

Born for autonomous driving, Lightning NeRF: 10 times faster

Written before&The author’s personal understanding
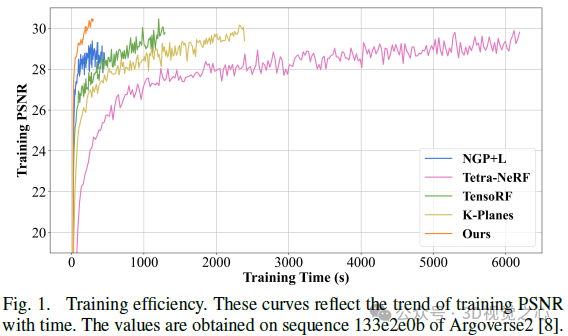
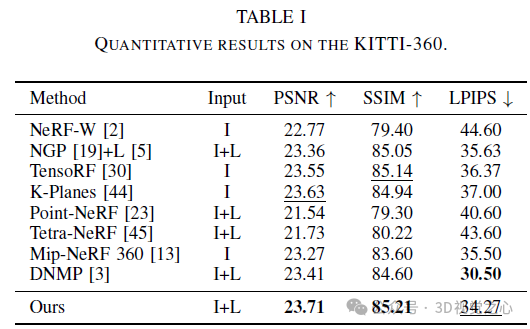
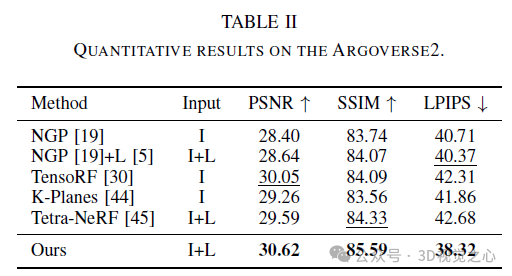
Recent research has emphasized the application prospects of NeRF in autonomous driving environments. However, the complexity of outdoor environments, coupled with restricted viewpoints in driving scenes, complicates the task of accurately reconstructing scene geometry. These challenges often result in reduced reconstruction quality and longer training and rendering durations. To address these challenges, we launched Lightning NeRF. It uses an efficient hybrid scene representation that effectively exploits lidar's geometric priors in autonomous driving scenarios. Lightning NeRF significantly improves NeRF's novel view synthesis performance and reduces computational overhead. Through evaluation on real-world datasets such as KITTI-360, Argoverse2, and our private dataset, we demonstrate that our method not only surpasses the current state-of-the-art in new view synthesis quality, but also improves in training speed Five times faster, and ten times faster rendering.
- Code link: https://github.com/VISION-SJTU/Lightning-NeRF
Detailed explanation of Lightning NeRF
Preliminaries
NeRF is a method of representing scenarios with implicit functions. This implicit Functions are usually parameterized by MLP. It is able to return the color value c and volume density prediction σ of a 3D point x in the scene based on the viewing direction d.
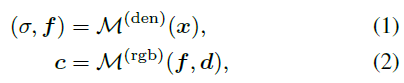
To render pixels, NeRF uses hierarchical volume sampling to generate a series of points along a ray r, and then combines the predicted density and color features at these locations through accumulation.
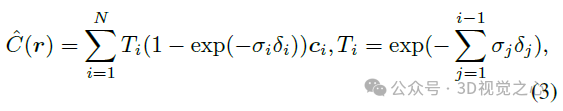
Although NeRF performs well in new perspective synthesis, its long training time and slow rendering speed are mainly caused by the inefficiency of the sampling strategy. To improve the model's efficiency, we maintain a coarse grid occupancy during training and only sample locations within the occupied volume. This sampling strategy is similar to existing work and helps improve model performance and speed up training.
Hybrid Scene Representation
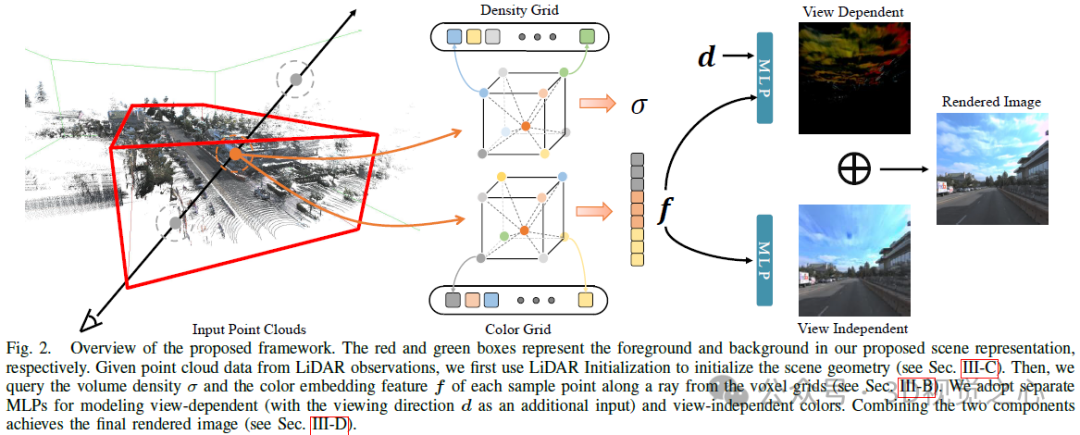
Hybrid volume representation has been optimized and rendered quickly using compact models. Given this, we adopt a hybrid voxel grid representation to model the radiation field to improve efficiency. Briefly, we explicitly model the volumetric density by storing σ at the mesh vertices, while using a shallow MLP to implicitly decode the color embedding f into the final color c. To handle the boundaryless nature of outdoor environments, we divide the scene representation into two parts, foreground and background, as shown in Figure 2. Specifically, we examine the camera frustum in each frame from the trajectory sequence and define the foreground bounding box such that it tightly wraps all frustums in the aligned coordinate system. The background box is obtained by scaling up the foreground box along each dimension.
Voxel grid representation. A voxel mesh representation explicitly stores scene properties (e.g., density, RGB color, or features) in its mesh vertices to support efficient feature queries. This way, for a given 3D position, we can decode the corresponding attribute via trilinear interpolation:
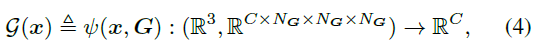
Foreground. We build two independent feature grids to model the density and color embedding of the foreground region. Specifically, density mesh mapping maps positions into a density scalar σ for volumetric rendering. For color-embedded mesh mapping, we instantiate multiple voxel meshes at different resolution backups via hash tables to obtain finer details with affordable memory overhead. The final color embedding f is obtained by concatenating the outputs at L resolution levels.
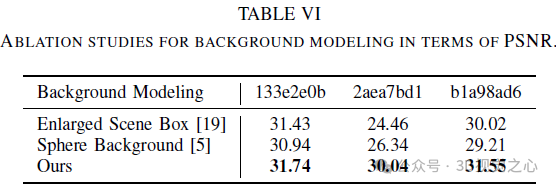
Background Although the foreground modeling mentioned previously works for object-level radiation fields, extending it to unbounded outdoor scenes is not trivial. Some related techniques, such as NGP, directly extend their scene bounding box so that the background area can be included, while GANcraft and URF introduce spherical background radiation to deal with this problem. However, the former attempt resulted in a waste of its functionality since most of the area within its scene box was used for the background scene. For the latter scheme, it may not be able to handle complex panoramas in urban scenes (e.g., undulating buildings or complex landscapes) because it simply assumes that the background radiation depends only on the view direction.
For this, we set up an additional background mesh model to keep the resolution of the foreground part unchanged. We adopt the scene parameterization in [9] as the background, which is carefully designed. First, unlike inverse spherical modeling, we use inverse cubic modeling, with ℓ∞ norm, since we use voxel grid representation. Secondly we do not instantiate additional MLP to query the background color to save memory. Specifically, we warp 3D background points into 4D by:
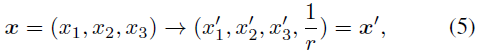
LiDAR Initialization
Using our blending scene Representation, this model saves computation and memory when we query density values directly from an efficient voxel grid representation instead of a computationally intensive MLP. However, given the large-scale nature and complexity of urban scenes, this lightweight representation can easily get stuck in local minima during optimization due to the limited resolution of the density grid. Fortunately, in autonomous driving, most self-driving vehicles (SDVs) are equipped with LiDAR sensors, which provide rough geometric priors for scene reconstruction. To this end, we propose to use lidar point clouds to initialize our density mesh to alleviate the obstacles of joint optimization of scene geometry and radioactivity.
Color Decomposition
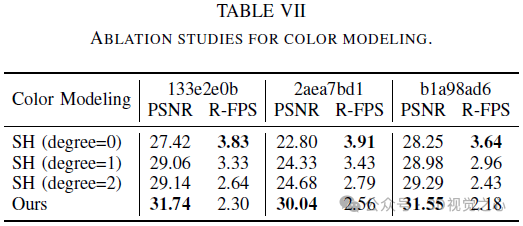
The original NeRF used a view-dependent MLP to model color in a radiation field, a simplification of the physical world where radiation Consists of diffuse (view-independent) color and specular (view-dependent) color. Furthermore, since the final output color c is completely entangled with the viewing direction d, it is difficult to render high-fidelity images in unseen views. As shown in Figure 3, our method trained without color decomposition (CD) fails at new view synthesis in the extrapolation setting (i.e., shifting the viewing direction 2 meters to the left based on the training view), while our method in color The decomposed case gives reasonable rendering results.

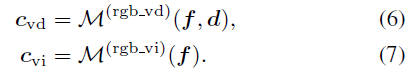
The final color at the sample location is the sum of these two factors:

Training Loss
We modify the photometric loss using rescaled weights wi to optimize our model to focus on hard samples for fast convergence. The weight coefficient is defined as:

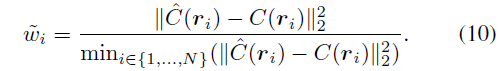
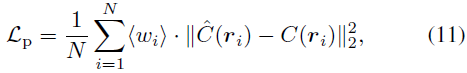 ##Picture
##Picture
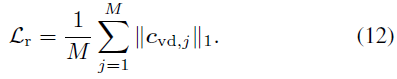

experiment
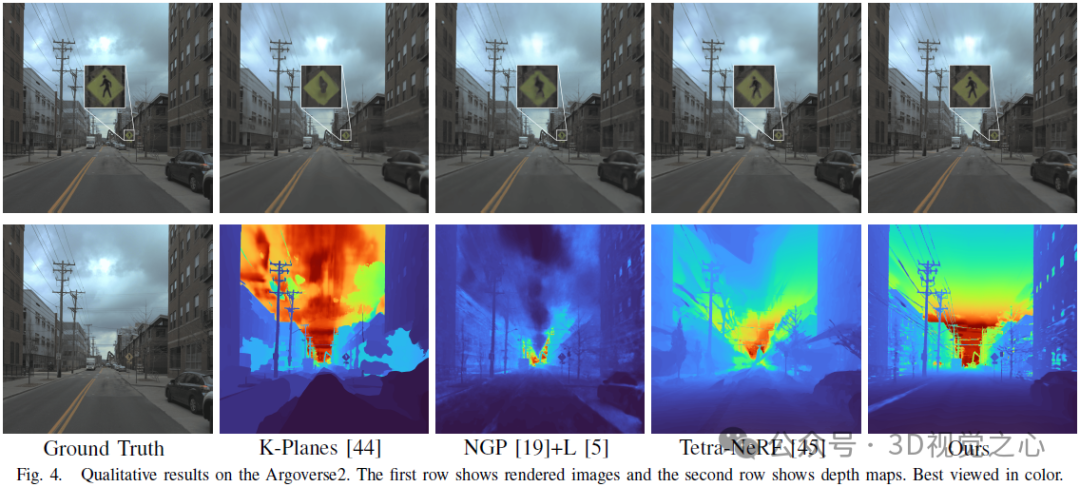
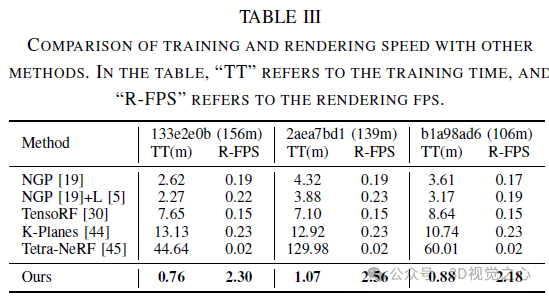
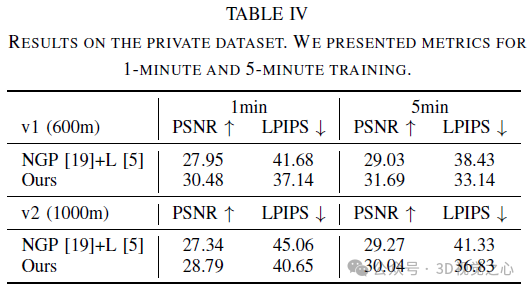

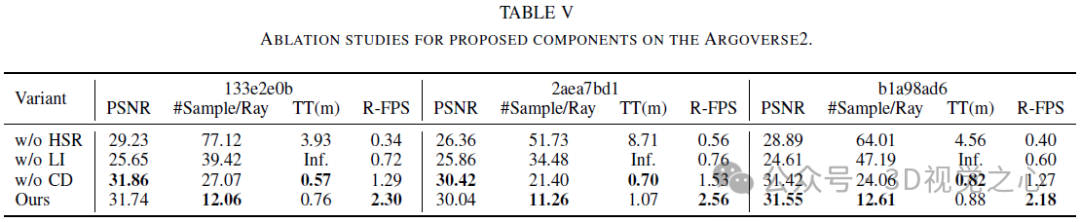
Conclusion
This paper introduces Lightning NeRF, an efficient outdoor scene view synthesis framework that integrates point clouds and images. The proposed method leverages point clouds to quickly initialize a sparse representation of the scene, achieving significant performance and speed enhancements. By modeling the background more efficiently, we reduce the representational strain on the foreground. Finally, through color decomposition, view-related and view-independent colors are modeled separately, which enhances the extrapolation ability of the model. Extensive experiments on various autonomous driving datasets demonstrate that our method outperforms previous state-of-the-art techniques in terms of performance and efficiency.
The above is the detailed content of Born for autonomous driving, Lightning NeRF: 10 times faster. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
The first pilot and key article mainly introduces several commonly used coordinate systems in autonomous driving technology, and how to complete the correlation and conversion between them, and finally build a unified environment model. The focus here is to understand the conversion from vehicle to camera rigid body (external parameters), camera to image conversion (internal parameters), and image to pixel unit conversion. The conversion from 3D to 2D will have corresponding distortion, translation, etc. Key points: The vehicle coordinate system and the camera body coordinate system need to be rewritten: the plane coordinate system and the pixel coordinate system. Difficulty: image distortion must be considered. Both de-distortion and distortion addition are compensated on the image plane. 2. Introduction There are four vision systems in total. Coordinate system: pixel plane coordinate system (u, v), image coordinate system (x, y), camera coordinate system () and world coordinate system (). There is a relationship between each coordinate system,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
