
 Technology peripherals
AI
Tsinghua NLP Group released InfLLM: No additional training required, '1024K ultra-long context' 100% recall!
Technology peripherals
AI
Tsinghua NLP Group released InfLLM: No additional training required, '1024K ultra-long context' 100% recall!
Tsinghua NLP Group released InfLLM: No additional training required, '1024K ultra-long context' 100% recall!

Large-scale models can only remember and understand limited context, which has become a major limitation in their practical applications. For example, conversational AI systems are often unable to persistently remember the content of the previous day's conversations, which results in agents built using large models exhibiting inconsistent behavior and memory.
To allow large models to better handle longer contexts, the researchers proposed a new method called InfLLM. This method, jointly proposed by researchers from Tsinghua University, MIT, and Renmin University, enables large language models (LLMs) to handle very long texts without additional training. InfLLM utilizes a small amount of computing resources and graphics memory overhead to achieve efficient processing of very long texts.

Paper address: https://arxiv.org/abs/2402.04617
Code warehouse: https://github.com/thunlp/InfLLM
The experimental results show that InfLLM can effectively expand the context processing window of Mistral and LLaMA, and perform the task of finding a needle in a haystack of 1024K contexts. Achieve 100% recall.
Research background
Large-scale pre-trained language models (LLMs) have made breakthrough progress in many tasks in recent years and have become the basic model for many applications.
These practical applications also pose higher challenges to the ability of LLMs to process long sequences. For example, an LLM-driven agent needs to continuously process information received from the external environment, which requires it to have stronger memory capabilities. At the same time, conversational AI needs to better remember the content of conversations with users in order to generate more personalized responses.
However, current large-scale models are usually only pre-trained on sequences containing thousands of Tokens, which leads to two major challenges when applying them to very long texts:
1. Out-of-distribution length: Directly applying LLMs to longer length texts often requires LLMs to process position encodings that exceed the training range. , thus causing Out-of-Distribution problem and unable to be generalized;
2. Attention interference:Excessively long context will make The model attention is excessively divided into irrelevant information, making it unable to effectively model long-range semantic dependencies in context.
Method introduction
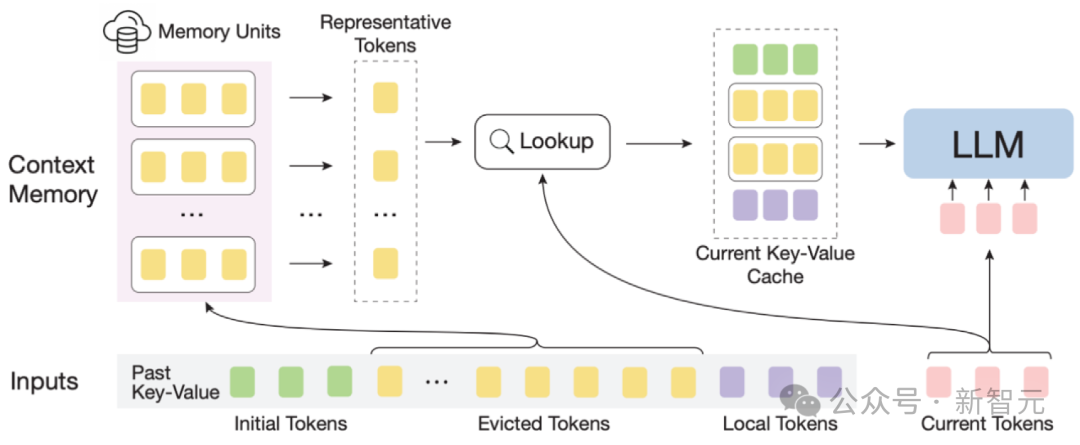
InfLLM diagram
In order to efficiently implement large models Length generalization ability, the authors propose a training-free memory enhancement method, InfLLM, for streaming processing of very long sequences.
InfLLM aims to stimulate the intrinsic ability of LLMs to capture long-distance semantic dependencies in ultra-long contexts with limited computational cost, thereby enabling efficient long text understanding.
Overall framework: Considering the sparsity of long text attention, processing each Token usually requires only a small part of its context.
The author built an external memory module to store ultra-long context information; using a sliding window mechanism, at each calculation step, there are only Tokens (Local Tokens) that are close to the current Token. A small amount of relevant information in the external memory module is involved in the calculation of the attention layer, while other irrelevant noise is ignored.
Therefore, LLMs can use a limited window size to understand the entire long sequence and avoid introducing noise.
However, the massive context in ultra-long sequences brings significant challenges to the effective location of relevant information in the memory module and the efficiency of memory search.
In order to deal with these challenges, each memory unit in the context memory module consists of a semantic block, and a semantic block consists of several consecutive Tokens.
Specifically, (1) In order to effectively locate relevant memory units, the coherent semantics of each semantic block can more effectively meet the needs of related information queries than fragmented Tokens.
In addition, the author selects the semantically most important Token from each semantic block, that is, the Token that receives the highest attention score, as the representation of the semantic block. This method helps To avoid the interference of unimportant Tokens in the correlation calculation.
(2) For efficient memory search, the memory unit at the semantic block level avoids token-by-token and attention-by-attention correlation calculations, reducing computational complexity.
In addition, semantic block-level memory units ensure continuous memory access and reduce memory loading costs.
Thanks to this, the author designed an efficient offloading mechanism (Offloading) for the context memory module.
Considering that most memory units are not used frequently, InfLLM unloads all memory units to CPU memory and dynamically retains frequently used memory units in GPU memory, thus Significantly reduced video memory usage.
InfLLM can be summarized as:
1. Based on the sliding window, a remote context memory module is added.
2. Divide the historical context into semantic blocks to form memory units in the context memory module. Each memory unit determines a representative token through its attention score in the previous attention calculation, as the representation of the memory unit. Thereby avoiding noise interference in the context and reducing memory query complexity
Experimental analysis
The author is working on Mistral-7b-Inst-v0.2 (32K) and Vicuna InfLLM is applied on the -7b-v1.5 (4K) model, using local window sizes of 4K and 2K respectively.
Compared with the original model, positional coding interpolation, Infinite-LM and StreamingLLM, significant performance improvements have been achieved on long text data Infinite-Bench and Longbench.
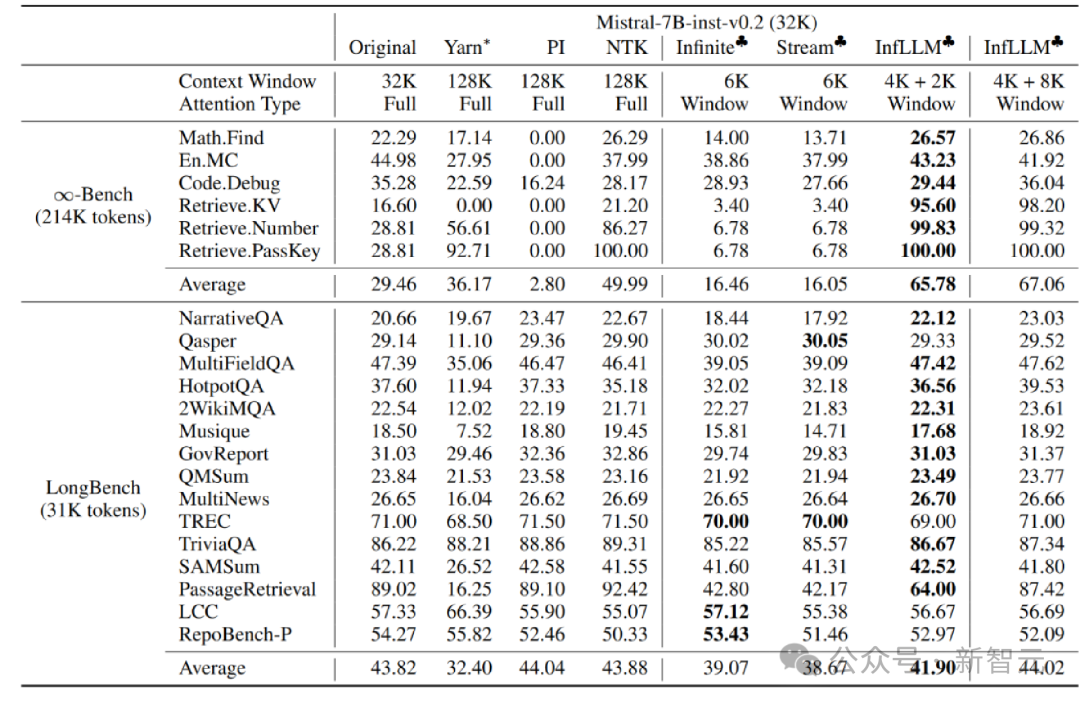
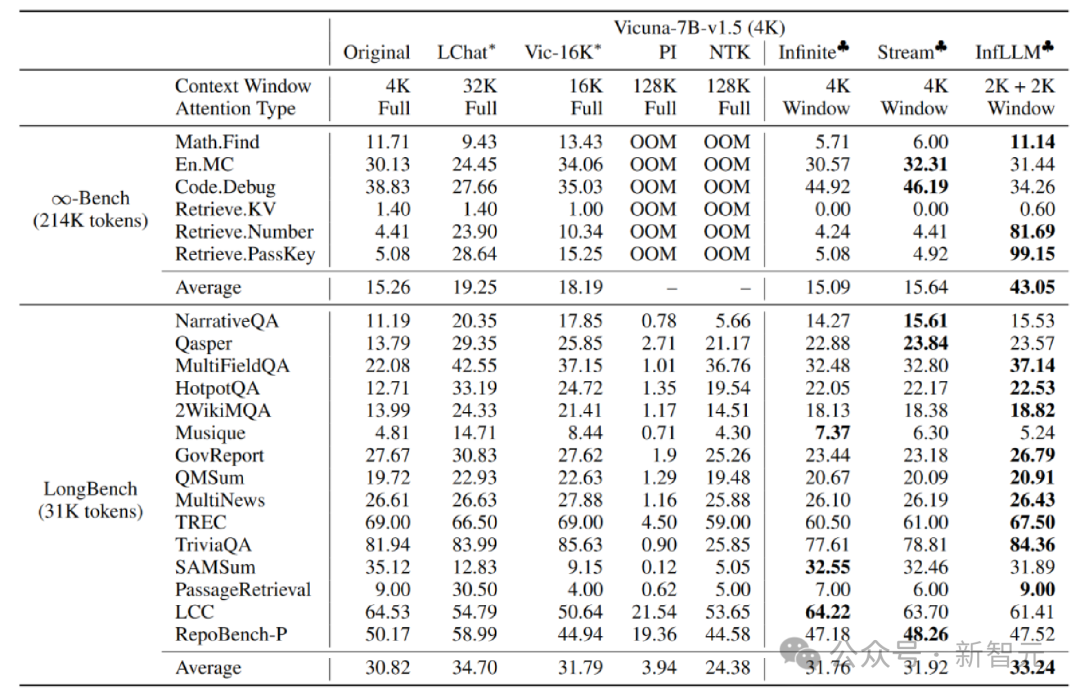
##Super long text experiment
In addition, the author continues to explore the generalization ability of InfLLM on longer texts, and can still maintain a 100% recall rate in the "needle in a haystack" task of 1024K length.
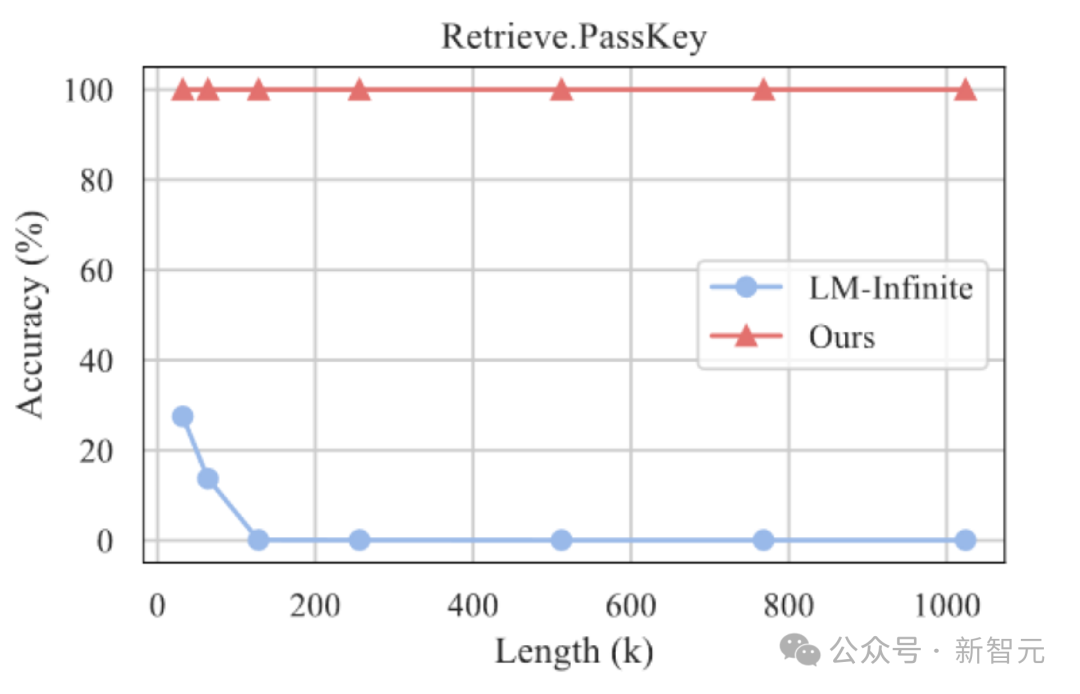
Needle in a haystack experimental results
SummaryIn this article, the team InfLLM is proposed, which can realize the extension of LLM for ultra-long text processing without training and can capture long-distance semantic information.
Based on the sliding window, InfLLM adds a memory module containing long-distance context information, and uses cache and offload mechanisms to implement streaming long text reasoning with a small amount of calculation and memory consumption. .
The above is the detailed content of Tsinghua NLP Group released InfLLM: No additional training required, '1024K ultra-long context' 100% recall!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
