

MySQL数据库性能优化六大技巧_MySQL

bitsCN.com
数据库表表面上存在索引和防错机制,然而一个简单的查询就会耗费很长时间。Web应用程序或许在开发环境中运行良好,但在产品环境中表现同样糟糕。如果你是个数据库管理员,你很有可能已经在某个阶段遇到上述情况。因此,本文将介绍对MySQL进行性能优化的技巧和窍门。
1.存储引擎的选择
如果数据表需要事务处理,应该考虑使用InnoDB,因为它完全符合ACID特性。如果不需要事务处理,使用默认存储引擎MyISAM是比较明智的。并且不要尝试同时使用这两个存储引擎。思考一下:在一个事务处理中,一些数据表使用InnoDB,而其余的使用MyISAM。结果呢?整个subject将被取消,只有那些在事务处理中的被带回到原始状态,其余的被提交的数据转存,这将导致整个数据库的冲突。然而存在一个简单的方法可以同时利用两个存储引擎的优势。目前大多数MySQL套件中包括InnoDB、编译器和链表,但如果你选择MyISAM,你仍然可以单独下载InnoDB,并把它作为一个插件。很简单的方法,不是吗?
2.计数问题
如果数据表采用的存储引擎支持事务处理(如InnoDB),你就不应使用COUNT(*)计算数据表中的行数。这是因为在产品类数据库使用COUNT(*),最多返回一个近似值,因为在某个特定时间,总有一些事务处理正在运行。如果使用COUNT(*)显然会产生bug,出现这种错误结果。
3.反复测试查询
查询最棘手的问题并不是无论怎样小心总会出现错误,并导致bug出现。恰恰相反,问题是在大多数情况下bug出现时,应用程序或数据库已经上线。的确不存在针对该问题切实可行的解决方法,除非将测试样本在应用程序或数据库上运行。任何数据库查询只有经过上千个记录的大量样本测试,才能被认可。
4.避免全表扫描
通常情况下,如果MySQL(或者其他关系数据库模型)需要在数据表中搜索或扫描任意特定记录时,就会用到全表扫描。此外,通常最简单的方法是使用索引表,以解决全表扫描引起的低效能问题。然而,正如我们在随后的问题中看到的,这存在错误部分。
5.使用”EXPLAIN”进行查询
当需要调试时,EXPLAIN是一个很好的命令,下面将对EXPLAIN进行深入探讨。
首先,创建一个简单的数据表:
CREATE TABLE awesome_pcq(
emp_id INT(10) NOTNULL DEFAULT '0',
full_name VARCHAR(100) NOTNULL,
email_id VARCHAR(100) NOT NULL,
password VARCHAR(50) NOT NULL,
deleted TINYINT(4) NOTNULL,
PRIMARYKEY(emp_id)
) COLLATE=utf8_general_ci
ENGINE=InnoDB
ROW_FORMAT=DEFAULT
这个数据表一目了然,共有五列,最后一列“deleted”是一个Boolean类变量flag来检查帐号是活动的还是已被删除。接下来,您需要用样本记录填充这个表(比如,100个雇员记录)。正如你看到的,主键是“emp_id”。因此,使用电子邮件地址和密码字段,我们可以很容易地创建一个查询,以验证或拒绝登录请求,如下(实例一):
SELECT COUNT(*) FROM awesome_pcq WHERE email_id='blahblah' AND password='blahblah' AND deleted=0
之前我们提到,要避免使用COUNT(*)。代码纠正如下(实例二):
SELECT emp_id FROM awesome_pcq WHERE email_id='blahblah' AND password='blahblah' AND deleted=0
现在回想一下,在实例一中,代码查询定位并返回“email_id”和“password”等于给定值的行数。在实例二中,进行了同样的查询,不同的是明确要求列出“emp_id”所有满足给定的标准的值。哪个查询更费时?
很显然,这两个实例都是同样费时的数据库查询,因为无意间,两个实例查询都进行了全表扫描。为了更好地读懂指令,执行如下代码:
EXPLAIN SELECT emp_id FROM awesome_pcq WHERE email_id='blahblah' AND password='blahblah' AND deleted=0 在输出时,集中在倒数第二列:“rows”。假设我们已经将表填充了100个记录,它会在第一行显示100,这是MySQL需要进行扫描用来计算查询的结果的行数。这说明了什么?这需要全表扫描。为了克服这个弊端,则需要添加索引。
6.添加索引
先从重要的说起:给每一个可能遇到的次要问题创建索引并不明智。过多的索引会导致效能减慢和资源占用。在进一步讨论之前,在实例中创建一个样本索引:
ALTER TABLE awesome_pcq ADDINDEX LoginValidate(email_id) 接下来,再次运行该查询:
EXPLAIN SELECT emp_id FROM awesome_pcq WHERE email_id='blahblah' AND password='blahblah' AND deleted=0
请注意运行后的值。不是100,而是1。因此,为了给出查询结果,MySQL只扫描了1行,多亏先前创建的索引。你可能会注意到,索引只在电子邮件地址字段创建,而查询对其他字段同样进行了搜索。这表明MySQL先执行了一个cros-check,检查是否有在WHERE子句中的定义的值有索引指定,如果有这样的值就执行相应的操作。
但是,它不是每次重复将减少到一个。例如,如果不是唯一的索引字段(如employee names列可以有两行相同的值),即使创建索引,也将有多个记录留下。但它仍然比全表扫描好。并且,在WHERE子句中指定列的顺序没有在这个过程中发挥作用。例如,如果在上面的查询中,改变字段的顺序,使电子邮件地址出现在最后,MySQL仍将遍历索引列的基础上。那么,就要在索引上动脑筋,注意如何避免大量的全表扫描,并获得更好的结果。不过,这需要经历一个很长的过程。
作者kongdaoxian
bitsCN.com
Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to connect Apple Vision Pro to PC
Apr 08, 2024 pm 09:01 PM
How to connect Apple Vision Pro to PC
Apr 08, 2024 pm 09:01 PM
The Apple Vision Pro headset is not natively compatible with computers, so you must configure it to connect to a Windows computer. Since its launch, Apple Vision Pro has been a hit, and with its cutting-edge features and extensive operability, it's easy to see why. Although you can make some adjustments to it to suit your PC, and its functionality depends heavily on AppleOS, so its functionality will be limited. How do I connect AppleVisionPro to my computer? 1. Verify system requirements You need the latest version of Windows 11 (Custom PCs and Surface devices are not supported) Support 64-bit 2GHZ or faster fast processor High-performance GPU, most
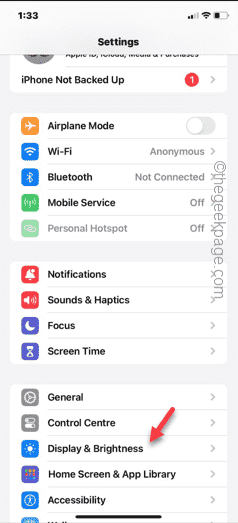 Shazam app not working in iPhone: Fix
Jun 08, 2024 pm 12:36 PM
Shazam app not working in iPhone: Fix
Jun 08, 2024 pm 12:36 PM
Having issues with the Shazam app on iPhone? Shazam helps you find songs by listening to them. However, if Shazam isn't working properly or doesn't recognize the song, you'll have to troubleshoot it manually. Repairing the Shazam app won't take long. So, without wasting any more time, follow the steps below to resolve issues with Shazam app. Fix 1 – Disable Bold Text Feature Bold text on iPhone may be the reason why Shazam is not working properly. Step 1 – You can only do this from your iPhone settings. So, open it. Step 2 – Next, open the “Display & Brightness” settings there. Step 3 – If you find that “Bold Text” is enabled
 Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
Four recommended AI-assisted programming tools
Apr 22, 2024 pm 05:34 PM
This AI-assisted programming tool has unearthed a large number of useful AI-assisted programming tools in this stage of rapid AI development. AI-assisted programming tools can improve development efficiency, improve code quality, and reduce bug rates. They are important assistants in the modern software development process. Today Dayao will share with you 4 AI-assisted programming tools (and all support C# language). I hope it will be helpful to everyone. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot is an AI coding assistant that helps you write code faster and with less effort, so you can focus more on problem solving and collaboration. Git
 Win11 Tips Sharing: Skip Microsoft Account Login with One Trick
Mar 27, 2024 pm 02:57 PM
Win11 Tips Sharing: Skip Microsoft Account Login with One Trick
Mar 27, 2024 pm 02:57 PM
Win11 Tips Sharing: One trick to skip Microsoft account login Windows 11 is the latest operating system launched by Microsoft, with a new design style and many practical functions. However, for some users, having to log in to their Microsoft account every time they boot up the system can be a bit annoying. If you are one of them, you might as well try the following tips, which will allow you to skip logging in with a Microsoft account and enter the desktop interface directly. First, we need to create a local account in the system to log in instead of a Microsoft account. The advantage of doing this is
 Learn how to develop mobile applications using Go language
Mar 28, 2024 pm 10:00 PM
Learn how to develop mobile applications using Go language
Mar 28, 2024 pm 10:00 PM
Go language development mobile application tutorial As the mobile application market continues to boom, more and more developers are beginning to explore how to use Go language to develop mobile applications. As a simple and efficient programming language, Go language has also shown strong potential in mobile application development. This article will introduce in detail how to use Go language to develop mobile applications, and attach specific code examples to help readers get started quickly and start developing their own mobile applications. 1. Preparation Before starting, we need to prepare the development environment and tools. head
 Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
Which AI programmer is the best? Explore the potential of Devin, Tongyi Lingma and SWE-agent
Apr 07, 2024 am 09:10 AM
On March 3, 2022, less than a month after the birth of the world's first AI programmer Devin, the NLP team of Princeton University developed an open source AI programmer SWE-agent. It leverages the GPT-4 model to automatically resolve issues in GitHub repositories. SWE-agent's performance on the SWE-bench test set is similar to Devin, taking an average of 93 seconds and solving 12.29% of the problems. By interacting with a dedicated terminal, SWE-agent can open and search file contents, use automatic syntax checking, edit specific lines, and write and execute tests. (Note: The above content is a slight adjustment of the original content, but the key information in the original text is retained and does not exceed the specified word limit.) SWE-A
 How to Install and Run the Ubuntu Notes App on Ubuntu 24.04
Mar 22, 2024 pm 04:40 PM
How to Install and Run the Ubuntu Notes App on Ubuntu 24.04
Mar 22, 2024 pm 04:40 PM
While studying in high school, some students take very clear and accurate notes, taking more notes than others in the same class. For some, note-taking is a hobby, while for others, it is a necessity when they easily forget small information about anything important. Microsoft's NTFS application is particularly useful for students who wish to save important notes beyond regular lectures. In this article, we will describe the installation of Ubuntu applications on Ubuntu24. Updating the Ubuntu System Before installing the Ubuntu installer, on Ubuntu24 we need to ensure that the newly configured system has been updated. We can use the most famous "a" in Ubuntu system
 What are the tips for novices to create forms?
Mar 21, 2024 am 09:11 AM
What are the tips for novices to create forms?
Mar 21, 2024 am 09:11 AM
We often create and edit tables in excel, but as a novice who has just come into contact with the software, how to use excel to create tables is not as easy as it is for us. Below, we will conduct some drills on some steps of table creation that novices, that is, beginners, need to master. We hope it will be helpful to those in need. A sample form for beginners is shown below: Let’s see how to complete it! 1. There are two methods to create a new excel document. You can right-click the mouse on a blank location on the [Desktop] - [New] - [xls] file. You can also [Start]-[All Programs]-[Microsoft Office]-[Microsoft Excel 20**] 2. Double-click our new ex
