
 Technology peripherals
AI
Further accelerating implementation: compressing the end-to-end motion planning model of autonomous driving
Technology peripherals
AI
Further accelerating implementation: compressing the end-to-end motion planning model of autonomous driving
Further accelerating implementation: compressing the end-to-end motion planning model of autonomous driving

Original title: On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Paper link: https://arxiv.org/pdf/2403.01238.pdf
Code link: https://github.com/tulerfeng/PlanKD
Author affiliation: Beijing Institute of Technology ALLRIDE.AI Hebei Provincial Key Laboratory of Big Data Science and Intelligent Technology

Thesis Idea
The end-to-end motion planning model is equipped with a deep neural network and has shown great potential in realizing fully autonomous driving. However, overly large neural networks make them unsuitable for deployment on resource-constrained systems, which undoubtedly require more computing time and resources. To address this problem, knowledge distillation offers a promising approach by compressing models by having a smaller student model learn from a larger teacher model. Nonetheless, how to apply knowledge distillation to compress motion planners has so far been unexplored. This paper proposes PlanKD, the first knowledge distillation framework tailored for compressed end-to-end motion planners. First, given that driving scenarios are inherently complex and often contain information that is irrelevant to planning or even noisy, transferring this information would not be beneficial to the student planner. Therefore, this paper designs a strategy based on information bottleneck, which only distills planning-related information instead of migrating all information indiscriminately. Second, different waypoints in the output planned trajectory may vary in importance to motion planning, and slight deviations in some critical waypoints may lead to collisions. Therefore, this paper designs a safety-aware waypoint-attentive distillation module to assign adaptive weights to different waypoints based on importance to encourage student models to imitate more critical waypoints more accurately, thereby improving overall safety. Experiments show that our PlanKD can significantly improve the performance of small planners and significantly reduce their reference time.
Main Contributions:
- This paper constructs the first attempt to explore dedicated knowledge distillation methods to compress end-to-end motion planners in autonomous driving.
- This paper proposes a general and innovative framework PlanKD, which enables student planners to inherit planning-related knowledge in the middle layer and facilitates accurate matching of key waypoints to improve safety. .
- Experiments show that PlanKD in this article can significantly improve the performance of small planners, thereby providing a more portable and efficient solution for deployment with limited resources.
Network Design:
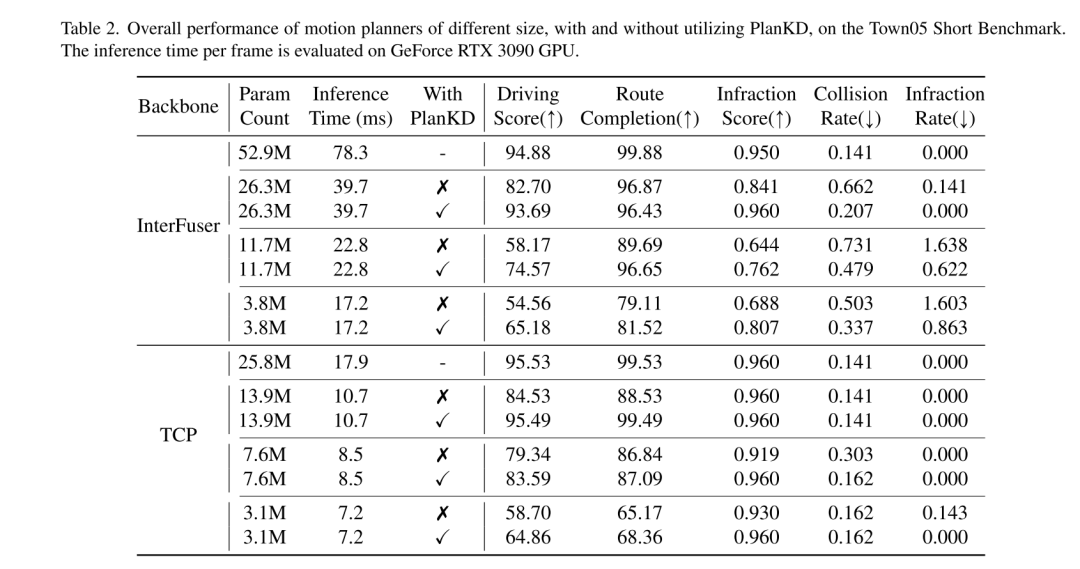
End-to-end motion planning has recently emerged as a promising direction in autonomous driving [3, 10, 30, 31, 40, 47, 48], which directly maps raw sensor data to planned actions. This learning-based paradigm exhibits the advantages of reducing heavy reliance on hand-crafted rules and mitigating error accumulation within complex cascade modules (usually detection-tracking-prediction-planning) [40, 48]. Despite their success, the bulky architecture of deep neural networks in motion planners poses challenges for deployment in resource-constrained environments, such as autonomous delivery robots that rely on the computing power of edge devices. Furthermore, even in conventional vehicles, computing resources on-board devices are often limited [34]. Therefore, directly deploying deep and large planners inevitably requires more computing time and resources, which makes it challenging to respond quickly to potential hazards. To alleviate this problem, a straightforward approach is to reduce the number of network parameters by using a smaller backbone network, but this paper observes that the performance of the end-to-end planning model will drop sharply, as shown in Figure 1. For example, although the inference time of InterFuser [33], a typical end-to-end motion planner, was reduced from 52.9M to 26.3M, its driving score also dropped from 53.44 to 36.55. Therefore, it is necessary to develop a model compression method suitable for end-to-end motion planning.
In order to obtain a portable motion planner, this article uses knowledge distillation [19] to compress the end-to-end motion planning model. Knowledge distillation (KD) has been widely studied for model compression in various tasks, such as object detection [6, 24], semantic segmentation [18, 28], etc. The basic idea of these works is to train a simplified student model by inheriting knowledge from a larger teacher model and use the student model to replace the teacher model during deployment. While these studies have achieved significant success, directly applying them to end-to-end motion planning leads to suboptimal results. This stems from two emerging challenges inherent in motion planning tasks: (i) Driving scenarios are complex in nature [46], involving multiple dynamic and static objects, complex background scenes, and multifaceted roads and traffic Diverse information including information. However, not all of this information is useful for planning. For example, background buildings and distant vehicles are irrelevant or even noisy to planning [41], while nearby vehicles and traffic lights have a deterministic impact. Therefore, it is crucial to automatically extract only planning-relevant information from the teacher model, which previous KD methods cannot achieve. (ii) Different waypoints in the output planning trajectory usually have different importance for motion planning. For example, when navigating an intersection, waypoints in a trajectory that are close to other vehicles may have higher importance than other waypoints. This is because at these points, the self-vehicle needs to actively interact with other vehicles, and even small deviations can lead to collisions. However, how to adaptively determine key waypoints and accurately imitate them is another significant challenge of previous KD methods.
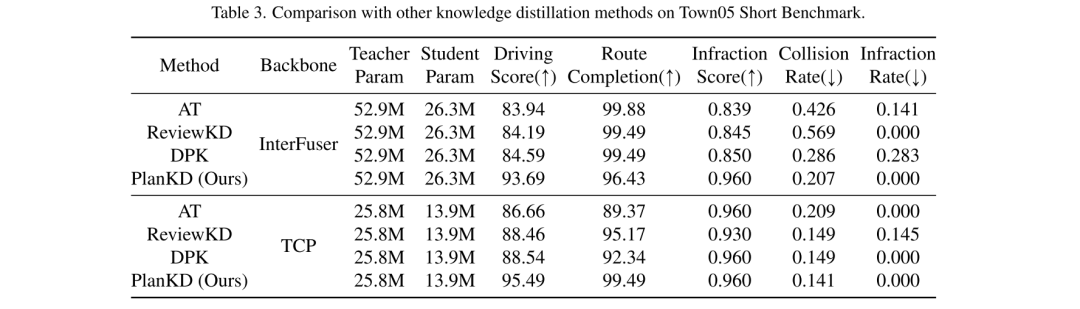
To address the above two challenges, this paper proposes the first knowledge distillation method tailored for end-to-end motion planners in compressed autonomous driving, called PlanKD. First, this paper proposes a strategy based on the information bottleneck principle [2], whose goal is to extract planning-related features that contain minimal and sufficient planning information. Specifically, this paper maximizes the mutual information between the extracted planning-related features and the true value of the planning state defined in this paper, while minimizing the mutual information between the extracted features and intermediate feature maps. This strategy enables this paper to extract key planning-relevant information only at the middle layer, thereby enhancing the effectiveness of the student model. Second, in order to dynamically identify key waypoints and imitate them faithfully, this paper adopts an attention mechanism [38] to calculate each waypoint and its attention weight between it and the associated context in the bird's-eye view (BEV). To promote accurate imitation of safety-critical waypoints during distillation, we design a safety-aware ranking loss that encourages giving higher attention weight to waypoints close to moving obstacles. Accordingly, the security of student planners can be significantly enhanced. The evidence shown in Figure 1 shows that the driving score of student planners can be significantly improved with our PlanKD. Furthermore, our method can reduce the reference time by about 50% while maintaining comparable performance to the teacher planner on the Town05 Long Benchmark.
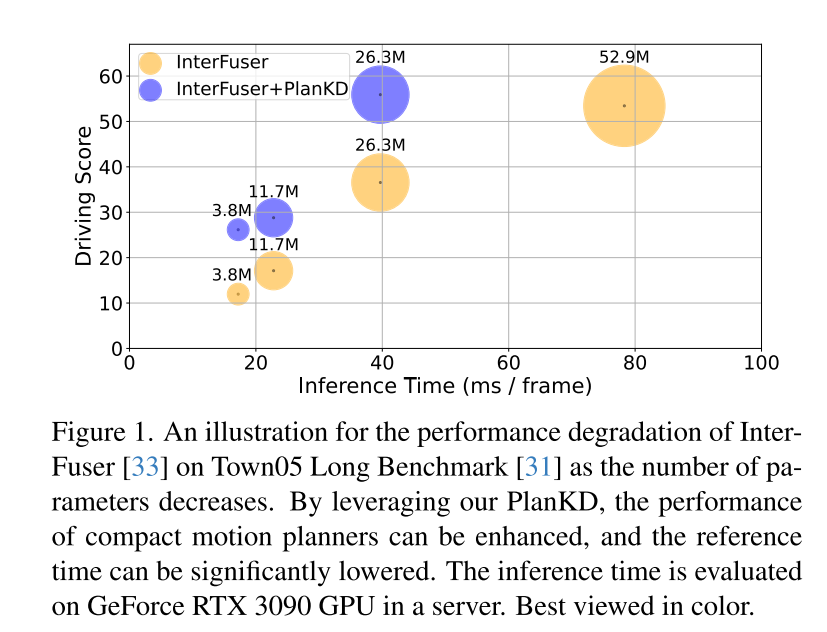
Figure 1. Schematic diagram of the performance degradation of InterFuser[33] as the number of parameters decreases on Town05 Long Benchmark [31]. By leveraging our PlanKD, we can improve the performance of compact motion planners and significantly reduce reference times. Inference times are evaluated on a GeForce RTX 3090 GPU on the server.
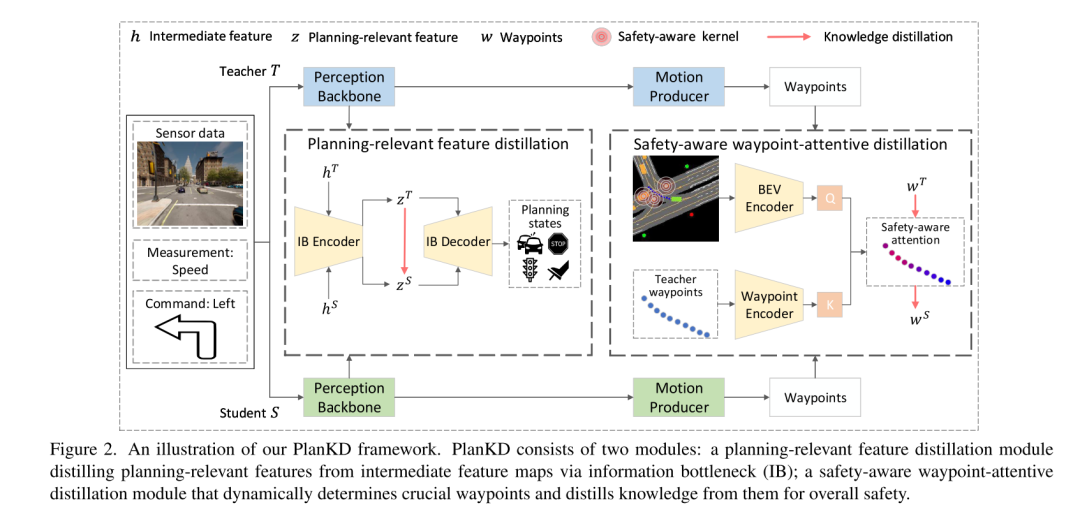
Figure 2. Schematic diagram of the PlanKD framework of this article. PlanKD consists of two modules: a planning-related feature distillation module that extracts planning-related features from intermediate feature maps through information bottlenecks (IB); a safety-aware waypoint-attentive distillation module that dynamically determines key waypoints and Extract knowledge from it to enhance overall security.
Experimental results:
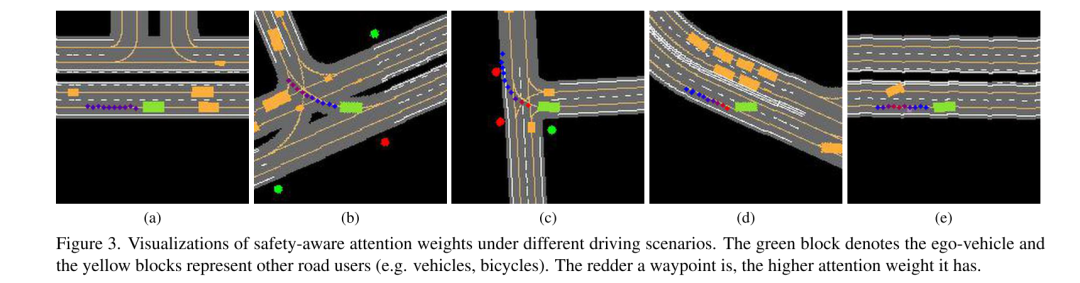
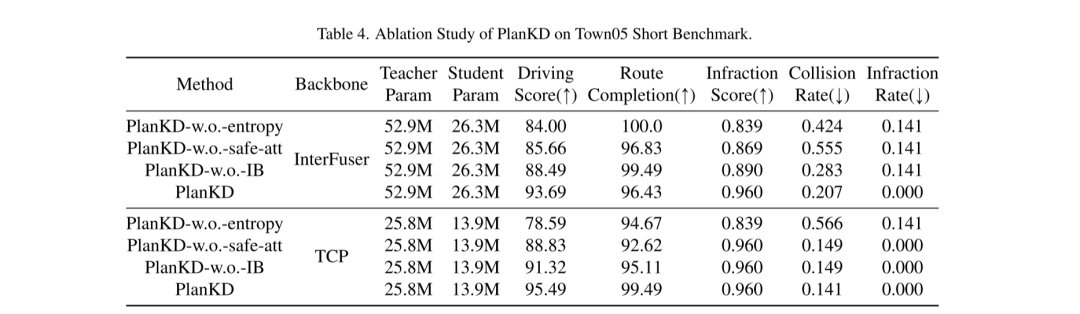
Figure 3. Visualization of safety-aware attention weights in different driving scenarios. The green blocks represent the ego-vehicle and the yellow blocks represent other road users (e.g. cars, bicycles). The redder a waypoint is, the higher its attention weight.
Summary:
This paper proposes PlanKD, a knowledge distillation method tailored for compressed end-to-end motion planners. The proposed method can learn planning-related features through information bottlenecks to achieve effective feature distillation. Furthermore, this paper designs a safety-aware waypoint-attentive distillation mechanism to adaptively decide the importance of each waypoint for waypoint distillation. Extensive experiments validate the effectiveness of our approach, demonstrating that PlanKD can serve as a portable and secure solution for resource-limited deployments.
Citation:
Feng K, Li C, Ren D, et al. On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving[ J]. arXiv preprint arXiv:2403.01238, 2024.
The above is the detailed content of Further accelerating implementation: compressing the end-to-end motion planning model of autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
