
 Technology peripherals
AI
'AI Perspective Eye', three-time Marr Prize winner Andrew leads a team to solve the problem of occlusion and completion of any object
Technology peripherals
AI
'AI Perspective Eye', three-time Marr Prize winner Andrew leads a team to solve the problem of occlusion and completion of any object
'AI Perspective Eye', three-time Marr Prize winner Andrew leads a team to solve the problem of occlusion and completion of any object

Occlusion is one of the most basic but still unsolved problems in computer vision, because occlusion means the lack of visual information, but the machine vision system relies on visual information for perception and understanding, and in reality In the world, mutual occlusion between objects is everywhere. The latest work of Andrew Zisserman's team at the VGG Laboratory at the University of Oxford systematically solved the problem of occlusion completion of arbitrary objects and proposed a new and more accurate evaluation data set for this problem. This work was praised by MPI boss Michael Black, the official account of CVPR, the official account of the Department of Computer Science of the University of Southern California, etc. on the X platform. The following is the main content of the paper "Amodal Ground Truth and Completion in the Wild".

- Paper link: https://arxiv.org/pdf/2312.17247.pdf
- Project homepage: https://www.robots.ox.ac.uk/~vgg/research/amodal/
- Code address: https://github.com/Championchess/Amodal-Completion-in-the-Wild
Amodal Segmentation is designed to complete objects that are occluded Part, that is, a shape mask that gives the visible and invisible parts of the object. This task can benefit many downstream tasks: object recognition, target detection, instance segmentation, image editing, 3D reconstruction, video object segmentation, support relationship reasoning between objects, robot manipulation and navigation, because in these tasks it is known that the occluded object is intact The shape will help.

However, how to evaluate the performance of a model for non-modal segmentation in the real world is a difficult problem: although there are a large number of Occluded objects, but how to get the reference standard or non-modal mask of the complete shape of these objects? Previous work has involved manual annotation of non-modal masks, but the reference standards for such annotation are difficult to avoid introducing human errors; there are also works by creating synthetic data sets, such as directly attaching another object to a complete object. Obtain the complete shape of the occluded object, but the pictures obtained in this way are not real picture scenes. Therefore, this work proposes a method through 3D model projection to construct a large-scale real image dataset (MP3D-Amodal) covering multiple object categories and providing amodal masks to accurately evaluate the performance of amodal segmentation. The comparison of different data sets is as follows:
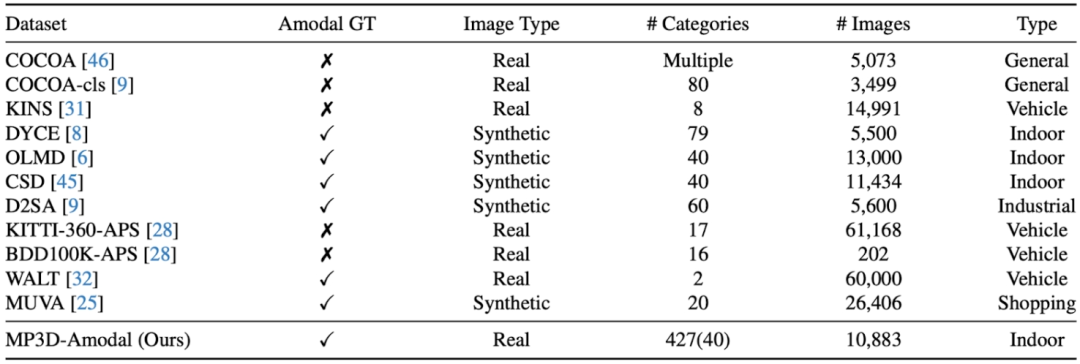
Specifically, taking the MatterPort3D data set as an example, for any real photos and scenes For a three-dimensional structured data set, we can simultaneously project the three-dimensional shapes of all objects in the scene onto the camera to obtain the modal mask of each object (visible shape, because objects are occluding each other), and then project each object in the scene The three-dimensional shape of the object is projected to the camera respectively to obtain the non-modal mask of the object, that is, the complete shape. By comparing the modal mask and the non-modal mask, occluded objects can be picked out.

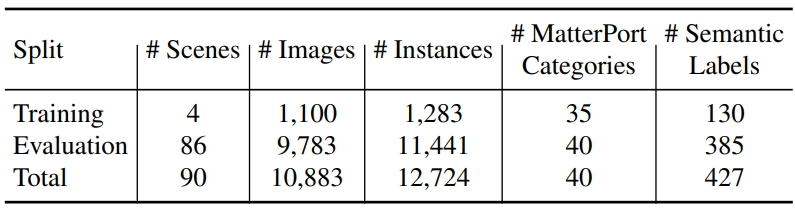
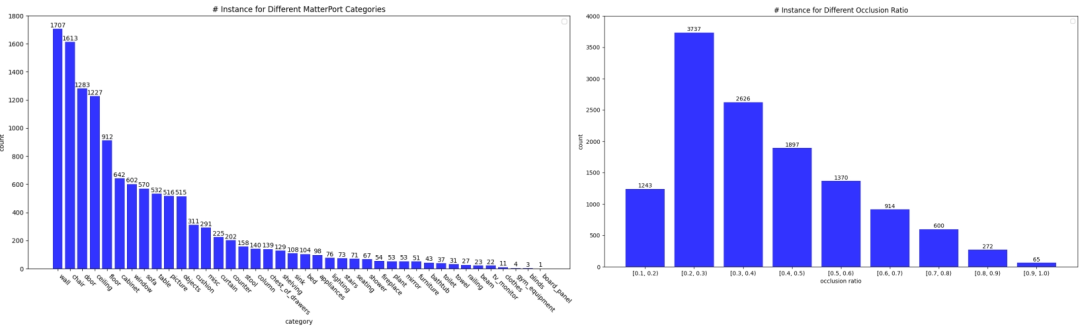
The statistics of the data set are as follows:
A sample of the data set is as follows:

#In addition, in order to solve the complete shape reconstruction task of any object, the author extracted Extract the prior knowledge about the complete shape of the object from the features of the Stable Diffusion model to perform non-modal segmentation of any occluded object. The specific architecture is as follows (SDAmodal):
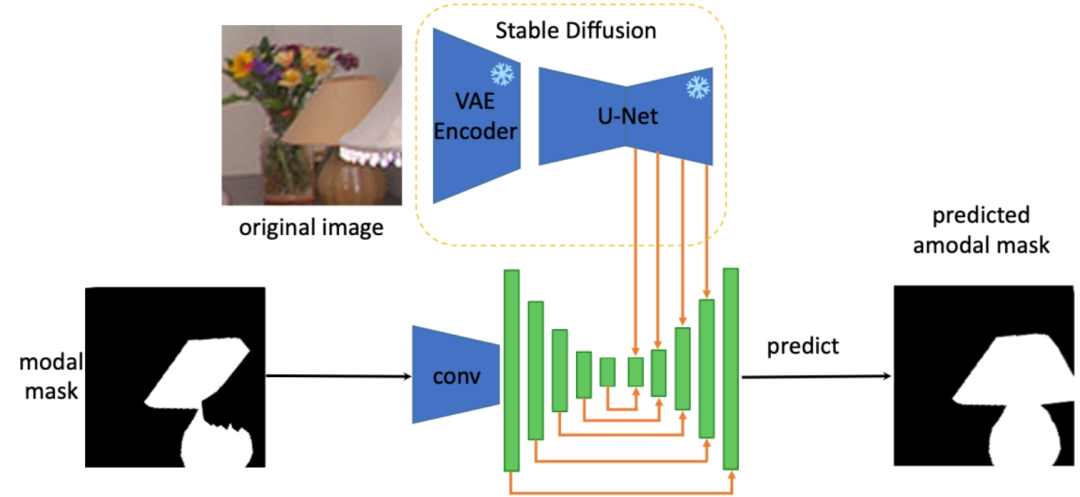
The motivation for using Stable Diffusion Feature is that Stable Diffusion has the ability to complete pictures, so it may contain all the information about the object to a certain extent; and because Stable Diffusion After training with a large number of pictures, we can expect its features to have the ability to process any object in any environment. Different from previous two-stage frameworks, SDAmodal does not require marked occlusion masks as input; SDAmodal has a simple structure, but shows strong zero-sample generalization ability (compare Settings F and H in the following table, only in training on COCOA can improve on another data set in a different domain and different categories); even if there is no annotation of occluded objects, SDAmodal can improve on the existing data set COCOA covering multiple types of occluded objects and the newly proposed On the MP3D-Amodal data set, SOTA performance (Setting H) has been achieved.
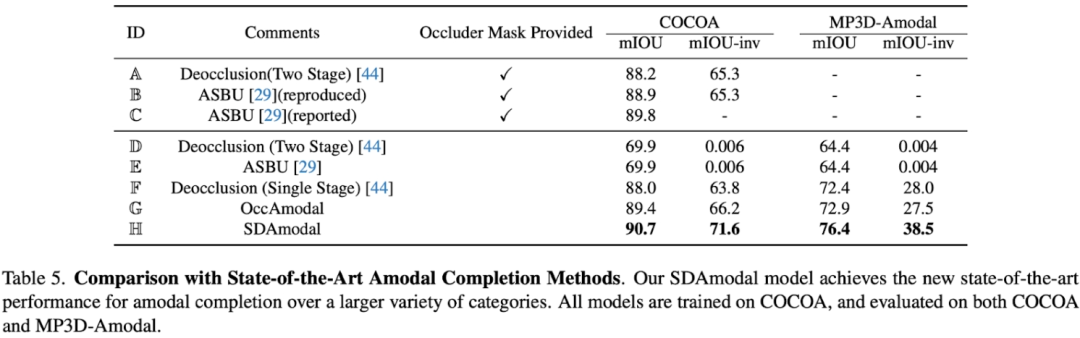
In addition to quantitative experiments, qualitative comparisons also reflect the advantages of the SDAmodal model: It can be observed from the figure below (all models are only in COCOA training), for different types of occluded objects, whether from COCOA or another MP3D-Amodal, SDAmodal can greatly improve the effect of non-modal segmentation, and the predicted non-modal mask is closer to reality of.

For more details, please read the original paper.
The above is the detailed content of 'AI Perspective Eye', three-time Marr Prize winner Andrew leads a team to solve the problem of occlusion and completion of any object. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
