

Let's talk about the model fusion method of large models

In previous practices, model fusion has been widely used, especially in discriminant models, where it is considered a method that can steadily improve performance. However, for generative language models, the way they operate is not as straightforward as for discriminative models because of the decoding process involved.
In addition, due to the increase in the number of parameters of large models, in scenarios with larger parameter scales, the methods that can be considered by simple ensemble learning are more limited than low-parameter machine learning, such as classic stacking and boosting Methods such as this cannot be easily expanded due to the parameter issues of the stacked model. Therefore, ensemble learning for large models requires careful consideration.
Below we explain five basic integration methods, namely model integration, probabilistic integration, grafting learning, crowdsourcing voting, and MOE.
1. Model integration
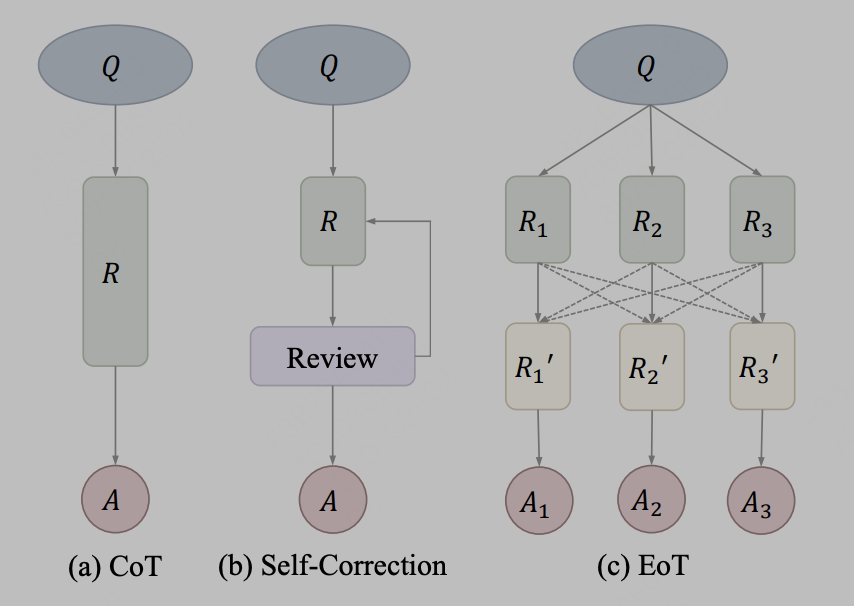
Model integration is relatively simple, that is, large models are integrated at the output text level. For example, simply use the output results of three different LLama models and input them as prompts. for reference in the fourth model. In practice, information transmission through text can be used as a communication method. The representative method is EoT, which comes from the article "Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication". EoT proposes a new ’s exchange-of-thought framework, known as Exchange-of-Thought, is designed to facilitate cross-communication between models to improve collective understanding in the problem-solving process. Through this framework, models can absorb the reasoning of other models to better coordinate and improve their own solutions. Represented by the diagram in the paper:
 Picture
Picture
After the author regards CoT and self-correction methods as the same concept, EoT provides a new method that allows hierarchical messaging between multiple models. By communicating across models, models can draw on each other's reasoning and thought processes, helping to solve problems more effectively. This approach is expected to improve model performance and accuracy.
2. Probabilistic ensemble
Probabilistic ensemble has similarities with traditional machine learning methods. For example, an ensemble method can be formed by averaging the logit results predicted by the model. In large models, probabilistic ensembles can be fused at the level of the vocabulary output probabilities of the transformer model. It is important to note that this operation requires that the vocabularies of the multiple original models that are fused must be consistent. Such an integration method can improve the performance and robustness of the model, making it more suitable for practical application scenarios.
Below we give a simple pseudocode implementation.
kv_cache = NoneWhile True:input_ids = torch.tensor([[new_token]], dtype=torch.long, device='cuda')kv_cache1, kv_cache2 = kv_cache output1 = models[0](input_ids=input_ids, past_key_values=kv_cache1, use_cache=True)output2 = models[1](input_ids=input_ids, past_key_values=kv_cache2, use_cache=True)kv_cache = [output1.past_key_values, output2.past_key_values]prob = (output1.logits + output2.logits) / 2new_token = torch.argmax(prob, 0).item()
3. Grafting learning
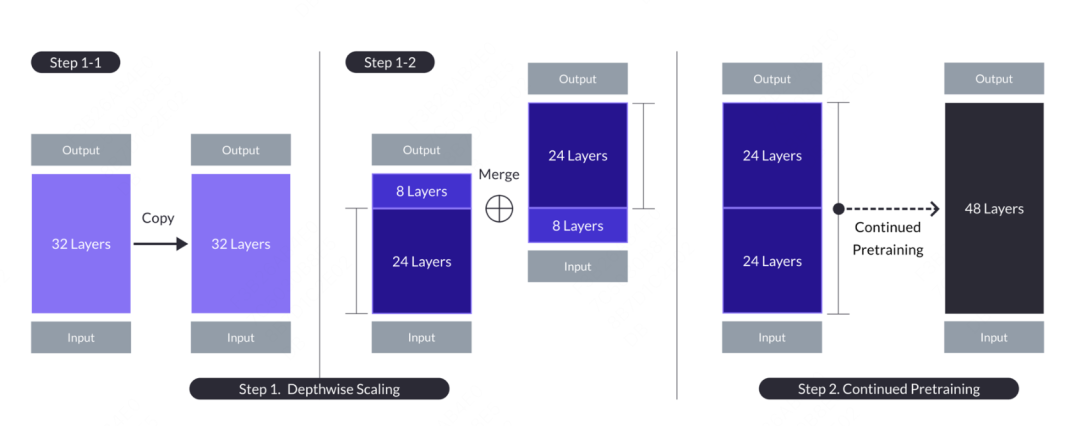
The concept of grafting learning comes from the domestic Kaggle Grandmaster’s plantsgo, which originated from the data mining competition. It is essentially a kind of transfer learning, which was originally used to describe the method of using the output of one tree model as the input of another tree model. This method is similar to grafting in tree reproduction, hence the name. In large models, there is also the application of grafting learning. The model name is SOLAR. The article comes from "SOLAR 10.7B: Scaling Large Language Models with Simple yet Effective Depth Up-Scaling". The article proposes an idea of model grafting. Different from grafting learning in machine learning, the large model does not directly fuse the probability results of another model, but grafts part of the structure and weights to the fusion model, and undergoes a certain pre-training process to make it Model parameters can be adapted to new models. The specific operation is to copy the basic model containing n layers for subsequent modification. Then, the last m layers are removed from the original model and the first m layers are removed from its copy, resulting in two different n-m layer models. Finally, the two models are concatenated to form a scaled model with 2*(n-m) layers.
When you need to build a 48-layer target model, you can consider taking the first 24 layers and the last 24 layers from two 32-layer models, and connecting them to form a new 48-layer model. Then, the combined model is further pre-trained. In general, continuing pre-training requires less data volume and computing resources than training from scratch.
 Picture
Picture
After continuing the pre-training, an alignment operation needs to be performed, which includes two processes, namely instruction fine-tuning and DPO. Instruction fine-tuning uses open source instruct data and transforms it into a math-specific instruct data to enhance the mathematical capabilities of the model. DPO is a replacement for the traditional RLHF, which eventually became the SOLAR-chat version.
4. Crowdsourcing Voting
Crowdsourcing voting was used in this year’s WSDM CUP first place plan, and has been practiced in past domestic generation competitions. The core idea is: if the sentence generated by a model is most similar to the results of all models, then this sentence can be considered as the average of all models. In this way, the average in the sense of probability becomes the average in the token generation results. Suppose that given a test sample, we have a candidate answer that needs to be aggregated. For each candidate, we calculate the correlation score between ) and () and add them together as the quality score of (). Similarly, the correlation is quantified Sources can be embedding layer cosine similarity (denoted as emb_a_s), word-level ROUGE-L (denoted as word_a_f) and character-level ROUGE-L (denoted as char_a_f). Here are some artificially constructed similarity indicators, including literal And semantically.
Code address: https://github.com/zhangzhao219/WSDM-Cup-2024/tree/main
5. MoE
Finally, It is also the most important large model Mixture of Experts (MoE), which is a model architecture method that combines multiple sub-models (i.e. "experts") and aims to improve the overall performance through the collaborative work of multiple experts. Prediction effect. The MoE structure can significantly enhance the processing power and operating efficiency of the model. A typical large model MoE architecture includes a gating mechanism (Gating Mechanism) and a series of expert networks. The gating mechanism is responsible for dynamically allocating experts based on input data The weight of each expert is used to determine the degree of contribution of each expert to the final output; at the same time, the expert selection mechanism will select a part of the experts to participate in the actual prediction calculation according to the instructions of the gating signal. This design not only reduces the overall calculation requirements, and also enables the model to select the most suitable experts based on different inputs.
Mixture of Experts (Mixture of Experts, MoE) is not a new concept recently. The concept of mixed expert models can be traced back to The paper "Adaptive Mixture of Local Experts" published in 1991. This method is similar to ensemble learning. Its core is to create a coordination and fusion mechanism for a collection of independent expert networks. Under such a structure, each An independent network (i.e., "expert") is responsible for processing a specific subset of the data set and focusing on a specific input data area. This subset may be biased towards a certain topic, a certain field, a certain problem classification, etc., and It is not a display concept.
Faced with different input data, a key issue is how the system decides which expert to handle. The Gating Network is here to solve this problem. It distributes Weights are used to determine the job responsibilities of each expert. During the entire training process, these expert networks and gated networks will be trained at the same time, and do not require explicit manual manipulation.
During the period from 2010 to 2015 Here, there are two research directions that have had an important impact on the further development of the mixed expert model (MoE):
组件化专家:在传统的MoE框架中,系统由一个门控网络和若干个专家网络构成。在支持向量机(SVM)、高斯过程以及其他机器学习方法的背景下,MoE常常被当作模型中的一个单独部分。然而,Eigen、Ranzato和Ilya等研究者提出了将MoE作为深层网络中一个内部组件的想法。这种创新使得MoE可以被整合进多层网络的特定位置中,从而使模型在变得更大的同时,也能保持高效。
条件计算:传统神经网络会在每一层对所有输入数据进行处理。在这段时期,Yoshua Bengio等学者开始研究一种基于输入特征动态激活或者禁用网络部分的方法。
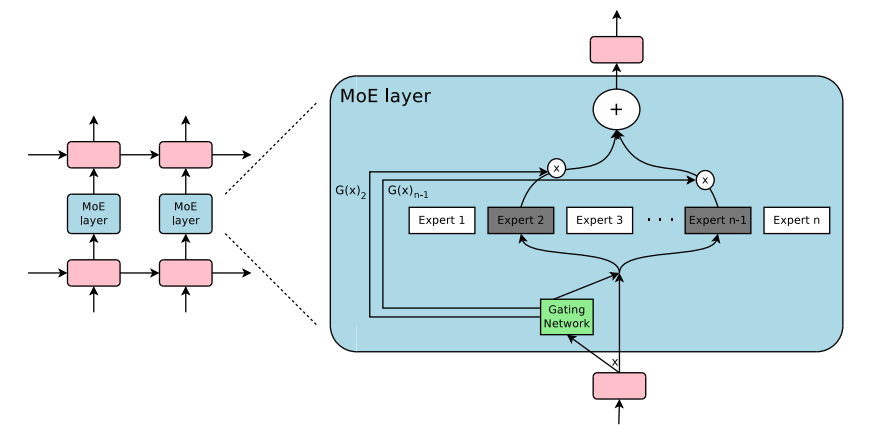
这两项研究的结合推动了混合专家模型在自然语言处理(NLP)领域的应用。尤其是在2017年,Shazeer和他的团队将这一理念应用于一个137亿参数的LSTM模型(这是当时在NLP领域广泛使用的一种模型架构,由Schmidhuber提出)。他们通过引入稀疏性来实现在保持模型规模巨大的同时,加快推理速度。这项工作主要应用于翻译任务,并且面对了包括高通信成本和训练稳定性问题在内的多个挑战。如图所示《Outrageously Large Neural Network》 中的MoE layer架构如下:
 图片
图片
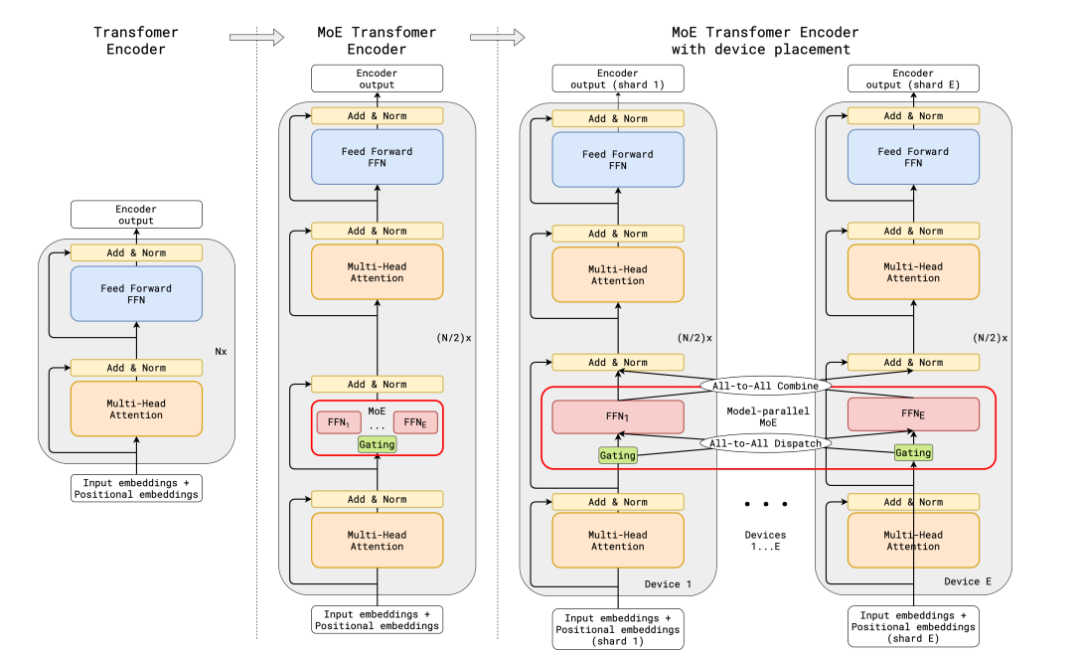
传统的MoE都集中在非transfomer的模型架构上,大模型时代的transfomer模型参数量达百亿级,如何在transformer上应用MoE并且把参数扩展到百亿级别,并且解决训练稳定性和推理效率的问题,成为MoE在大模型应用上的关键问题。谷歌提出了代表性的方法Gshard,成功将Transformer模型的参数量增加至超过六千亿,并以此提升模型水平。
在GShard框架下,编码器和解码器中的每个前馈网络(FFN)层被一种采用Top-2门控机制的混合专家模型(MoE)层所替代。下面的图示展现了编码器的结构设计。这样的设计对于执行大规模计算任务非常有利:当模型被分布到多个处理设备上时,MoE层在各个设备间进行共享,而其他层则在每个设备上独立复制。其架构如下图所示:
 图片
图片
为了确保训练过程中的负载均衡和效率,GShard提出了三种关键的技术,分别是损失函数,随机路由机制,专家容量限制。
辅助负载均衡损失函数:损失函数考量某个专家的buffer中已经存下的token数量,乘上某个专家的buffer中已经存下的token在该专家上的平均权重,构建这样的损失函数能让专家负载保持均衡。
随机路由机制:在Top-2的机制中,我们总是选择排名第一的专家,但是排名第二的专家则是通过其权重的比例来随机选择的。
专家容量限制:我们可以设置一个阈值来限定一个专家能够处理的token数量。如果两个专家的容量都已经达到了上限,那么令牌就会发生溢出,这时token会通过残差连接传递到下一层,或者在某些情况下被直接丢弃。专家容量是MoE架构中一个非常关键的概念,其存在的原因是所有的张量尺寸在编译时都已经静态确定,我们无法预知会有多少token分配给每个专家,因此需要预设一个固定的容量限制。
需要注意的是,在推理阶段,只有部分专家会被激活。同时,有些计算过程是被所有token共享的,比如自注意力(self-attention)机制。这就是我们能够用相当于12B参数的稠密模型计算资源来运行一个含有8个专家的47B参数模型的原因。如果我们使用Top-2门控机制,模型的参数量可以达到14B,但是由于自注意力操作是专家之间共享的,实际在模型运行时使用的参数量是12B。
整个MoeLayer的原理可以用如下伪代码表示:
M = input.shape[-1] # input维度为(seq_len, batch_size, M),M是注意力输出embedding的维度reshaped_input = input.reshape(-1, M)gates = softmax(einsum("SM, ME -> SE", reshaped_input, Wg)) #输入input,Wg是门控训练参数,维度为(M, E),E是MoE层中专家的数量,输出每个token被分配给每个专家的概率,维度为(S, E)combine_weights, dispatch_mask = Top2Gating(gates) #确定每个token最终分配给的前两位专家,返回相应的权重和掩码dispatched_expert_input = einsum("SEC, SM -> ECM", dispatch_mask, reshaped_input) # 对输入数据进行排序,按照专家的顺序排列,为分发到专家计算做矩阵形状整合h = enisum("ECM, EMH -> ECH", dispatched_expert_input, Wi) #各个专家计算分发过来的input,本质上是几个独立的全链接层h = relu(h)expert_outputs = enisum("ECH, EHM -> ECM", h, Wo) #各个专家的输出outputs = enisum("SEC, ECM -> SM", combine_weights, expert_outputs) #最后,进行加权计算,得到最终MoE-layer层的输出outputs_reshape = outputs.reshape(input.shape) # 从(S, M)变成(seq_len, batch_size, M)Regarding the architectural improvement of MoE, Switch Transformers designed a special Switch Transformer layer that can process two independent inputs (i.e. two different tokens) and is equipped with four experts for processing. Contrary to the original top2 expert idea, Switch Transformers adopts a simplified top1 expert strategy. As shown in the figure below:
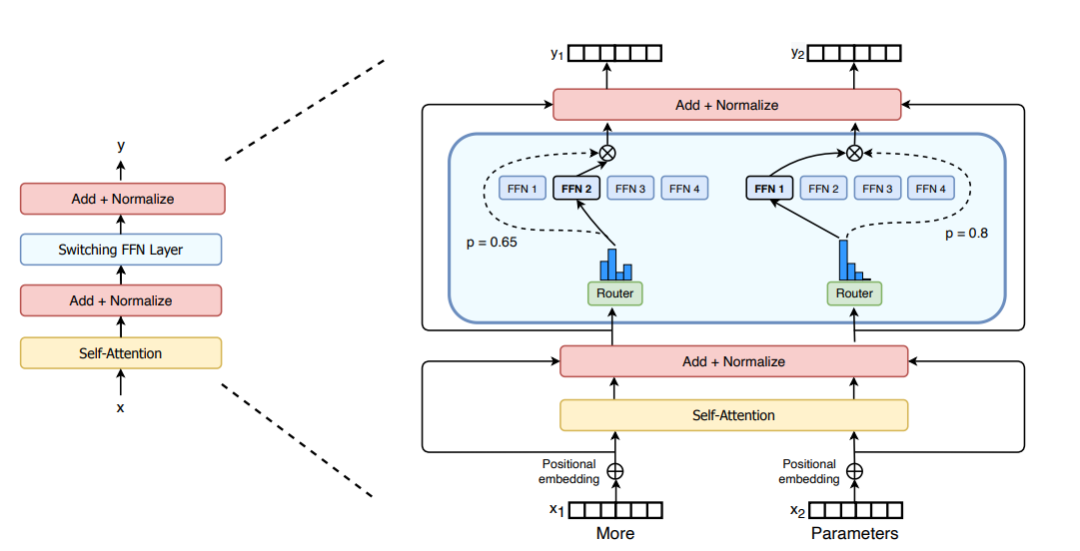 Picture
Picture
The difference is that the architecture of DeepSeek MoE, a well-known domestic large model, is designed with a shared expert who participates in activation every time , its design is based on the premise that a specific expert can be proficient in a specific knowledge field. By fine-grained segmentation of experts' knowledge areas, it is possible to prevent a single expert from needing to master too much knowledge, thereby avoiding the confusion of knowledge. At the same time, setting up shared experts ensures that some universally applicable knowledge is utilized in every calculation. 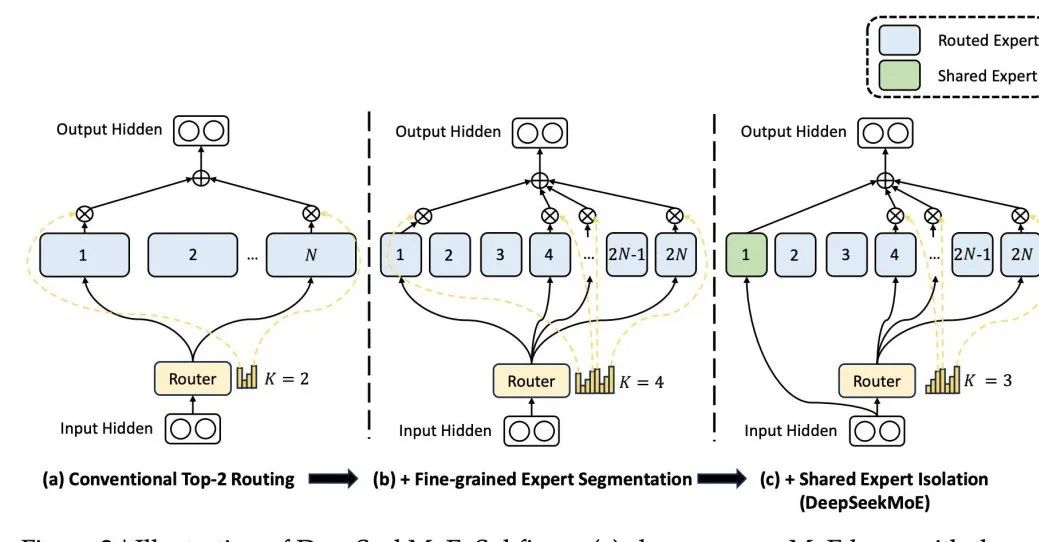 picture
picture
The above is the detailed content of Let's talk about the model fusion method of large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 What are the top ten virtual currency trading platforms? Ranking of the top ten virtual currency trading platforms in the world
Feb 20, 2025 pm 02:15 PM
What are the top ten virtual currency trading platforms? Ranking of the top ten virtual currency trading platforms in the world
Feb 20, 2025 pm 02:15 PM
With the popularity of cryptocurrencies, virtual currency trading platforms have emerged. The top ten virtual currency trading platforms in the world are ranked as follows according to transaction volume and market share: Binance, Coinbase, FTX, KuCoin, Crypto.com, Kraken, Huobi, Gate.io, Bitfinex, Gemini. These platforms offer a wide range of services, ranging from a wide range of cryptocurrency choices to derivatives trading, suitable for traders of varying levels.
 Do I need to use flexbox in the center of the Bootstrap picture?
Apr 07, 2025 am 09:06 AM
Do I need to use flexbox in the center of the Bootstrap picture?
Apr 07, 2025 am 09:06 AM
There are many ways to center Bootstrap pictures, and you don’t have to use Flexbox. If you only need to center horizontally, the text-center class is enough; if you need to center vertically or multiple elements, Flexbox or Grid is more suitable. Flexbox is less compatible and may increase complexity, while Grid is more powerful and has a higher learning cost. When choosing a method, you should weigh the pros and cons and choose the most suitable method according to your needs and preferences.
 How to adjust Sesame Open Exchange into Chinese
Mar 04, 2025 pm 11:51 PM
How to adjust Sesame Open Exchange into Chinese
Mar 04, 2025 pm 11:51 PM
How to adjust Sesame Open Exchange to Chinese? This tutorial covers detailed steps on computers and Android mobile phones, from preliminary preparation to operational processes, and then to solving common problems, helping you easily switch the Sesame Open Exchange interface to Chinese and quickly get started with the trading platform.
 Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
Mar 17, 2025 pm 06:03 PM
Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
Mar 17, 2025 pm 06:03 PM
The top ten cryptocurrency trading platforms include: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
 How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
How to calculate c-subscript 3 subscript 5 c-subscript 3 subscript 5 algorithm tutorial
Apr 03, 2025 pm 10:33 PM
The calculation of C35 is essentially combinatorial mathematics, representing the number of combinations selected from 3 of 5 elements. The calculation formula is C53 = 5! / (3! * 2!), which can be directly calculated by loops to improve efficiency and avoid overflow. In addition, understanding the nature of combinations and mastering efficient calculation methods is crucial to solving many problems in the fields of probability statistics, cryptography, algorithm design, etc.
 Top 10 virtual currency trading platforms 2025 cryptocurrency trading apps ranking top ten
Mar 17, 2025 pm 05:54 PM
Top 10 virtual currency trading platforms 2025 cryptocurrency trading apps ranking top ten
Mar 17, 2025 pm 05:54 PM
Top Ten Virtual Currency Trading Platforms 2025: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
 What are the safe and reliable digital currency platforms?
Mar 17, 2025 pm 05:42 PM
What are the safe and reliable digital currency platforms?
Mar 17, 2025 pm 05:42 PM
A safe and reliable digital currency platform: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
 Recommended safe virtual currency software apps Top 10 digital currency trading apps ranking 2025
Mar 17, 2025 pm 05:48 PM
Recommended safe virtual currency software apps Top 10 digital currency trading apps ranking 2025
Mar 17, 2025 pm 05:48 PM
Recommended safe virtual currency software apps: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Security, liquidity, handling fees, currency selection, user interface and customer support should be considered when choosing a platform.
