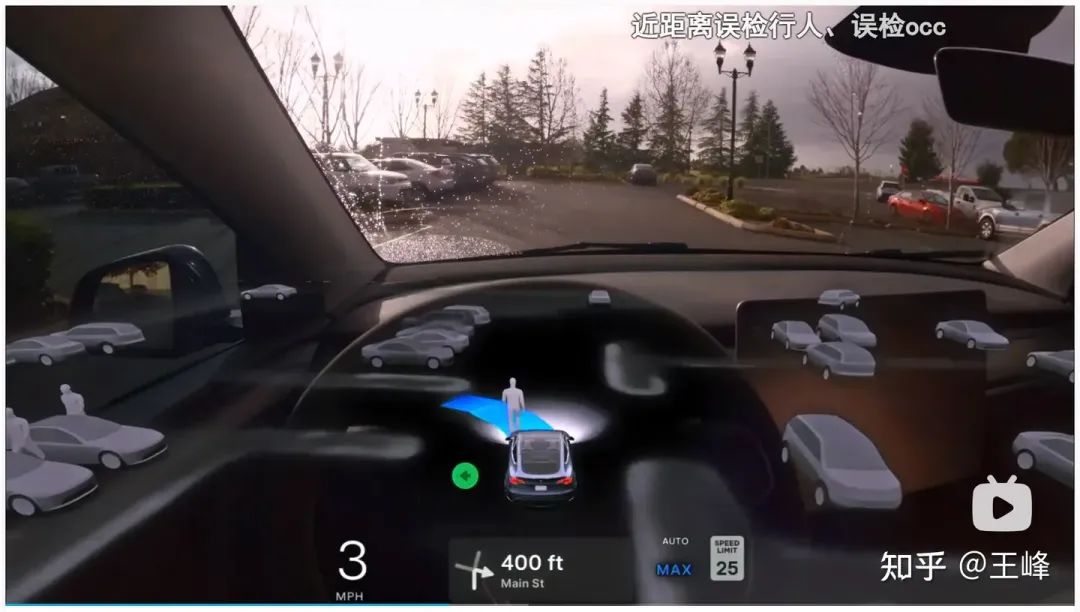
This is really awesome, a pedestrian appears on the face, all rules-based The control system will definitely issue a sudden brake alarm at this time, but the end-to-end model does not recognize the upstream results and continues to drive as usual.
14 points: Wandering around in a private parking lot and unable to get out
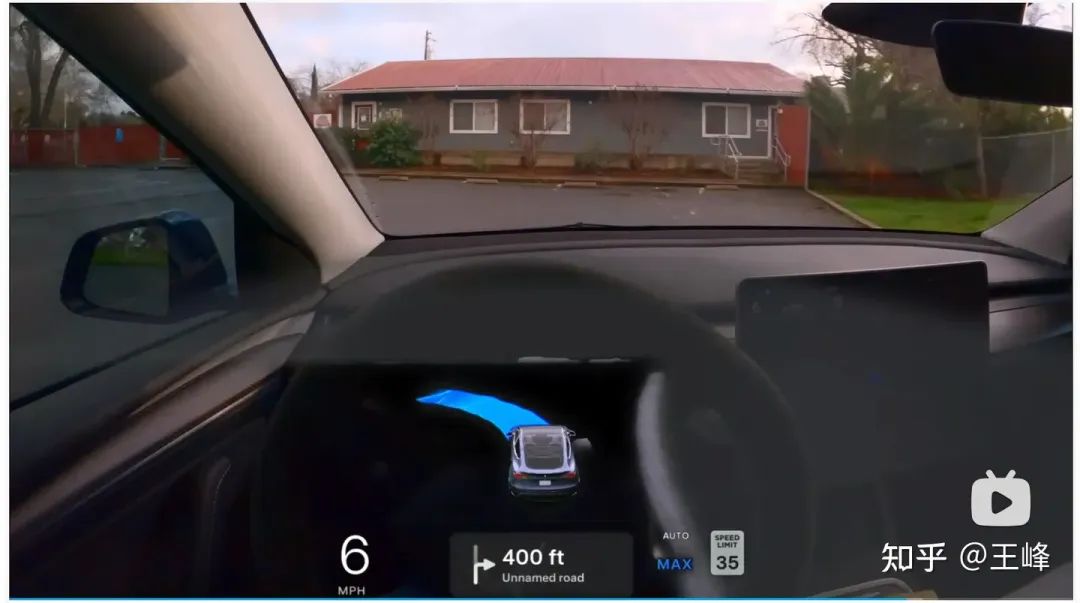
#This may be a problem with the BEV's insufficient sensing distance, and it has not been found for a long time. Exit and circle around a parking lot. .
The other clips are all about driving on the main road. On the main road, the performance of FSD v12 is very smooth and there is no big problem. Especially at night, the detection of lane lines is also very stable, but I think it is a big problem. Some manufacturers can also achieve this level, so I won’t mention them here.
Looking at the section of the parking lot alone, if you don’t look at the upstream results, except for the misdetection of the front OCC that caused the steering wheel to turn left and right, the trajectory of FSD v12 is still relatively smooth, and even if there are errors, it is not stuck. living situation. In such a scene with pedestrians, irregularly moving obstacles (trolleys), and water on the ground, the performance is indeed okay.
Tesla still uses multi-tasking end-to-end with intermediate module supervision, so the front end can still display the results of obj det and occ. However, the end-to-end regulation does not necessarily accept the upstream results. A missed detection at a close range may not necessarily result in a start and a crash, and a misdetection at a close range may not necessarily cause the vehicle to stop. All results are input into the PNC for comprehensive judgment. . This is indeed an interesting point. What is certain is that Musk is not lying. This is indeed the performance of an end-to-end system.
The above is the detailed content of Stunning! ! ! Tesla end-to-end demonstration video analysis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 Tesla finally takes action! Will self-driving taxis be unveiled soon? !
Apr 08, 2024 pm 05:49 PM
Tesla finally takes action! Will self-driving taxis be unveiled soon? !
Apr 08, 2024 pm 05:49 PM
According to news on April 8, Tesla CEO Elon Musk recently revealed that Tesla is committed to developing self-driving car technology. The highly anticipated unmanned self-driving taxi Robotaxi will be launched on August 8. Official debut. The data editor learned that Musk's statement on Previously, Reuters reported that Tesla’s plan to drive cars would focus on the production of Robotaxi. However, Musk refuted this, accusing Reuters of having canceled plans to develop low-cost cars and once again publishing false reports, while making it clear that low-cost cars Model 2 and Robotax
 Tesla Dojo supercomputing debut, Musk: The computing power of AI training by the end of the year will be approximately equal to 8,000 NVIDIA H100 GPUs
Jul 24, 2024 am 10:38 AM
Tesla Dojo supercomputing debut, Musk: The computing power of AI training by the end of the year will be approximately equal to 8,000 NVIDIA H100 GPUs
Jul 24, 2024 am 10:38 AM
According to news from this website on July 24, Tesla CEO Elon Musk (Elon Musk) stated in today’s earnings conference call that the company is about to complete the largest artificial intelligence training cluster to date, which will be equipped with 2 Thousands of NVIDIA H100 GPUs. Musk also told investors on the company's earnings call that Tesla would work on developing its Dojo supercomputer because GPUs from Nvidia are expensive. This site translated part of Musk's speech as follows: The road to competing with NVIDIA through Dojo is difficult, but I think we have no choice. We are now over-reliant on NVIDIA. From NVIDIA's perspective, they will inevitably increase the price of GPUs to a level that the market can bear, but
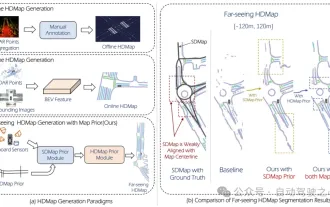 Mass production killer! P-Mapnet: Using the low-precision map SDMap prior, the mapping performance is violently improved by nearly 20 points!
Mar 28, 2024 pm 02:36 PM
Mass production killer! P-Mapnet: Using the low-precision map SDMap prior, the mapping performance is violently improved by nearly 20 points!
Mar 28, 2024 pm 02:36 PM
As written above, one of the algorithms used by current autonomous driving systems to get rid of dependence on high-precision maps is to take advantage of the fact that the perception performance in long-distance ranges is still poor. To this end, we propose P-MapNet, where the “P” focuses on fusing map priors to improve model performance. Specifically, we exploit the prior information in SDMap and HDMap: on the one hand, we extract weakly aligned SDMap data from OpenStreetMap and encode it into independent terms to support the input. There is a problem of weak alignment between the strictly modified input and the actual HD+Map. Our structure based on the Cross-attention mechanism can adaptively focus on the SDMap skeleton and bring significant performance improvements;
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
