
 Technology peripherals
AI
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Technology peripherals
AI
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?

The paper for Stable Diffusion 3 is finally here!
This model was released two weeks ago and uses the same DiT (Diffusion Transformer) architecture as Sora. It caused quite a stir upon release.
Compared with the previous version, the quality of images generated by Stable Diffusion 3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. Condition.
Stability AI pointed out that Stable Diffusion 3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly lowering the threshold for using large AI models.
In a newly released paper, Stability AI said that in human preference-based evaluations, Stable Diffusion 3 outperformed current state-of-the-art text-to-image generation systems such as DALL・E 3. Midjourney v6 and Ideogram v1. Soon, they will make the experimental data, code, and model weights of the study publicly available.
In the paper, Stability AI revealed more details about Stable Diffusion 3.

- ##Paper title: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- Paper link: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable Diffusion 3 Paper.pdf
Architectural details
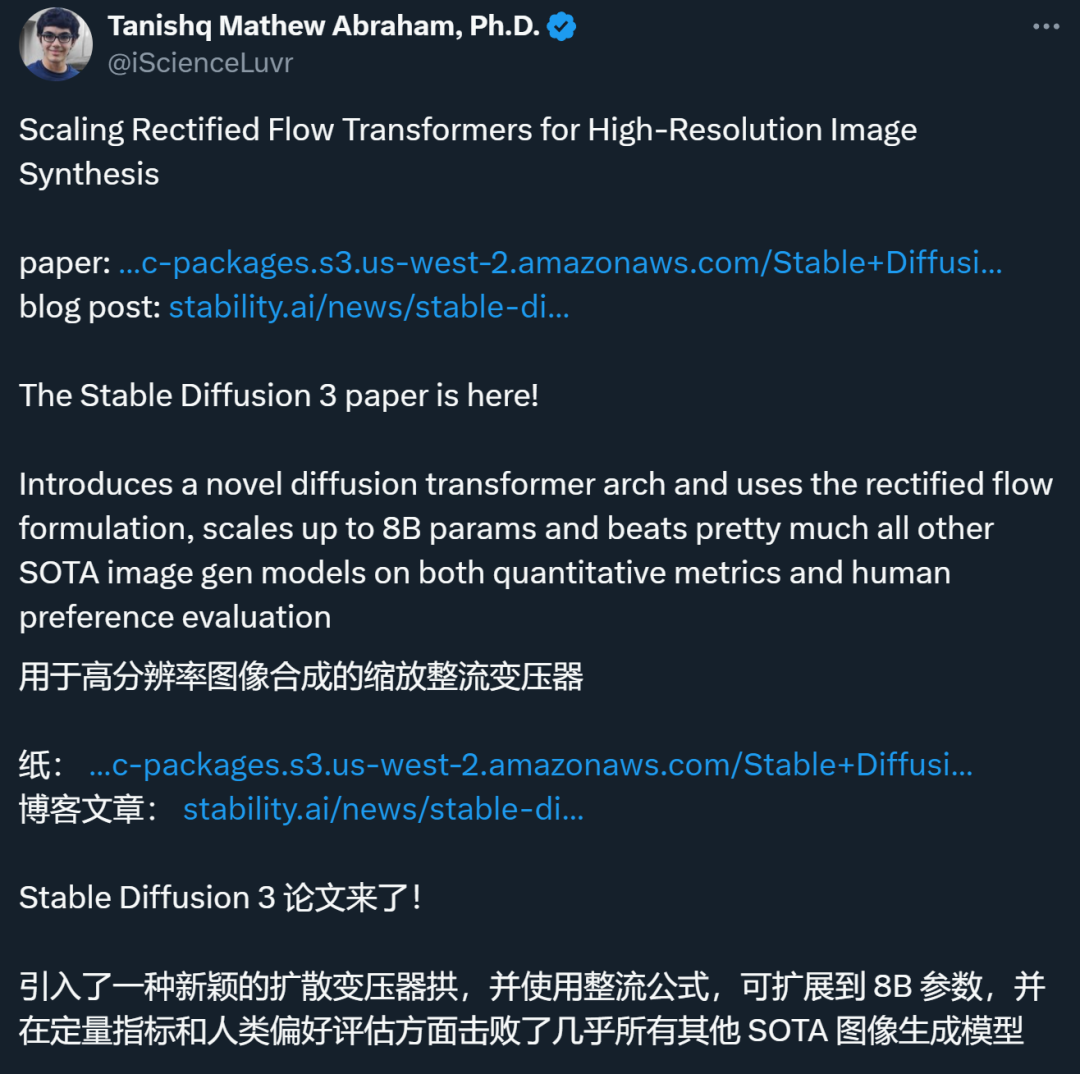
For text-to-image generation, the Stable Diffusion 3 model must consider both text and image modes. Therefore, the authors of the paper call this new architecture MMDiT, referring to its ability to handle multiple modalities. As with previous versions of Stable Diffusion, the authors use pre-trained models to derive suitable text and image representations. Specifically, they used three different text embedding models—two CLIP models and T5—to encode text representations, and an improved autoencoding model to encode image tokens.
Stable Diffusion 3 model architecture.
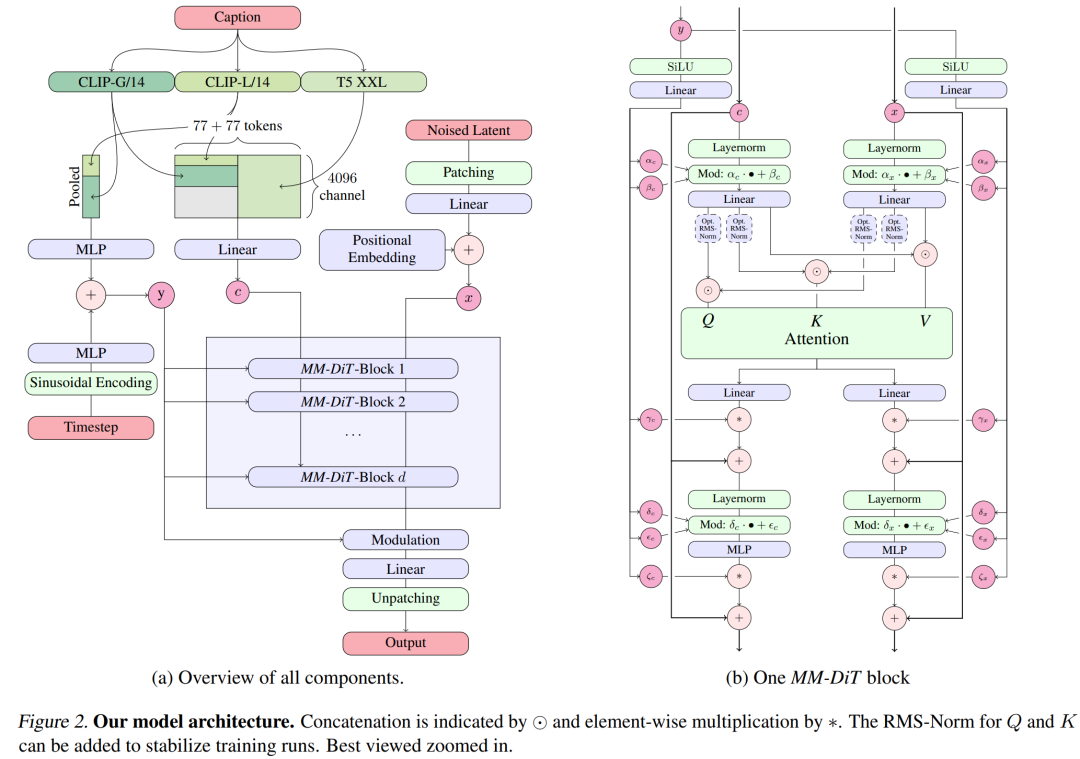
Improved multimodal diffusion transformer: MMDiT block.
The SD3 architecture is based on DiT proposed by Sora core R&D member William Peebles and Xie Saining, assistant professor of computer science at New York University. Since text embedding and image embedding are conceptually very different, the authors of SD3 use two different sets of weights for the two modalities. As shown in the figure above, this is equivalent to setting up two independent transformers for each modality, but combining the sequences of the two modalities for attention operations, so that both representations can work in their own space, Another representation is also taken into account.
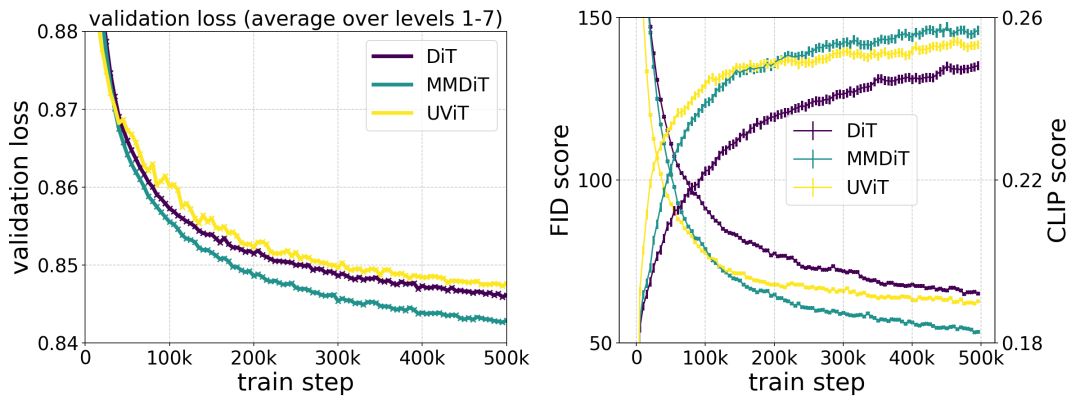
The author's proposed MMDiT architecture outperforms mature textual frameworks such as UViT and DiT when measuring visual fidelity and text alignment during training. to the image backbone.
In this way, information can flow between image and text tokens, thereby improving the overall understanding of the model and improving the typography of the generated output. As discussed in the paper, this architecture is also easily extensible to multiple modalities such as video.

Thanks to Stable Diffusion 3’s improved prompt following capabilities, the new model has the ability to produce images that focus on a variety of different themes and qualities, At the same time, it can also handle the style of the image itself with a high degree of flexibility.

Improve Rectified Flow through re-weighting
Stable Diffusion 3 uses the Rectified Flow (RF) formula. During the training process, Data and noise are connected in a linear trajectory. This makes the inference path straighter, thus reducing sampling steps. In addition, the authors also introduce a new trajectory sampling scheme during the training process. They hypothesized that the middle part of the trajectory would pose a more challenging prediction task, so the scheme gave more weight to the middle part of the trajectory. They compared using multiple datasets, metrics and sampler settings and tested their proposed method against 60 other diffusion trajectories such as LDM, EDM and ADM. The results show that while the performance of previous RF formulations improves with few sampling steps, their relative performance decreases as the number of steps increases. In contrast, the reweighted RF variant proposed by the authors consistently improves performance.
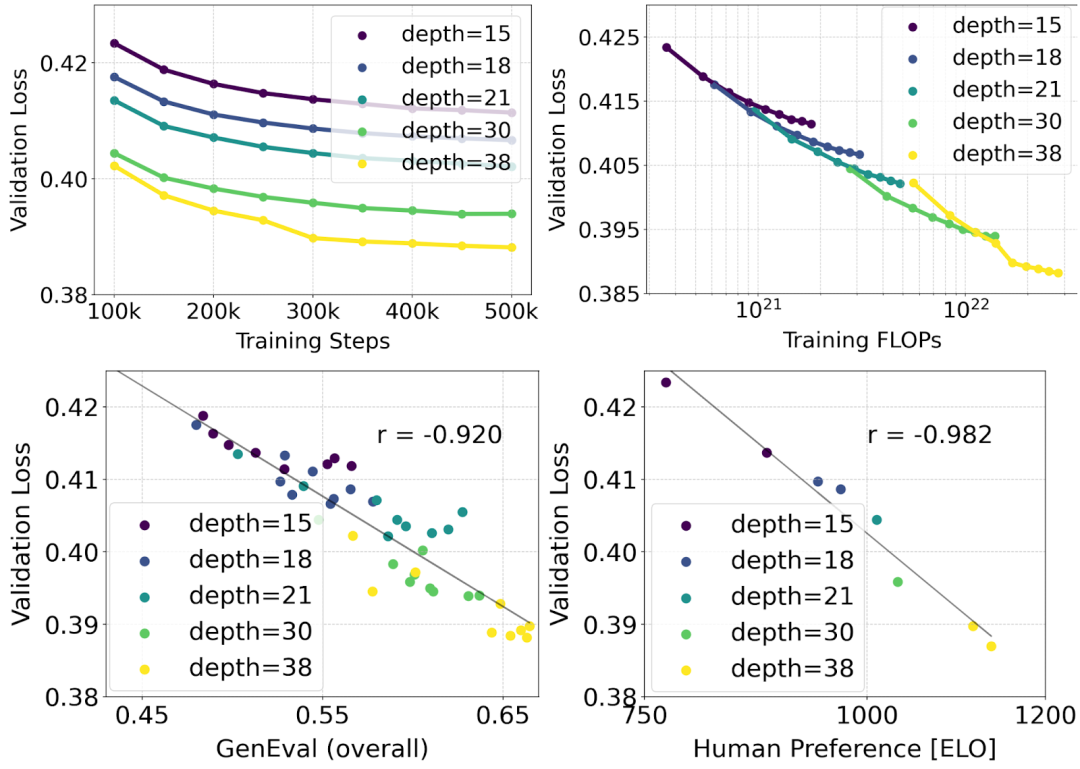
Extended Rectified Flow Transformer model
The author uses the reweighted Rectified Flow formula and MMDiT backbone pair Text-to-image synthesis is studied in scaling. They trained models ranging from 15 blocks with 450M parameters to 38 blocks with 8B parameters and observed that the validation loss decreased smoothly with increasing model size and training steps (first part of the figure above OK). To examine whether this translated into meaningful improvements in model output, the authors also evaluated the automatic image alignment metric (GenEval) and the human preference score (ELO) (second row above). The results show a strong correlation between these metrics and validation loss, suggesting that the latter is a good predictor of the overall performance of the model. Furthermore, the scaling trend shows no signs of saturation, making the authors optimistic about continuing to improve model performance in the future.
Flexible text encoder
By removing memory intensive 4.7B parameter T5 text encoder for inference, SD3 memory Demand can be significantly reduced with minimal performance loss. As shown, removing this text encoder has no impact on visual aesthetics (50% win rate without T5) and only slightly reduces text consistency (46% win rate). However, the authors recommend adding T5 when generating written text to fully utilize the performance of SD3, because they observed that without adding T5, the performance of generating typesetting dropped even more (win rate 38%), as shown in the following figure:

#Removing T5 for inference will only result in a significant decrease in performance when presenting very complex prompts involving many details or large amounts of written text. The image above shows three random samples of each example.
Model performance
The author compared the output image of Stable Diffusion 3 with various other open source models (including SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 and Pixart-α) as well as closed-source models such as DALL-E 3, Midjourney v6 and Ideogram v1 were compared to evaluate performance based on human feedback. In these tests, human evaluators are given examples of output from each model and judged on how well the model output follows the context of the prompt given (prompt following), how well the text is rendered according to the prompt (typography), and which image Images with higher visual aesthetics are selected for the best results.
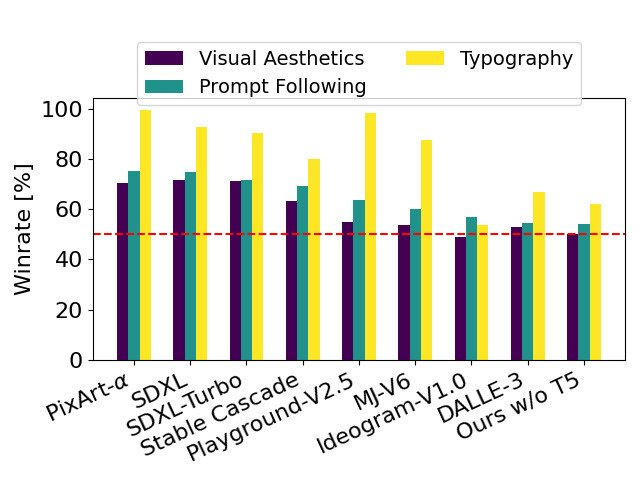
#Using SD3 as the benchmark, this chart outlines its win rate based on human evaluation of visual aesthetics, prompt following, and text layout.
From the test results, the author found that Stable Diffusion 3 is equivalent to or even better than the current state-of-the-art text-to-image generation systems in all the above aspects.
In early unoptimized inference testing on consumer hardware, the largest 8B parameter SD3 model fit the RTX 4090's 24GB VRAM, using 50 sampling steps to generate a resolution of 1024x1024 Image takes 34 seconds.

Additionally, at initial release, Stable Diffusion 3 will be available in multiple variants, ranging from 800m to 8B parametric models to further eliminate hardware barriers.


Please refer to the original paper for more details.
Reference link: https://stability.ai/news/stable-diffusion-3-research-paper
The above is the detailed content of The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1242
24
14
1423
52
1317
25
1268
29
1242
24

 How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
How to understand DMA operations in C?
Apr 28, 2025 pm 10:09 PM
DMA in C refers to DirectMemoryAccess, a direct memory access technology, allowing hardware devices to directly transmit data to memory without CPU intervention. 1) DMA operation is highly dependent on hardware devices and drivers, and the implementation method varies from system to system. 2) Direct access to memory may bring security risks, and the correctness and security of the code must be ensured. 3) DMA can improve performance, but improper use may lead to degradation of system performance. Through practice and learning, we can master the skills of using DMA and maximize its effectiveness in scenarios such as high-speed data transmission and real-time signal processing.
 How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
How to use the chrono library in C?
Apr 28, 2025 pm 10:18 PM
Using the chrono library in C can allow you to control time and time intervals more accurately. Let's explore the charm of this library. C's chrono library is part of the standard library, which provides a modern way to deal with time and time intervals. For programmers who have suffered from time.h and ctime, chrono is undoubtedly a boon. It not only improves the readability and maintainability of the code, but also provides higher accuracy and flexibility. Let's start with the basics. The chrono library mainly includes the following key components: std::chrono::system_clock: represents the system clock, used to obtain the current time. std::chron
 Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
Quantitative Exchange Ranking 2025 Top 10 Recommendations for Digital Currency Quantitative Trading APPs
Apr 30, 2025 pm 07:24 PM
The built-in quantization tools on the exchange include: 1. Binance: Provides Binance Futures quantitative module, low handling fees, and supports AI-assisted transactions. 2. OKX (Ouyi): Supports multi-account management and intelligent order routing, and provides institutional-level risk control. The independent quantitative strategy platforms include: 3. 3Commas: drag-and-drop strategy generator, suitable for multi-platform hedging arbitrage. 4. Quadency: Professional-level algorithm strategy library, supporting customized risk thresholds. 5. Pionex: Built-in 16 preset strategy, low transaction fee. Vertical domain tools include: 6. Cryptohopper: cloud-based quantitative platform, supporting 150 technical indicators. 7. Bitsgap:
 How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
How to handle high DPI display in C?
Apr 28, 2025 pm 09:57 PM
Handling high DPI display in C can be achieved through the following steps: 1) Understand DPI and scaling, use the operating system API to obtain DPI information and adjust the graphics output; 2) Handle cross-platform compatibility, use cross-platform graphics libraries such as SDL or Qt; 3) Perform performance optimization, improve performance through cache, hardware acceleration, and dynamic adjustment of the details level; 4) Solve common problems, such as blurred text and interface elements are too small, and solve by correctly applying DPI scaling.
 What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
What is real-time operating system programming in C?
Apr 28, 2025 pm 10:15 PM
C performs well in real-time operating system (RTOS) programming, providing efficient execution efficiency and precise time management. 1) C Meet the needs of RTOS through direct operation of hardware resources and efficient memory management. 2) Using object-oriented features, C can design a flexible task scheduling system. 3) C supports efficient interrupt processing, but dynamic memory allocation and exception processing must be avoided to ensure real-time. 4) Template programming and inline functions help in performance optimization. 5) In practical applications, C can be used to implement an efficient logging system.
 How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
How to use string streams in C?
Apr 28, 2025 pm 09:12 PM
The main steps and precautions for using string streams in C are as follows: 1. Create an output string stream and convert data, such as converting integers into strings. 2. Apply to serialization of complex data structures, such as converting vector into strings. 3. Pay attention to performance issues and avoid frequent use of string streams when processing large amounts of data. You can consider using the append method of std::string. 4. Pay attention to memory management and avoid frequent creation and destruction of string stream objects. You can reuse or use std::stringstream.
 How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
How to measure thread performance in C?
Apr 28, 2025 pm 10:21 PM
Measuring thread performance in C can use the timing tools, performance analysis tools, and custom timers in the standard library. 1. Use the library to measure execution time. 2. Use gprof for performance analysis. The steps include adding the -pg option during compilation, running the program to generate a gmon.out file, and generating a performance report. 3. Use Valgrind's Callgrind module to perform more detailed analysis. The steps include running the program to generate the callgrind.out file and viewing the results using kcachegrind. 4. Custom timers can flexibly measure the execution time of a specific code segment. These methods help to fully understand thread performance and optimize code.
 An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
An efficient way to batch insert data in MySQL
Apr 29, 2025 pm 04:18 PM
Efficient methods for batch inserting data in MySQL include: 1. Using INSERTINTO...VALUES syntax, 2. Using LOADDATAINFILE command, 3. Using transaction processing, 4. Adjust batch size, 5. Disable indexing, 6. Using INSERTIGNORE or INSERT...ONDUPLICATEKEYUPDATE, these methods can significantly improve database operation efficiency.
