
 Technology peripherals
AI
What to do if there is no data end-to-end? ActiveAD: End-to-end active learning for autonomous driving for planning!
Technology peripherals
AI
What to do if there is no data end-to-end? ActiveAD: End-to-end active learning for autonomous driving for planning!
What to do if there is no data end-to-end? ActiveAD: End-to-end active learning for autonomous driving for planning!


#End-to-end differentiable learning for autonomous driving has recently become a prominent paradigm. A major bottleneck is its huge demand for high-quality labeled data, such as 3D boxes and semantic segmentation, which are notoriously expensive to manually annotate. This difficulty is compounded by the salient fact that within-sample behavior in AD often has long-tailed distributions. In other words, most of the data collected may be trivial (e.g., driving forward on a straight road), with only a few situations being safety critical. In this paper, we explore a practically important but underexplored issue, namely how to achieve sample and label efficiency in end-to-end AD.
Specifically, the paper designs a planning-oriented active learning method that gradually annotates parts of the collected raw data based on the diversity and usefulness criteria of the proposed planning routes. Empirically, the proposed plan-oriented approach can outperform general active learning approaches to a large extent. Notably, our method achieves comparable performance to state-of-the-art end-to-end AD methods using only 30% of nuScenes data. Hopefully our work will inspire future work from a data-centric perspective, in addition to methodological efforts.
Paper link: https://arxiv.org/pdf/2403.02877.pdf
Main contribution of this article:
- The first in-depth study of E2E-AD People with data problems. Also provides a simple yet effective solution to identify and annotate valuable data for planning within a limited budget.
- Based on the planning-oriented philosophy of the end-to-end approach, new task-specific diversity and uncertainty measures are designed for planning routes.
- A large number of experiments and ablation studies have proven the effectiveness of the method. ActiveAD outperforms generic peer-to-peer methods by a large margin and achieves comparable performance to SOTA methods with full labels using only 30% of nuScenes data.
Method introduction
ActiveAD is described in detail in the end-to-end AD framework, and diversity and uncertainty indicators are designed based on the data characteristics of AD .
1) Initial sample selection for labels
For active learning in computer vision, initial sample selection is usually based only on the original image without additional information or learning characteristics, which has led to the common practice of random initialization. In the case of AD, there is additional prior information available. Specifically, when collecting data from sensors, traditional information such as the speed and trajectory of the self-vehicle can be recorded simultaneously. Additionally, weather and lighting conditions are often continuous and easy to annotate at the fragment level. This information facilitates making informed choices for initial set selection. Therefore, we designed a self-diversity measure for initial selection.
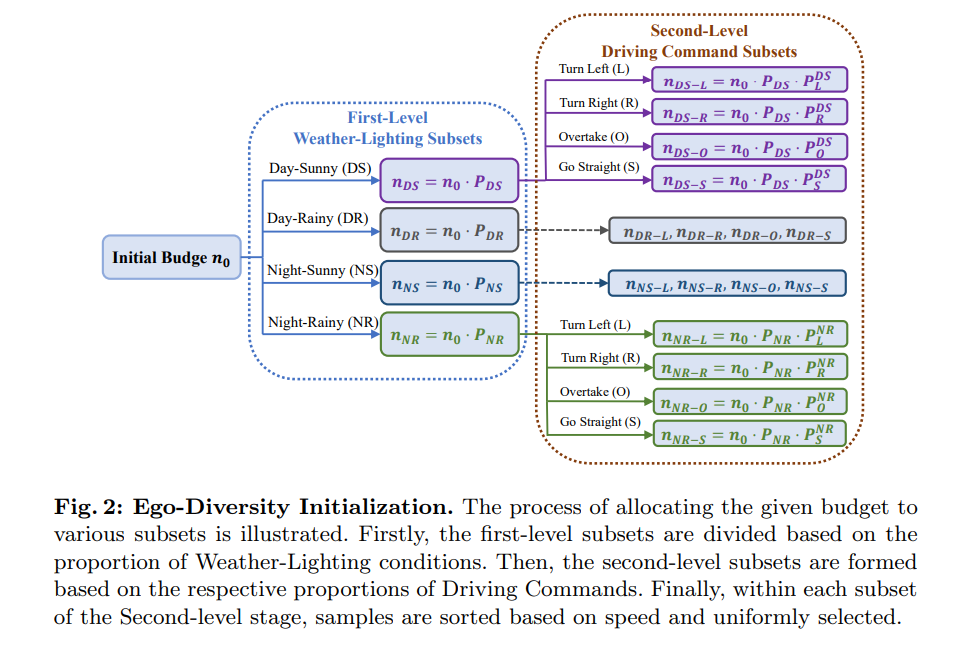
Ego Diversity: Consists of three parts: 1) Weather lighting 2) Driving instructions 3) Average speed. First, use the description in nuScenes to divide the complete data set into four mutually exclusive subsets: Day Sunny (DS), Day Rainy (DR), Night Sunny (NS), NightRainy (NR). Secondly, each subset is divided into four categories based on the number of left, right and straight driving commands in a complete segment: left turn (L), right turn (R), overtaking (O), and go straight (S). The paper designs a threshold τc, where if the number of left and right commands in a clip is greater than or equal to the threshold τc, we regard it as a transcendent behavior in the clip. If only the number of left commands is greater than the threshold τc, it indicates a left turn. If only the number of rightward commands is greater than the threshold τc, it indicates a right turn. All other cases are considered direct. Third, calculate the average speed in each scene and sort them in ascending order within the relevant subset.
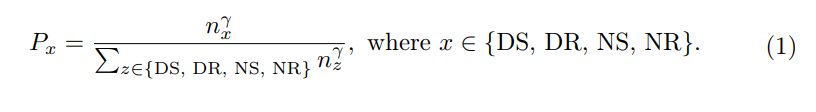
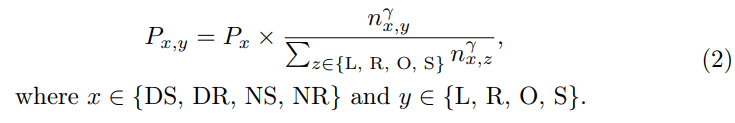
Figure 2 gives the detailed intuitive process of the initial selection process based on multi-way trees.
2) Criterion design for incremental selection
In this section we will introduce how to incrementally annotate new parts of a fragment based on a model trained with annotated fragments . We will use the intermediate model to perform inference on unlabeled segments, and subsequent selections are based on these outputs. Nonetheless, a planning-oriented perspective is adopted and three criteria for subsequent data selection are introduced: displacement errors, soft collisions, and proxy uncertainties.
Standard 1: Displacement error (DE). will be expressed as the distance between the model’s predicted planned route τ and the human trajectories τ* recorded in the dataset.
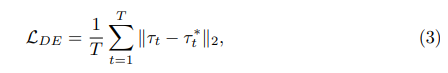
where T represents the frame in the scene. Since the displacement error is itself a performance metric (no annotation required), it naturally becomes the first and most critical criterion in active selection.
Standard 2: Soft collision (SC). LSC is defined as the distance between the predicted self-vehicle trajectory and the predicted agent trajectory. Low confidence agent predictions will be filtered out by the threshold ε. In each scenario, the shortest distance is chosen as the measure of hazard coefficient. At the same time, maintain a positive correlation between term and nearest distance:
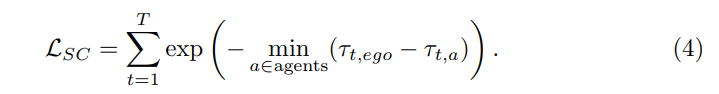
Use "soft collision" as a criterion because: on the one hand, unlike "displacement error", " The calculation of "collision ratio" depends on annotations of the target's 3D box, which are not available in unlabeled data. Therefore, it should be possible to calculate the criterion based solely on the model's inference results. On the other hand, consider a hard collision criterion: if the predicted self-vehicle trajectory will collide with the trajectories of other predicted agents, assign it 1, otherwise assign it 0. However, this may result in too few samples with label 1, since the collision rate of state-of-the-art models in AD is usually small (less than 1%). Therefore, it was chosen to use the closest distance to other pairs of targets instead of the "collision rate" metric. The risk is considered much higher when the distance to other vehicles or pedestrians is too close. In short, "soft collisions" are an effective measure of collision likelihood and can provide intensive oversight.
Standard III: agent uncertainty (AU). Predictions of the future trajectories of surrounding agents are naturally uncertain, so motion prediction modules typically generate multiple modalities and corresponding confidence scores. Our goal is to select data for which nearby agents have high uncertainty. Specifically, distant subjects are filtered out by a distance threshold δ, and the weighted entropy of the predicted probabilities of multiple modes for the remaining subjects is calculated. Assume that the number of modalities is and the agent’s confidence score in different modalities is Pi(a), where i∈{1,…,Nm}. Then, Agent uncertainty can be defined as:
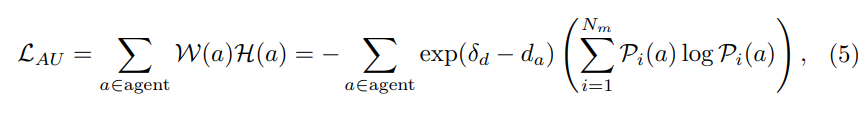
3) Overall initiative Learning Paradigm
Alg1 introduces the entire workflow of the method. Given an available budget B, an initial selection size n0, the number of activity selections made at each step ni, and a total of M selection stages. Selection is first initialized using the randomization or self-diversity methods described above. Then, the currently annotated data is used to train the network. Based on the trained network, we make predictions on the unlabeled ones and calculate the total loss. Finally, the samples are sorted according to the overall loss and the top ni samples to be annotated in the current iteration are selected. This process is repeated until the iteration reaches the upper limit M and the number of selected samples reaches the upper limit B.
Experimental results
Experiments were conducted on the widely used nuScenes dataset. All experiments are implemented using PyTorch and run on RTX 3090 and A100 GPUs.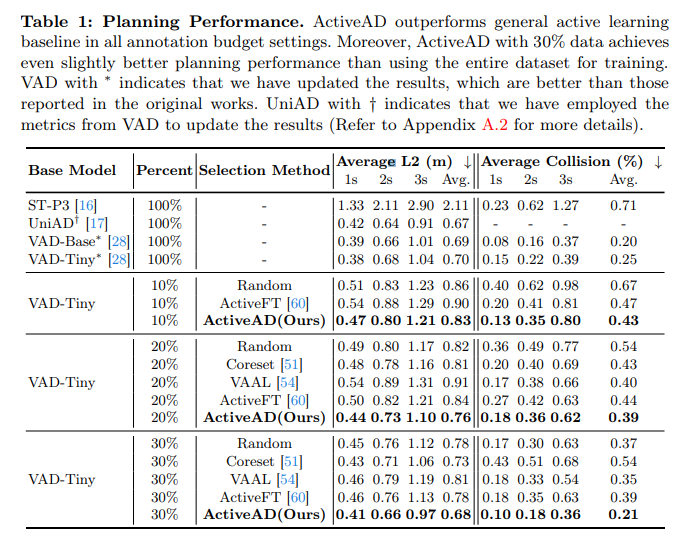
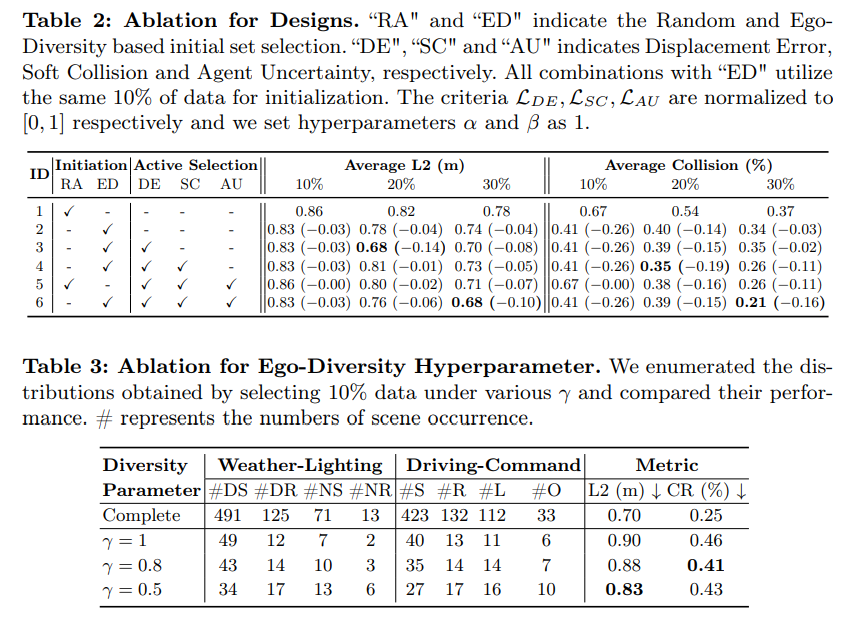
Figure 3: Visualization of selected scenes. Displacement error (col 1), soft collision (col 2), agent uncertainty (col 3) and hybrid (col 4) criteria based on selected front camera images based on a model trained on 10% of the data. Mixed represents our final choice strategy, ActiveAD, and takes the first three scenarios into consideration!

Table 4, performance in various scenarios. The smaller the average L2(m)/average collision rate (%) of the active model using 30% of the data, the better the performance under various weather/lighting and driving command conditions.
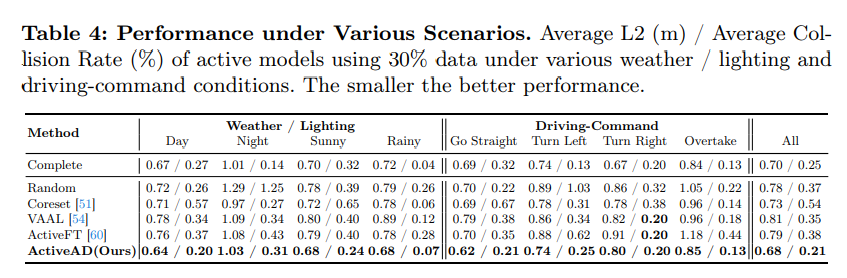
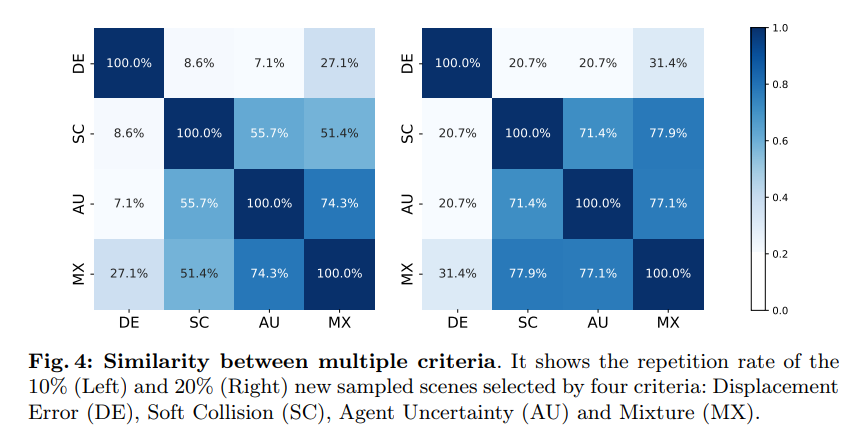
Figure 4: Similarity between multiple criteria. It shows the new sampling scenario with 10% (left) and 20% (right) selected by four criteria: Displacement Error (DE), Soft Collision (SC), Agent Uncertainty (AU) and Mixing (MX)
Some conclusions of this work
In order to solve the high cost and long-tail problems of end-to-end autonomous driving data annotation, we took the lead in developing a tailor-made active learning solution, ActiveAD. ActiveAD introduces new task-specific diversity and uncertainty measures based on a planning-oriented philosophy. A large number of experiments prove the effectiveness of the method. Using only 30% of the data, it significantly exceeds the general previous methods and achieves performance comparable to the state-of-the-art models. This represents a meaningful exploration of end-to-end autonomous driving from a data-centric perspective, and we hope that our work will inspire future research and discovery.
The above is the detailed content of What to do if there is no data end-to-end? ActiveAD: End-to-end active learning for autonomous driving for planning!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
The first pilot and key article mainly introduces several commonly used coordinate systems in autonomous driving technology, and how to complete the correlation and conversion between them, and finally build a unified environment model. The focus here is to understand the conversion from vehicle to camera rigid body (external parameters), camera to image conversion (internal parameters), and image to pixel unit conversion. The conversion from 3D to 2D will have corresponding distortion, translation, etc. Key points: The vehicle coordinate system and the camera body coordinate system need to be rewritten: the plane coordinate system and the pixel coordinate system. Difficulty: image distortion must be considered. Both de-distortion and distortion addition are compensated on the image plane. 2. Introduction There are four vision systems in total. Coordinate system: pixel plane coordinate system (u, v), image coordinate system (x, y), camera coordinate system () and world coordinate system (). There is a relationship between each coordinate system,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
