
 Technology peripherals
AI
New work by Yan Shuicheng/Cheng Mingming! DiT training, the core component of Sora, is accelerated by 10 times, and Masked Diffusion Transformer V2 is open source
Technology peripherals
AI
New work by Yan Shuicheng/Cheng Mingming! DiT training, the core component of Sora, is accelerated by 10 times, and Masked Diffusion Transformer V2 is open source
New work by Yan Shuicheng/Cheng Mingming! DiT training, the core component of Sora, is accelerated by 10 times, and Masked Diffusion Transformer V2 is open source

As one of Sora’s compelling core technologies, DiT utilizes Diffusion Transformer to scale the generative model to a larger scale to achieve outstanding image generation effects.
However, larger model sizes cause training costs to skyrocket.
The research team of Yan Shuicheng and Cheng Mingming from Sea AI Lab, Nankai University, and Kunlun Wanwei 2050 Research Institute proposed a new model called Masked Diffusion Transformer at the ICCV 2023 conference. This model uses mask modeling technology to speed up the training of Diffusion Transformer by learning semantic representation information, and achieves SoTA effects in the field of image generation. This innovation brings new breakthroughs to the development of image generation models and provides researchers with a more efficient training method. By combining expertise and technology from different fields, the research team successfully proposed a solution that increases training speed and improves generation results. Their work has contributed important innovative ideas to the development of the field of artificial intelligence and provided useful inspiration for future research and practice
 Picture
Picture
Paper address: https://arxiv.org/abs/2303.14389
GitHub address: https://github.com/sail-sg/MDT
Recently, Masked Diffusion Transformer V2 once again refreshed SoTA, increasing the training speed by more than 10 times compared to DiT, and achieving an FID score of 1.58 on the ImageNet benchmark.
The latest versions of papers and codes are open source.
Background
Although diffusion models represented by DiT have achieved significant success in the field of image generation, researchers have found that diffusion models often It is difficult to efficiently learn the semantic relationships between parts of objects in images, and this limitation leads to low convergence efficiency of the training process.
 Picture
Picture
For example, as shown in the picture above, DiT has learned at the 50kth training step Generate the dog's hair texture, and then learn to generate one of the dog's eyes and mouth at the 200k training step, but miss the other eye.
Even at the 300k training step, the relative position of the dog’s two ears generated by DiT is not very accurate.
This training and learning process reveals that the diffusion model fails to efficiently learn the semantic relationship between the various parts of the object in the image, but only learns the semantic information of each object independently.
The researchers speculate that the reason for this phenomenon is that the diffusion model learns the distribution of real image data by minimizing the prediction loss of each pixel. This process ignores the relationship between the various parts of the object in the image. The semantic relative relationship between them leads to the slow convergence speed of the model.
Method: Masked Diffusion Transformer
Inspired by the above observations, the researchers proposed the Masked Diffusion Transformer (MDT) to improve the training of diffusion models efficiency and build quality.
MDT proposes a mask modeling representation learning strategy designed for Diffusion Transformer to explicitly enhance Diffusion Transformer's learning ability of contextual semantic information and enhance the relationship between objects in the image Associative learning of semantic information.
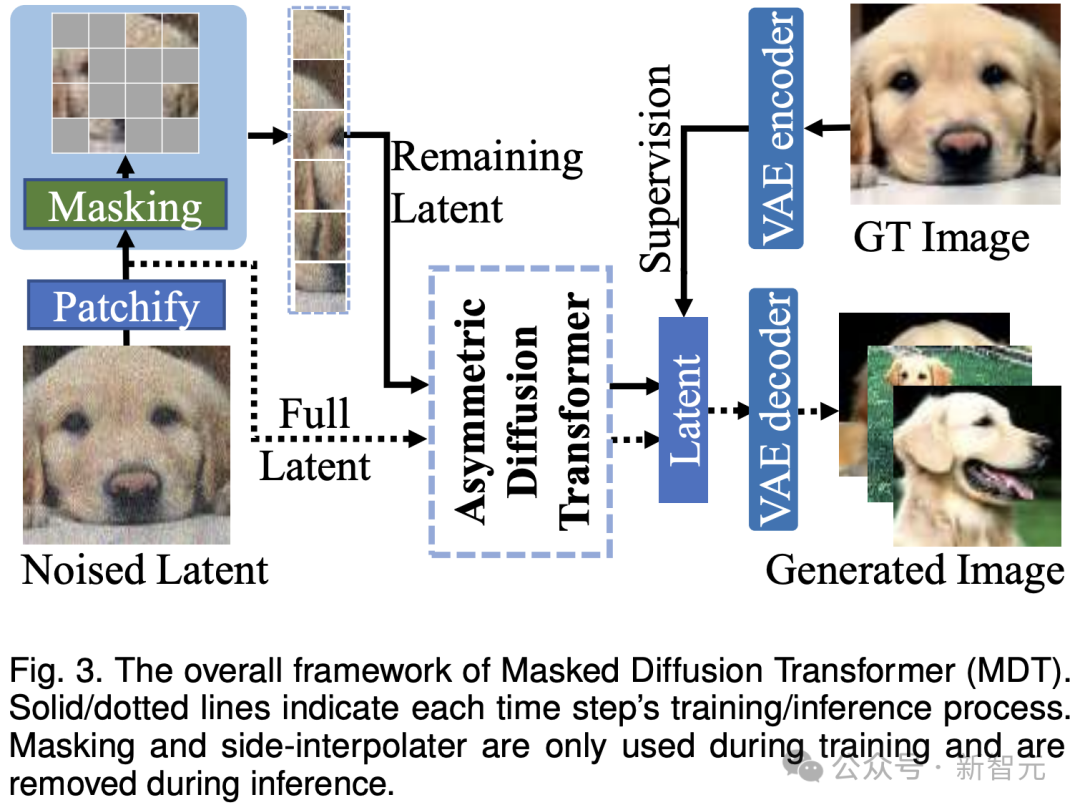 Picture
Picture
As shown in the figure above, MDT introduces mask modeling while maintaining the diffusion training process Learning Strategies. By masking the noisy image token, MDT uses an asymmetric Diffusion Transformer (Asymmetric Diffusion Transformer) architecture to predict the masked image token from the noisy image token that has not been masked, thereby simultaneously achieving the mask modeling and diffusion training processes.
During the inference process, MDT still maintains the standard diffusion generation process. The design of MDT helps Diffusion Transformer have both the semantic information expression ability brought by mask modeling representation learning and the diffusion model's ability to generate image details.
Specifically, MDT maps images to latent space through VAE encoder and processes them in latent space to save computing costs.
During the training process, MDT first masks out some of the noise-added image tokens, and sends the remaining tokens to the Asymmetric Diffusion Transformer to predict all image tokens after denoising.
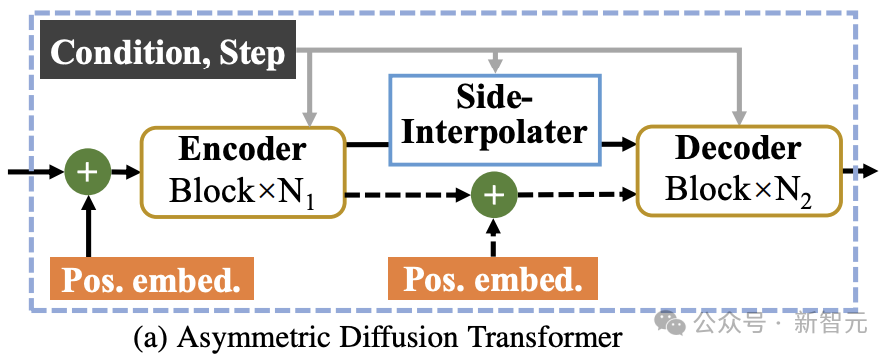
Asymmetric Diffusion Transformer Architecture
 ##Picture
##Picture
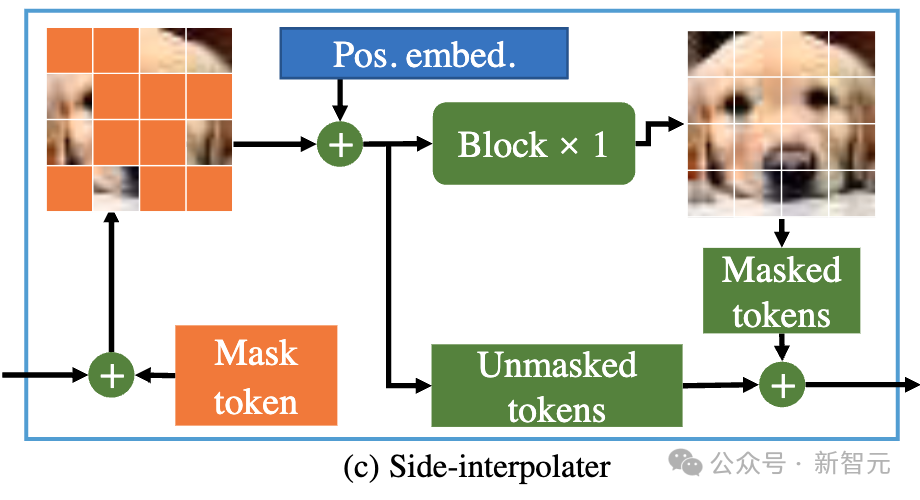 Picture
Picture
##Picture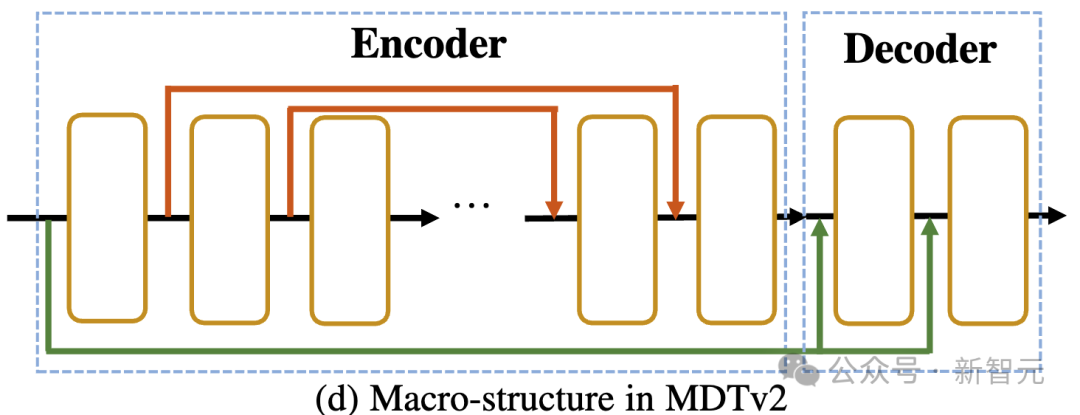
As shown in the figure above, MDTv2 further optimizes the learning process of diffusion and mask modeling by introducing a more efficient macro network structure designed for the Masked Diffusion process.
This includes integrating U-Net-style long-shortcut in the encoder and dense input-shortcut in the decoder.
Among them, dense input-shortcut will add noise to the masked token and send it to the decoder, retaining the noise information corresponding to the masked token, thus facilitating the training of the diffusion process. .
In addition, MDT has also introduced better training strategies including the faster Adan optimizer, time-step related loss weights, and expanded mask ratio to further accelerate Masked The training process of the Diffusion model.
Experimental results
ImageNet 256 benchmark generation quality comparison
Image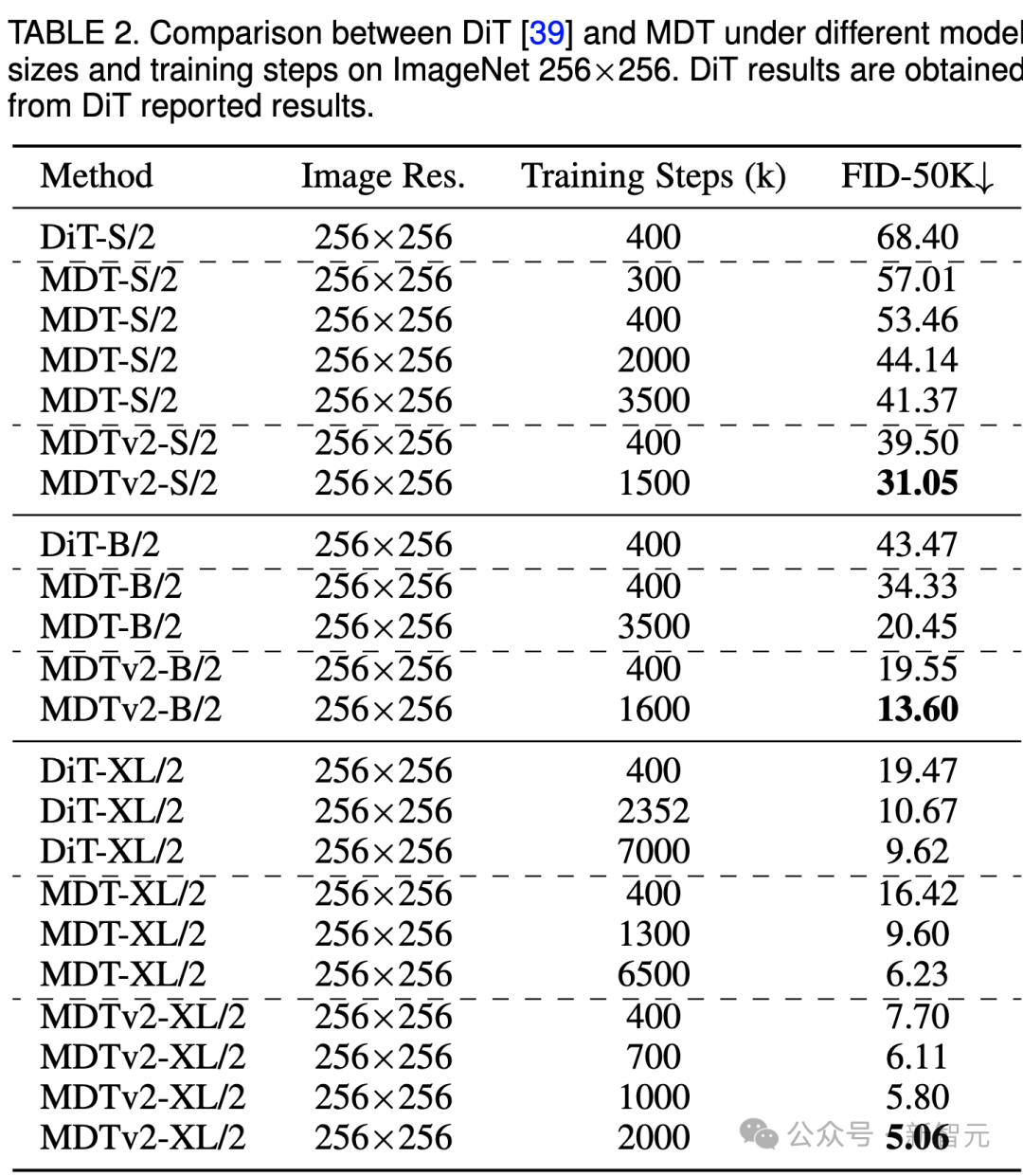
The above table compares the performance of MDT and DiT under different model sizes under the ImageNet 256 benchmark.
It is obvious that MDT achieves higher FID scores with less training cost at all model sizes.
The parameters and inference costs of MDT are basically the same as DiT, because as mentioned above, the standard diffusion process consistent with DiT is still maintained during the inference process of MDT.
For the largest XL model, MDTv2-XL/2 trained with 400k steps significantly outperforms DiT-XL/2 trained with 7000k steps, with a FID score improvement of 1.92. Under this setting, the results show that MDT has about 18 times faster training than DiT.
For small models, MDTv2-S/2 still achieves significantly better performance than DiT-S/2 with significantly fewer training steps. For example, with the same training of 400k steps, MDTv2 has an FID index of 39.50, which is significantly ahead of DiT's FID index of 68.40.
More importantly, this result also exceeds the performance of the larger model DiT-B/2 at 400k training steps (39.50 vs 43.47).
ImageNet 256 benchmark CFG generation quality comparison
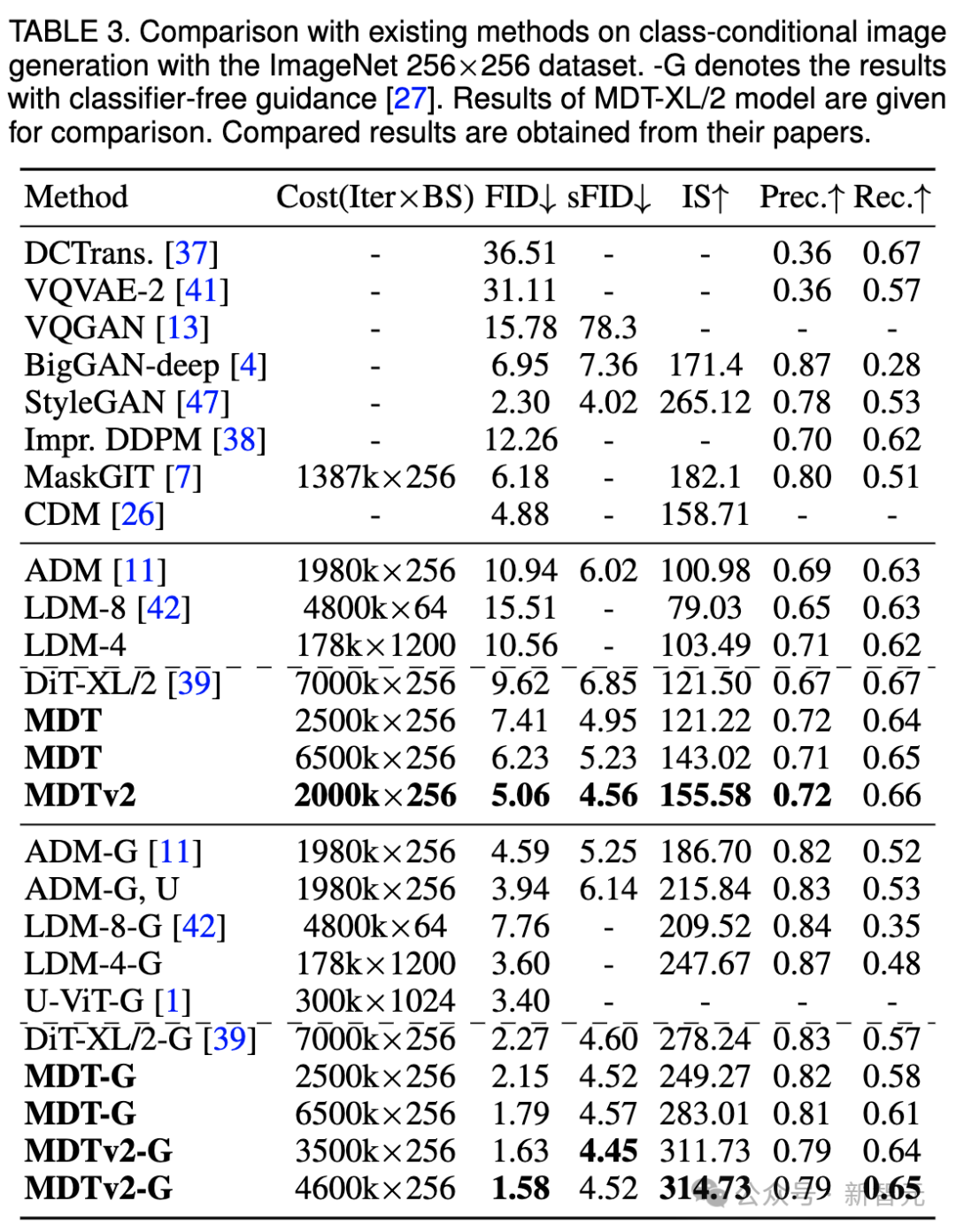 Image
Image
We are still here The above table compares the image generation performance of MDT and existing methods under classifier-free guidance.
MDT surpasses previous SOTA DiT and other methods with an FID score of 1.79. MDTv2 further improves performance, pushing the SOTA FID score for image generation to a new low of 1.58 with fewer training steps.
Similar to DiT, we did not observe saturation of the model’s FID scores during training as we continued training.
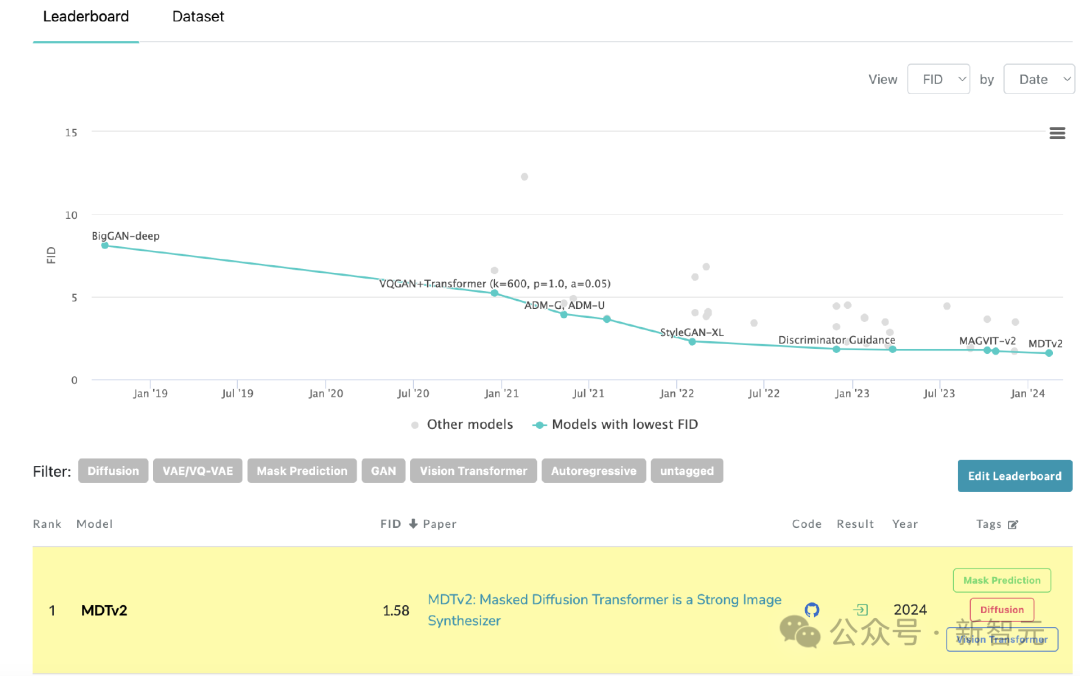 MDT refreshes SoTA on PaperWithCode’s leaderboard
MDT refreshes SoTA on PaperWithCode’s leaderboard
Convergence speed comparison
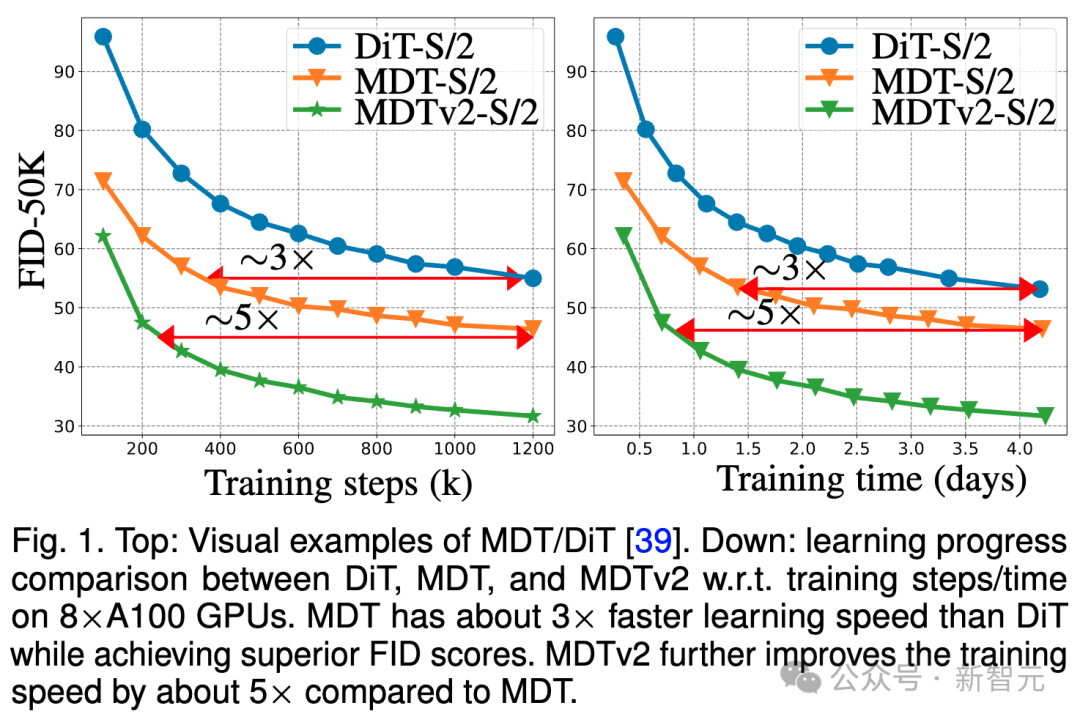 Picture
Picture
The above picture compares the DiT-S/2 baseline, MDT-S/2 and MDTv2 on the 8×A100 GPU under the ImageNet 256 benchmark. - FID performance of S/2 under different training steps/training times.
Thanks to its better contextual learning capabilities, MDT surpasses DiT in both performance and generation speed. The training convergence speed of MDTv2 is more than 10 times higher than that of DiT.
MDT is about 3 times faster than DiT in terms of training steps and training time. MDTv2 further improves the training speed by approximately 5 times compared to MDT.
For example, MDTv2-S/2 shows better performance in just 13 hours (15k steps) than DiT-S/2 which takes about 100 hours (1500k steps) to train , which reveals that context representation learning is crucial for faster generative learning of diffusion models.
Summary & Discussion
MDT can utilize the characteristics of image objects by introducing a mask modeling representation learning scheme similar to MAE in the diffusion training process. Context information reconstructs the complete information of incomplete input images, thereby learning the correlation between semantic parts in the image, thereby improving the quality and learning speed of image generation.
Researchers believe that enhancing the semantic understanding of the physical world through visual representation learning can improve the simulation effect of the generative model on the physical world. This coincides with Sora's vision of building a physical world simulator through generative models. Hopefully this work will inspire more work on unifying representation learning and generative learning.
Reference:
https://arxiv.org/abs/2303.14389
The above is the detailed content of New work by Yan Shuicheng/Cheng Mingming! DiT training, the core component of Sora, is accelerated by 10 times, and Masked Diffusion Transformer V2 is open source. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Introduction to how to use the joiplay simulator
May 04, 2024 pm 06:40 PM
Introduction to how to use the joiplay simulator
May 04, 2024 pm 06:40 PM
The jojplay simulator is a very easy-to-use mobile phone simulator. It supports computer games to run on mobile phones and has very good compatibility. Some players don’t know how to use it. The editor below will introduce how to use it. How to use joiplay simulator 1. First, you need to download the Joiplay body and RPGM plug-in. It is best to install them in the order of body-plug-in. The apk package can be obtained in the Joiplay bar (click to get >>>). 2. After Android is completed, you can add games in the lower left corner. 3. Fill in the name casually, and press CHOOSE on executablefile to select the game.exe file of the game. 4. Icon can be left blank or you can choose your favorite picture.
 How to enable vt on MSI motherboard
May 01, 2024 am 09:28 AM
How to enable vt on MSI motherboard
May 01, 2024 am 09:28 AM
How to enable VT on MSI motherboard? What are the methods? This website has carefully compiled the MSI motherboard VT enable methods for the majority of users. Welcome to read and share! The first step is to restart the computer and enter the BIOS. What should I do if the startup speed is too fast and I cannot enter the BIOS? After the screen lights up, keep pressing "Del" to enter the BIOS page. The second step is to find the VT option in the menu and turn it on. Different models of computers have different BIOS interfaces and different names for VT. Situation 1: 1. Enter After entering the BIOS page, find the "OC (or overclocking)" - "CPU Features" - "SVMMode (or Intel Virtualization Technology)" option and change the "Disabled"
 How to enable vt on ASRock motherboard
May 01, 2024 am 08:49 AM
How to enable vt on ASRock motherboard
May 01, 2024 am 08:49 AM
How to enable VT on ASRock motherboard, what are the methods and how to operate it. This website has compiled the ASRock motherboard vt enable method for users to read and share! The first step is to restart the computer. After the screen lights up, keep pressing the "F2" key to enter the BIOS page. What should I do if the startup speed is too fast and I cannot enter the BIOS? The second step is to find the VT option in the menu and turn it on. Different models of motherboards have different BIOS interfaces and different names for VT. 1. After entering the BIOS page, find "Advanced" - "CPU Configuration (CPU) Configuration)" - "SVMMOD (virtualization technology)" option, change "Disabled" to "Enabled"
 Recommended Android emulator that is smoother (choose the Android emulator you want to use)
Apr 21, 2024 pm 06:01 PM
Recommended Android emulator that is smoother (choose the Android emulator you want to use)
Apr 21, 2024 pm 06:01 PM
It can provide users with a better gaming experience and usage experience. An Android emulator is a software that can simulate the running of the Android system on a computer. There are many kinds of Android emulators on the market, and their quality varies, however. To help readers choose the emulator that suits them best, this article will focus on some smooth and easy-to-use Android emulators. 1. BlueStacks: Fast running speed. With excellent running speed and smooth user experience, BlueStacks is a popular Android emulator. Allowing users to play a variety of mobile games and applications, it can simulate Android systems on computers with extremely high performance. 2. NoxPlayer: Supports multiple openings, making it more enjoyable to play games. You can run different games in multiple emulators at the same time. It supports
 How to install Windows system on tablet computer
May 03, 2024 pm 01:04 PM
How to install Windows system on tablet computer
May 03, 2024 pm 01:04 PM
How to flash the Windows system on BBK tablet? The first way is to install the system on the hard disk. As long as the computer system does not crash, you can enter the system and download things, you can use the computer hard drive to install the system. The method is as follows: Depending on your computer configuration, you can install the WIN7 operating system. We choose to download Xiaobai's one-click reinstallation system in vivopad to install it. First, select the system version suitable for your computer, and click "Install this system" to next step. Then we wait patiently for the installation resources to be downloaded, and then wait for the environment to be deployed and restarted. The steps to install win11 on vivopad are: first use the software to check whether win11 can be installed. After passing the system detection, enter the system settings. Select the Update & Security option there. Click
 Life Restart Simulator Guide
May 07, 2024 pm 05:28 PM
Life Restart Simulator Guide
May 07, 2024 pm 05:28 PM
Life Restart Simulator is a very interesting simulation game. This game has become very popular recently. There are many ways to play in the game. Below, the editor has brought you a complete guide to Life Restart Simulator. Come and take a look. What strategies are there? Life Restart Simulator Guide Guide Features of Life Restart Simulator This is a very creative game in which players can play according to their own ideas. There are many tasks to complete every day, and you can enjoy a new life in this virtual world. There are many songs in the game, and all kinds of different lives are waiting for you to experience. Life Restart Simulator Game Contents Talent Card Drawing: Talent: You must choose the mysterious small box to become an immortal. A variety of small capsules are available to avoid dying midway. Cthulhu may choose
 How to package pycharm into apk
Apr 18, 2024 am 05:57 AM
How to package pycharm into apk
Apr 18, 2024 am 05:57 AM
How to package an Android app as an APK using PyCharm? Make sure the project is connected to an Android device or emulator. Configure build type: Add a build type and check "Generate signed APK". Click "Build APK" in the build toolbar, select your build type and start building.
 Introduction to joiplay simulator font setting method
May 09, 2024 am 08:31 AM
Introduction to joiplay simulator font setting method
May 09, 2024 am 08:31 AM
The jojplay simulator can actually customize the game fonts, and can solve the problem of missing characters and boxed characters in the text. I guess many players still don’t know how to operate it. The following editor will bring you the method of setting the font of the jojplay simulator. introduce. How to set the joiplay simulator font 1. First open the joiplay simulator, click on the settings (three dots) in the upper right corner, and find it. 2. In the RPGMSettings column, click to select the CustomFont custom font in the third row. 3. Select the font file and click OK. Be careful not to click the "Save" icon in the lower right corner, otherwise the default settings will be restored. 4. Recommended Founder and Quasi-Yuan Simplified Chinese (already in the folders of the games Fuxing and Rebirth). joi
