
 Technology peripherals
AI
Google releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA
Technology peripherals
AI
Google releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA
Google releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA

The big model that everyone wants is the kind that is truly intelligent...
The Google team will make it Developed a powerful "screen reading" AI.
The researchers call it ScreenAI, a new visual language model for understanding user interfaces and infographics.

Paper address: https://arxiv.org/pdf/2402.04615.pdf
ScreenAI At its core is a new screenshot text representation method that recognizes the type and position of UI elements.
The researchers used the Google language model PaLM 2-S to generate synthetic training data, which was used to train the model to answer questions related to screen information, screen navigation, and screen content summaries. question. It is worth mentioning that this method provides new ideas for improving the performance of the model when handling screen-related tasks.

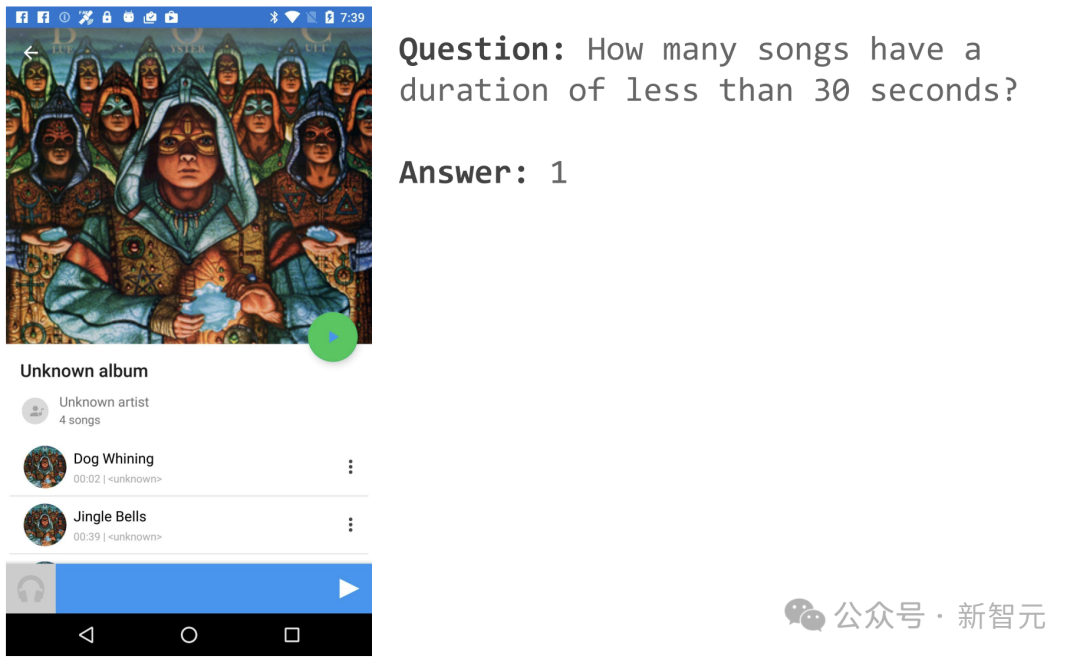
For example, if you open a music APP page, you can ask "How many songs are less than 30 seconds long?"
ScreenAI gave a simple answer: 1.
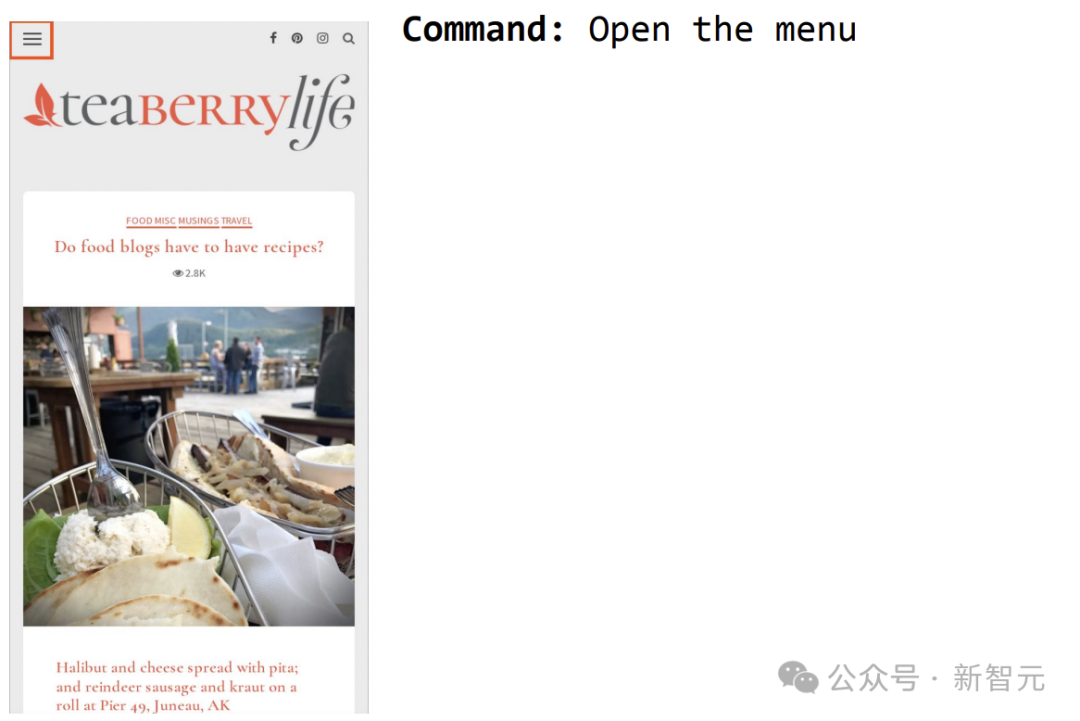
Another example is to command ScreenAI to open the menu and you can select it.
Source of architectural inspiration - PaLI
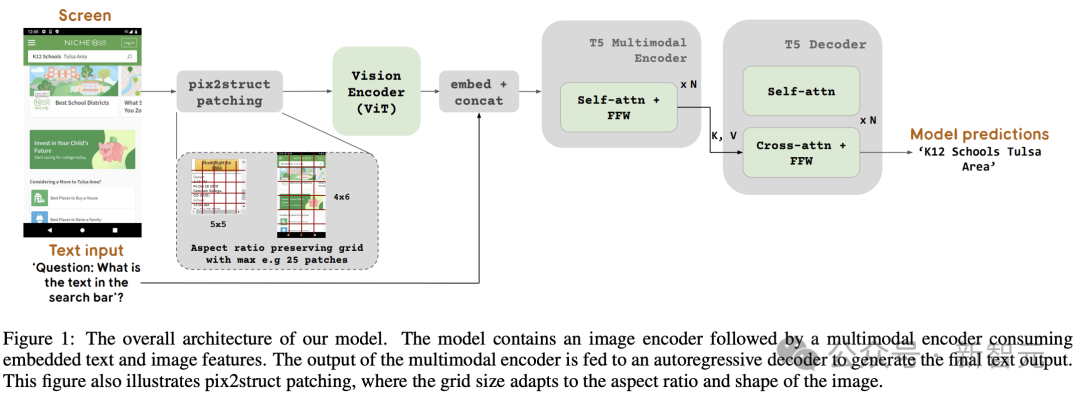
Figure 1 shows the ScreenAI model architecture. The researchers were inspired by the architecture of the PaLI family of models, which consists of a multimodal encoder block.
The encoder block contains a ViT-like visual encoder and an mT5 language encoder consuming image and text input, followed by an autoregressive decoder.
The input image is converted by the visual encoder into a series of embeddings, which are combined with the input text embedding and fed into the mT5 language encoder.
The output of the encoder is passed to the decoder, which produces text output.
This generalized formulation can use the same model architecture to solve various visual and multi-modal tasks. These tasks can be reformulated as text-image (input) to text (output) problems.
Compared to text input, image embeddings form a significant part of the input length to multi-modal encoders.
In short, this model uses an image encoder and a language encoder to extract image and text features, fuse the two and then input them into the decoder to generate text.
This construction method can be widely applied to multi-modal tasks such as image understanding.
In addition, the researchers further extended PaLI’s encoder-decoder architecture to accept various image blocking modes.
The original PaLI architecture only accepts image patches in a fixed grid pattern to process input images. However, researchers in the screen-related field encounter data that spans a wide variety of resolutions and aspect ratios.
In order for a single model to adapt to all screen shapes, it is necessary to use a tiling strategy that works for images of various shapes.
To this end, the Google team borrowed a technology introduced in Pix2Struct, which allows the generation of arbitrary grid-shaped image blocks based on the input image shape and a predefined maximum number of blocks, such as As shown in Figure 1.
This is able to adapt to input images of various formats and aspect ratios without padding or stretching the image to fix its shape, making the model more versatile and able to handle movement simultaneously Image formats for device (i.e. portrait) and desktop (i.e. landscape).
Model configuration
The researchers trained 3 models of different sizes, containing 670M, 2B and 5B parameters.
For the 670M and 2B parameter models, the researchers started with pre-trained unimodal checkpoints for the visual encoder and encoder-decoder language model.
For the 5B parameter model, start from the multi-modal pre-training checkpoint of PaLI-3, where ViT is trained with a UL2-based encoder-decoder language model.
The parameter distribution between the visual and language models can be seen in Table 1.

Automatic data generation
Researchers say that pre-production of model development The training phase largely depends on access to large and diverse data sets.
However, manually labeling extensive data sets is impractical, so the Google team’s strategy is to automatically generate data.
This approach leverages specialized small models, each of which is good at generating and labeling data efficiently and with high accuracy.
Compared to manual annotation, this automated approach is not only efficient and scalable, but also ensures a certain level of data diversity and complexity.
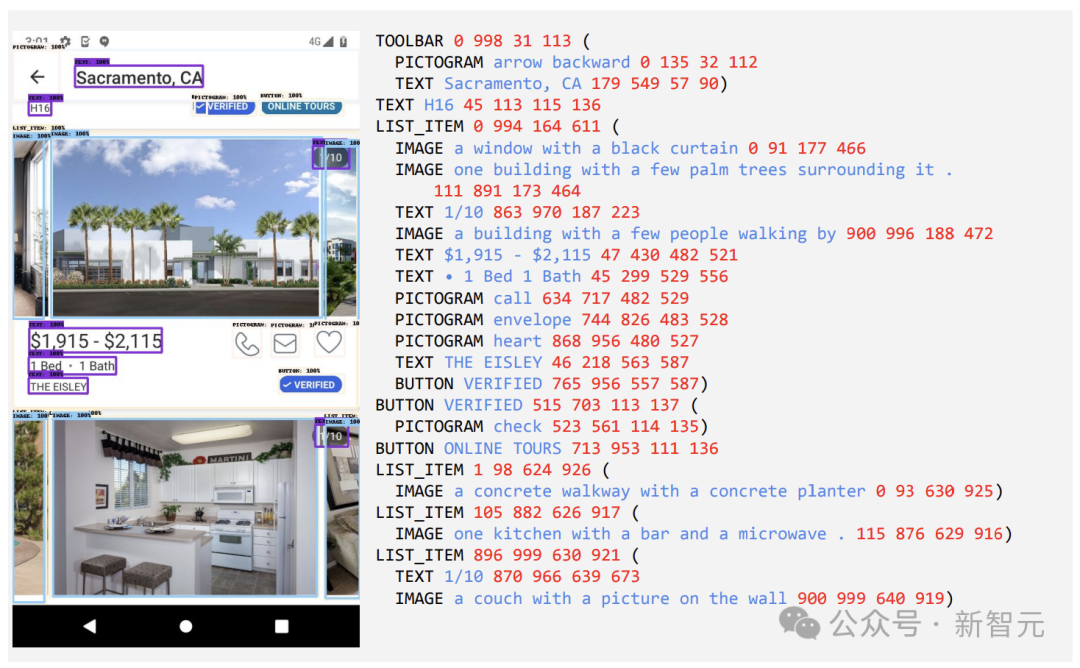
The first step is to give the model a comprehensive understanding of text elements, various screen components, and their overall structure and hierarchy. This fundamental understanding is critical to the model's ability to accurately interpret and interact with a variety of user interfaces.
Here, researchers collected a large number of screenshots from a variety of devices, including desktops, mobile devices, and tablets, by crawling applications and web pages.
These screenshots are then annotated with detailed tags that describe the UI elements, their spatial relationships, and other descriptive information.
In addition, to inject greater diversity into the pre-training data, the researchers also leveraged the power of language models, specifically PaLM 2-S, to generate QA pairs in two stages.
Start by generating the screen mode described previously. The authors then design a prompt containing screen patterns to guide the language model to generate synthetic data.
After a few iterations, a tip can be identified that effectively generates the required tasks, as shown in Appendix C.
#To assess the quality of these generated responses, the researchers performed manual verification on a subset of the data , to ensure that the predetermined quality requirements are met.
This method is described in Figure 2, which greatly improves the depth and breadth of the pre-training data set.
By leveraging the natural language processing capabilities of these models, combined with structured screen patterns, various user interactions and scenarios can be simulated.
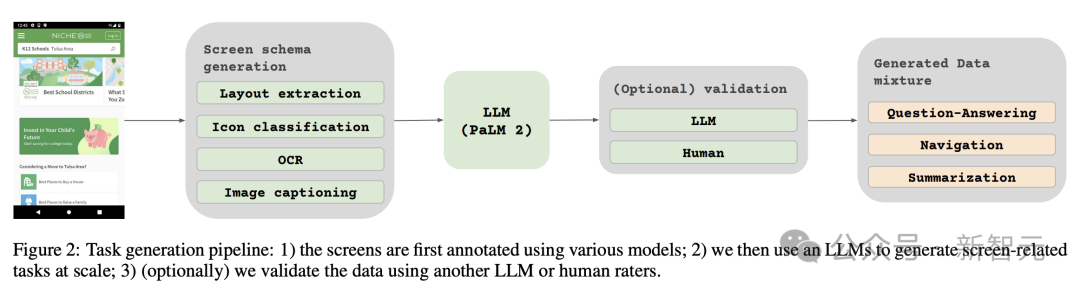
Two sets of different tasks
Next, the researchers defined two different sets of tasks for the model Tasks: an initial set of pre-training tasks and a subsequent set of fine-tuning tasks.
The difference between these two groups mainly lies in two aspects:
- Source of real data: For fine-tuning tasks, labels are evaluated by human evaluators Provide or verify. For pre-training tasks, labels are inferred using self-supervised learning methods or generated using other models.
- Size of the dataset: Usually pre-training tasks contain a large number of samples, therefore, these tasks are used to train the model through a more extended series of steps.
Table 2 shows a summary of all pre-training tasks.
In mixed data, the dataset is weighted proportionally to its size, with the maximum weight allowed for each task.

Incorporate multi-modal sources into multi-task training, from language processing to visual understanding and web page content analysis, enabling the model to effectively handle different scenarios and enhancing its overall Versatility and performance.

Researchers use various tasks and benchmarks to estimate the quality of the model during fine-tuning. Table 3 summarizes these benchmarks, including existing primary screen, infographic, and document comprehension benchmarks.

Experimental results
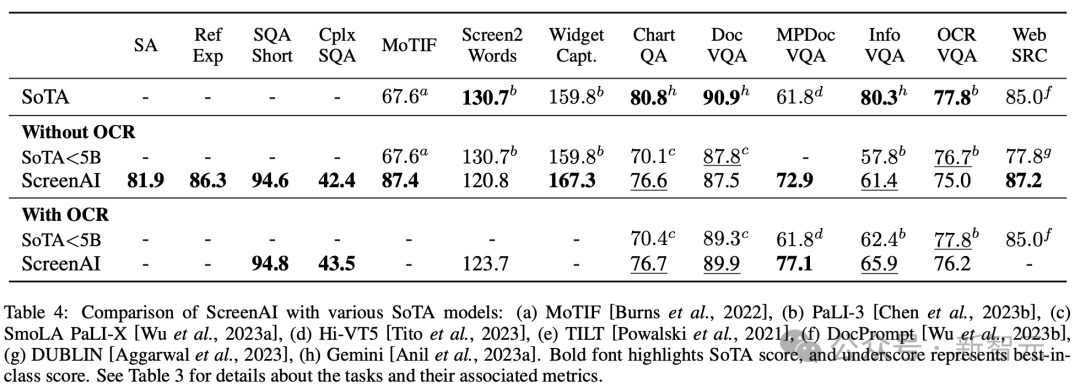
Figure 4 shows the performance of the ScreenAI model and compares it with various The latest SOT results on screen and infographic related tasks are compared.
You can see that ScreenAI has achieved leading performance on different tasks.
In Table 4, the researchers present the results of single-task fine-tuning using OCR data.
For QA tasks, adding OCR can improve performance (e.g. up to 4.5% on Complex ScreenQA, MPDocVQA and InfoVQA).
However, using OCR slightly increases the input length, resulting in slower overall training. It also requires obtaining OCR results at inference time.
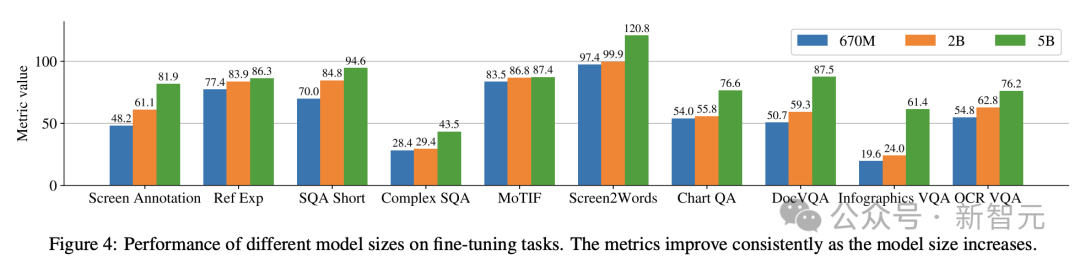
Additionally, the researchers conducted single-task experiments using the following model sizes: 670 million parameters, 2 billion parameters, and 5 billion parameters.
It can be observed in Figure 4 that for all tasks, increasing the model size improves performance, and the improvement at the largest scale has not yet saturated.
For tasks requiring more complex visual text and arithmetic reasoning (such as InfoVQA, ChartQA, and Complex ScreenQA), the improvement between the 2 billion parameter model and the 5 billion parameter model is significantly greater than 6.7 100 million parameter model and 2 billion parameter model.
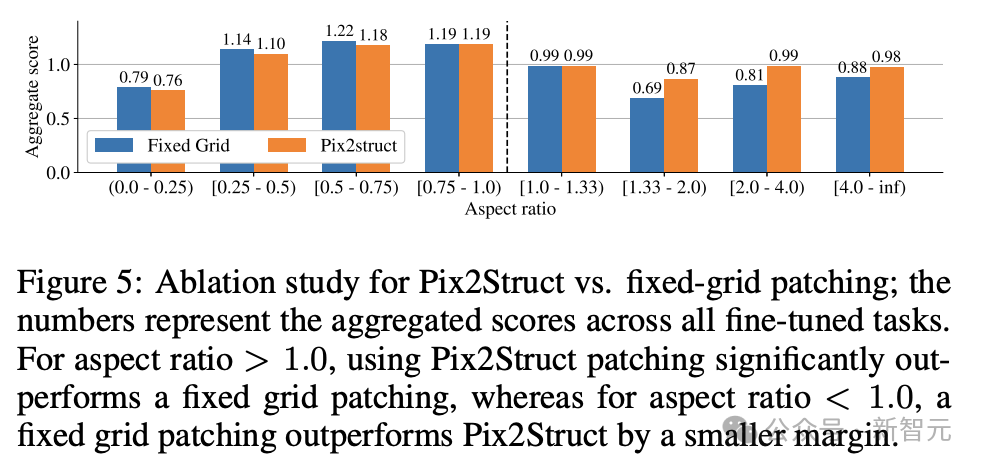
Finally, Figure 5 shows that for images with aspect ratio >1.0 (landscape mode images), the pix2struct segmentation strategy is significantly better than fixed Grid segmentation.
For portrait mode images, the trend is opposite, but fixed grid segmentation is only slightly better.
Given that the researchers wanted the ScreenAI model to work on images with different aspect ratios, they chose to use the pix2struct segmentation strategy.
Google researchers said the ScreenAI model also needs more research on some tasks to scale down to larger models such as GPT-4 and Gemini. model gap.
The above is the detailed content of Google releases the latest 'screen reading' AI! PaLM 2-S automatically generates data, and multiple understanding tasks refresh SOTA. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1379
1379
 52
52

 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
 How to perform digital signature verification with Debian OpenSSL
Apr 13, 2025 am 11:09 AM
How to perform digital signature verification with Debian OpenSSL
Apr 13, 2025 am 11:09 AM
Using OpenSSL for digital signature verification on Debian systems, you can follow these steps: Preparation to install OpenSSL: Make sure your Debian system has OpenSSL installed. If not installed, you can use the following command to install it: sudoaptupdatesudoaptininstallopenssl to obtain the public key: digital signature verification requires the signer's public key. Typically, the public key will be provided in the form of a file, such as public_key.pe
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
 How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
Managing Hadoop logs on Debian, you can follow the following steps and best practices: Log Aggregation Enable log aggregation: Set yarn.log-aggregation-enable to true in the yarn-site.xml file to enable log aggregation. Configure log retention policy: Set yarn.log-aggregation.retain-seconds to define the retention time of the log, such as 172800 seconds (2 days). Specify log storage path: via yarn.n
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
