

Use ddrescue to recover data on Linux

DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other main functions of DDREASE are as follows:
- It will not overwrite the recovered data but will fill in the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly.
- Recover data from multiple files or blocks to a single file.
- Supports multiple types of device interfaces, such as SATA, ATA, SCSI, MFM drives, floppy disks and SD cards.
In this guide, I will take an in-depth look at this powerful data recovery tool, discussing its installation steps and how to use it to recover block devices or partitions.
- Install ddrescue
- Understand the basics
- Important considerations
- Use DDREASE
- Repair corrupted blocks
- Restore image file to new blocks
- Restore data block to another data block
- Recover specific data from saved image files
- Advanced Features
- How ddrescue works
- in conclusion
Please note: In this guide, I am using a Linux distribution (Ubuntu 22.04). The installation steps for the Ddreasure utility may vary depending on the distribution, but the guidelines are universal for all Linux distributions.
Install ddrescue
To install ddrescue on Linux, especially Ubuntu and its versions or Debian-based distributions, use: Purpose:
sudo apt install gddrescue
To install it on REHL, Fedora and CentOS, first enable ETEL (Extra Packages for Enterprise Linux).
sudo yum install epel—release
The above commands are applicable to newer versions of the respective distributions.
Then execute the following command to install ddreasue:
sudo yum install ddrescue
For Arch-Linux based distributions like Arch-Linux and Manjaro, please install the ddrescue recovery utility using the command given below.
sudo pacman—S ddrescue
Since I am using Ubuntu 22.04, I will use the APT package manager to install it.
Understand the basics
Before using the ddreasue tool to recover data, I recommend that users who are not familiar with the recovery process understand some naming conventions of Linux.
Linux recognizes blocks (devices) as files and places them in the /dev directory. To list the files in the /dev directory, use the ls/dev command.
Hard drives (storage blocks) are represented by sd and the alphabet; in the case of multiple storage devices, the files will be represented as /dev/sda, /dev/sdb, etc.
If the storage device has partitions, they will be represented by numbers with corresponding drive file names, such as /dev/sda1, /dev/sda2, etc.
To list all blocks and other connected devices in the system, use the list block lsblk command:
lsblk
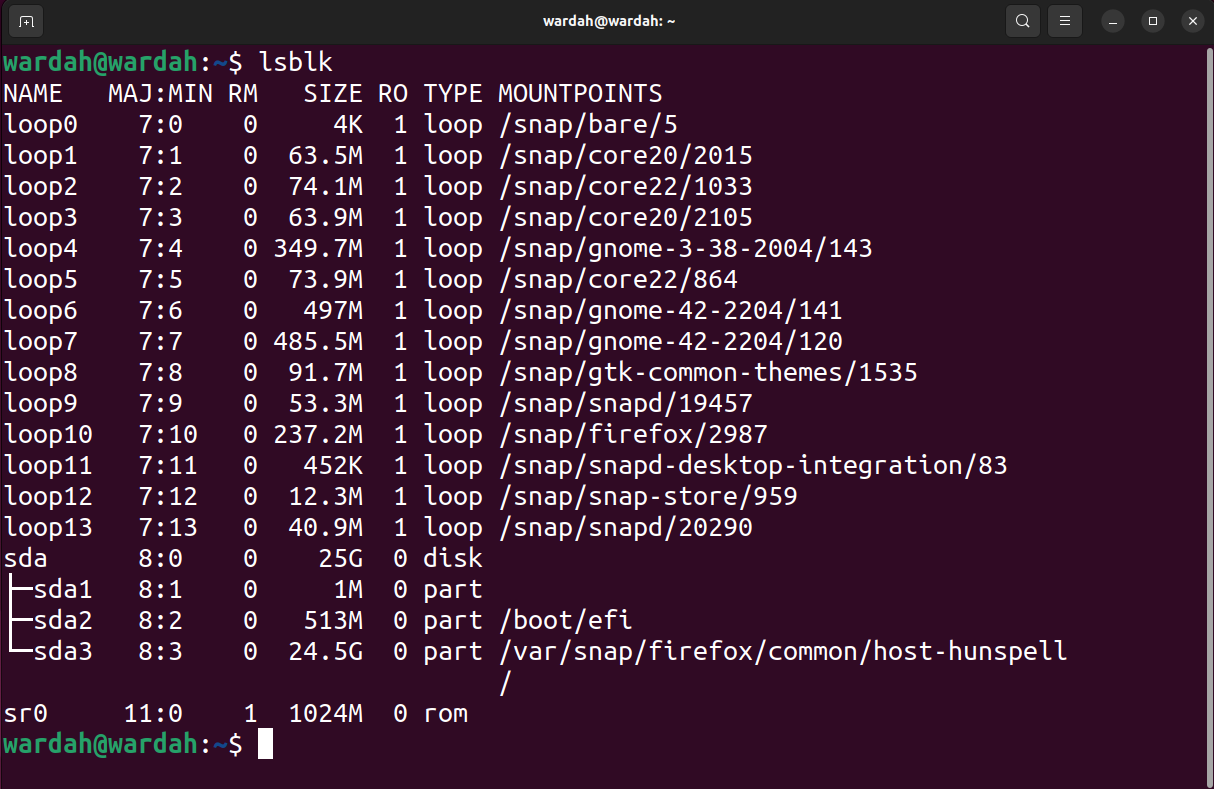
ddrescue command can recover the entire block (including MBR and partition) or partition. On the other hand, if you only need to recover specific files from a specific partition, then it is better to recover the partition rather than the entire block.
Important considerations
Before using the ddue utility, there are some very critical issues that should be considered:
- Do not attempt to recover a mounted data block, which should not even be in read-only mode.
- Do not attempt to repair a data block with an I/O error.
- The system can change input and output device names on reboot. Before starting the copy process, make sure the device name is correct.
- If you use a separate block as the output device, all data on the device will be overwritten.
Use ddrescue
After installing the ddrescue utility and understanding the naming convention, the next step is to identify the failed disk and use the ddrescue tool to recover it.
Repair corrupted blocks
The first example will contain the process of recovering the entire block. First, list the blocks using the lsblk command:
lsblk—o Name, Size, FSTYPE
—The o flag is used to specify what type of information (field) the command should output. I have mentioned name, size and FSTYPE or file system type.
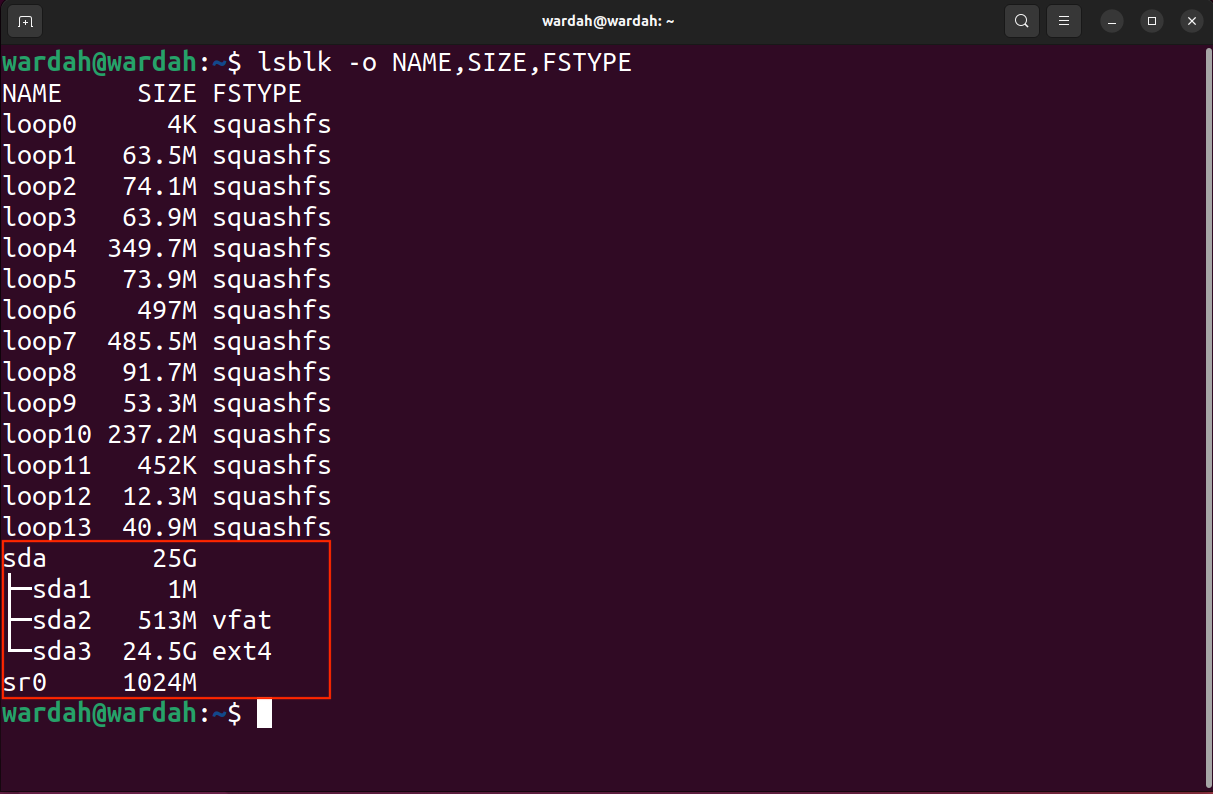
Now you can determine the target block, partition and location to save the rescued image file.
Another important thing to note is that on Linux, block names are dynamically assigned at boot time and after a reboot, the name of the block may change. So, be careful when writing down block names.
Now, use the syntax below to save the chunk as an image file and use the log file in the root directory.
sudo ddrescue—d—rX/dev/[block][path/name]. img [logfile_name]. log
Note: Replace [block], [path/name] and [logfile_name] of the image file with the preferred name accordingly.
In this example, I am recovering /dev/sda in the root directory using the image file name recovery.img. Log files (also called map files) are necessary if recovery is to be resumed at any time.
Sudo dd rescue-d-r2/dev/sda2 restore.img restore.log
Two important flags are used in the above command.
| D | -indirect | Used to tell the tool to access the disk directly and ignore the kernel cache |
| RX | -Retry-Pass | Used to tell the tool to retry bad sectors X times |
When executing the above command, you will notice that two files appear in the file browser, named recovery.img and recovery.log.
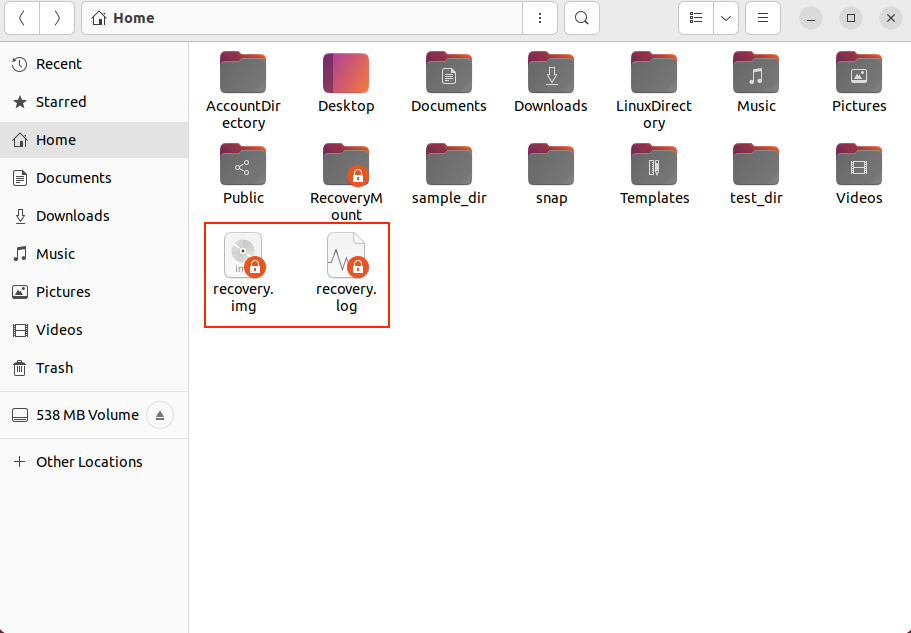
Recovery time depends on input block size and corruption. If you want to recover large data blocks, I recommend using log files, as the process can take hours or even days to complete.
The output of the above command is as follows:
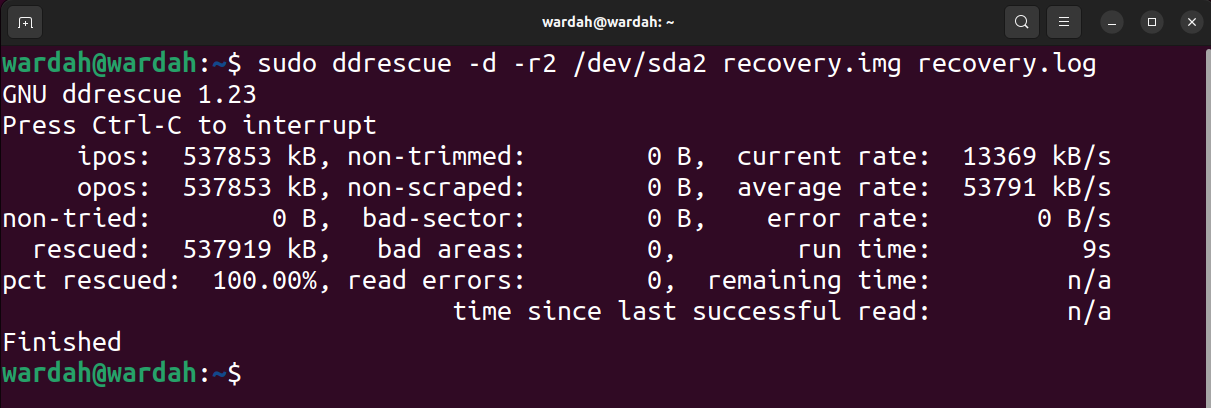
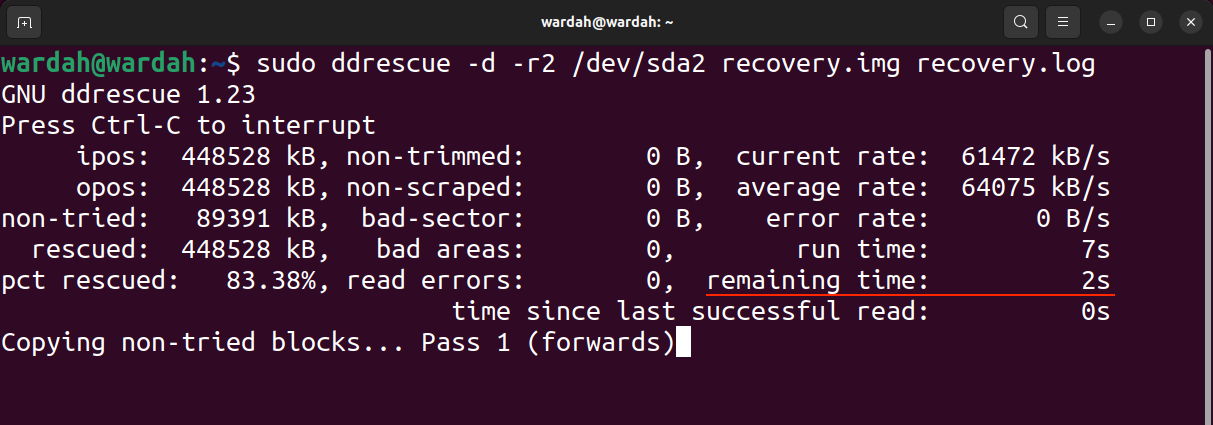
In the output image, ipos is the input location of the input file from which copying starts, and opos is the output location of the data written on the output file.
Non-try is the size of the block without waiting for a try. Rescued represents the size of successfully recovered blocks. Rescued pct indicates the percentage of data successfully recovered. The terms, non-pruned, non-scrap, bad sectors and bad areas are self-explanatory. However, read error terms represent failed read attempts numerically.
The running time shows the time it took the tool to complete the process, while the remaining time is the time remaining to complete the recovery process. The above output shows that the remaining time is 0 because the process has completed, please read the output below in the image of the unfinished process.
Let's see what we get in the log file; to open the generated log file, use the vim recovery.log command.
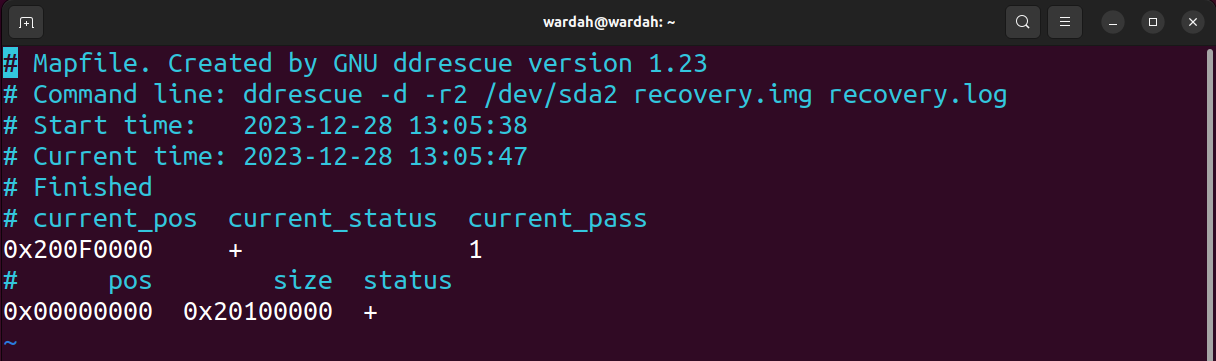
current_status is , indicating the end of the process, and current_pos is the position on the block.
The current status list is shown in the table below:
| ? | copy |
| * | prune |
| / | scrapped |
| – | Retry |
| F | Fill the specified block |
| G | Generate log file |
| The process is completed |
Below this, the log file shows the status of previously rescued chunks in the characters listed below:
| ? | Block Not Tried |
| * | Unpruned faulty block |
| / | Unretired invalid blocks |
| – | Bad sector failed data block |
| Complete Block |
Restore image file to new blocks
Once you have completed the recovery process and have the image file. You may now want to move it from the damaged drive to the new drive. To move an image file to a new block, first, connect the block to the system and then use the lsblk command to identify the block name.
Assuming it is /dev/sdb, use the following command to copy the image to a new block.
sudo ddrescue—f recovery. img/dev/sdb logfile.log
If there is any data, use the -f flag to overwrite the new block. Remember that the log file must have a different name to keep it separate from previously stored log files.
The above operation can also be done using dd, which is another powerful command for copying files.
sudo dd if = recovery. img of =/dev/sdb
Before proceeding with the restore, please remember that the new block must be large enough to preserve the entire recovered block; for example, if the recovery block is 5GB, the new block should be larger than 5GB.
If the recovered image file presents a lot of errors, then they can be repaired to an extent using the fsck command on Linux. On Windows you can use the CHKDSK or SFC command to do this. However, recovery depends on the number of errors generated by the corrupted file.
Now, the recovery process and repair work is complete. Another important thing to note is that instead of creating an image file and then copying it to the new block, you can recover the corrupted block directly on another block. Okay, in the next section I'll go into detail about this process.
Restore data block to another data block
To restore a block directly to a new block, first connect the block to the system and then use the lsblk command again to identify the block name. Wrong block names can disrupt the entire process and you may lose data.
After the source and destination blocks are identified, restore the block using the following command:
sudo ddrescue—d—f—r2/dev/[source]/dev/[destination] backup.log
Assuming /dev/sdb is the target block, so to copy the /dev/sda directory to the new block, use use:
Sudo ddue-d-f-r2/dev/sda/dev/sdb backup.log
Before attempting this procedure, please see the key considerations mentioned in the previous sections.
Recover specific data from saved image files
In many cases, the purpose of data recovery is to find specific files from a damaged drive. To access specific files, you need to mount the image file. On Linux, the recovered image file can be explored using the mount command.
Before mounting the image file, create a folder or directory where the contents of the image file will be extracted.
mkdir Recovery Mount
Next, use the following command to mount the image file:
sudo mount—o loop recovery. img~/Recovery Mount
The—o flag indicates options, and the loop option is used to treat the image file as a block device.
You can now access the contents of the image file, as shown in the screenshot below.
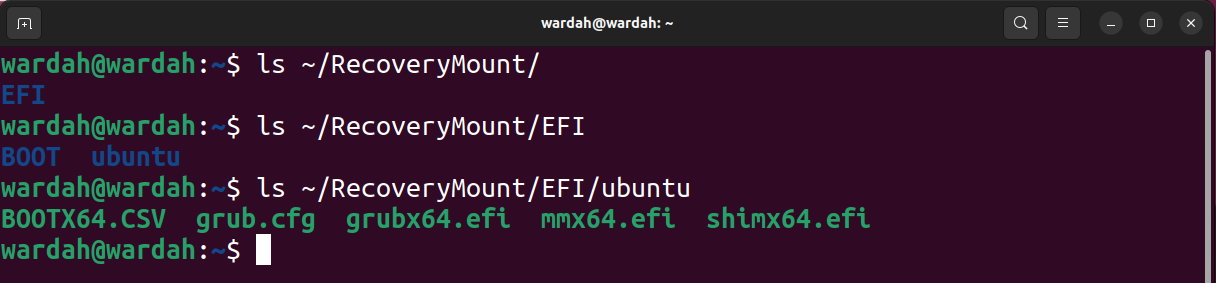
To unmount a block, use the umount command.
SUDO uninstall~/restore load
Advanced Features
To resume from a specific point, use the -i flag or -input-position. It should be in bytes and defaults to 0 bytes. It is important to resume replication from a specific point. For example, if you want to start the copy process from the 10 GB point, use the following command.
sudo ddrescue—i10GiB/dev/sda imagefile. img logfile.log
To define the maximum size of the input device, the -s flag will be used. -s indicates size, which can also be used as -size, in bytes. If the tool does not recognize the size of the input file, use this option to specify it.
Sudo ddreasure-s10GiB/dev/sda Imagefile.imglog file.log
—The ask option is very convenient as it prompts for confirmation of input and output blocks before starting the copy process. As mentioned before, the system dynamically assigns names to blocks and changes the names on reboot. In this case, this option may be useful.
sudo ddrescue——ask/dev/sda imagefile. img logfile.log
Additionally, some other alternatives are listed below:
| —R | —Reverse | Reverse the direction of copy |
| —q | -quite | Cancel all output messages |
| —V | -lengthy | In more detail, all output messages |
| —p | -Preallocation | Pre-allocate storage space for output files |
| —P | -Data preview | The display lines of the latest read data default to 3 lines |
How ddrescue works
DDREASE uses a powerful recovery algorithm, which is divided into four stages:
1.Copy
2.Pruning
3.Scrape
4.Retry
The execution of the ddrescue algorithm is shown in the figure below.

in conclusion
ddrescue is a powerful recovery tool for recovering data from a damaged or faulty drive by copying it to another drive. It can be installed effortlessly on any Linux distribution with the help of the default package manager. Please note important considerations before using this tool mentioned in this guide. The process of copying data is simple, unmount the drive and use ddrescue command with source drive name and destination drive name. Don't forget to use the log file as it becomes very useful during the recovery process.
The above is the detailed content of Use ddrescue to recover data on Linux. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
Solve database connection problem: a practical case of using minii/db library
Apr 18, 2025 am 07:09 AM
I encountered a tricky problem when developing a small application: the need to quickly integrate a lightweight database operation library. After trying multiple libraries, I found that they either have too much functionality or are not very compatible. Eventually, I found minii/db, a simplified version based on Yii2 that solved my problem perfectly.
 How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
How to solve the complexity of WordPress installation and update using Composer
Apr 17, 2025 pm 10:54 PM
When managing WordPress websites, you often encounter complex operations such as installation, update, and multi-site conversion. These operations are not only time-consuming, but also prone to errors, causing the website to be paralyzed. Combining the WP-CLI core command with Composer can greatly simplify these tasks, improve efficiency and reliability. This article will introduce how to use Composer to solve these problems and improve the convenience of WordPress management.
 How to optimize website performance: Experiences and lessons learned from using the Minify library
Apr 17, 2025 pm 11:18 PM
How to optimize website performance: Experiences and lessons learned from using the Minify library
Apr 17, 2025 pm 11:18 PM
In the process of developing a website, improving page loading has always been one of my top priorities. Once, I tried using the Miniify library to compress and merge CSS and JavaScript files in order to improve the performance of the website. However, I encountered many problems and challenges during use, which eventually made me realize that Miniify may no longer be the best choice. Below I will share my experience and how to install and use Minify through Composer.
 Solve the PHP timeout problem: application of phpunit/php-invoker library
Apr 17, 2025 pm 11:45 PM
Solve the PHP timeout problem: application of phpunit/php-invoker library
Apr 17, 2025 pm 11:45 PM
When developing PHP projects, you often encounter the problem that some functions or methods have been executed for too long, causing program timeout. I've tried multiple solutions, but the results are not satisfactory until I discovered the phpunit/php-invoker library. This library completely solved my problem by setting the timeout time to call the executable function.
 How to solve TYPO3CMS installation and configuration problems? It can be done easily with Composer!
Apr 17, 2025 pm 10:51 PM
How to solve TYPO3CMS installation and configuration problems? It can be done easily with Composer!
Apr 17, 2025 pm 10:51 PM
When using TYPO3CMS for website development, you often encounter problems with installation and configuration extensions. Especially for beginners, how to properly install and configure TYPO3 and its extensions can be a headache. I had similar difficulties in my actual project and ended up solving these problems by using Composer and TYPO3CMSComposerInstallers.
 Accelerate PHP code inspection: Experience and practice using overtrue/phplint library
Apr 17, 2025 pm 11:06 PM
Accelerate PHP code inspection: Experience and practice using overtrue/phplint library
Apr 17, 2025 pm 11:06 PM
During the development process, we often need to perform syntax checks on PHP code to ensure the correctness and maintainability of the code. However, when the project is large, the single-threaded syntax checking process can become very slow. Recently, I encountered this problem in my project. After trying multiple methods, I finally found the library overtrue/phplint, which greatly improves the speed of code inspection through parallel processing.
 Solve caching issues in Craft CMS: Using wiejeben/craft-laravel-mix plug-in
Apr 18, 2025 am 09:24 AM
Solve caching issues in Craft CMS: Using wiejeben/craft-laravel-mix plug-in
Apr 18, 2025 am 09:24 AM
When developing websites using CraftCMS, you often encounter resource file caching problems, especially when you frequently update CSS and JavaScript files, old versions of files may still be cached by the browser, causing users to not see the latest changes in time. This problem not only affects the user experience, but also increases the difficulty of development and debugging. Recently, I encountered similar troubles in my project, and after some exploration, I found the plugin wiejeben/craft-laravel-mix, which perfectly solved my caching problem.
 How to use Composer to manage PHP project version number
Apr 18, 2025 am 06:24 AM
How to use Composer to manage PHP project version number
Apr 18, 2025 am 06:24 AM
Version control is a key link when managing PHP projects. Recently I was working on a Git-based PHP project and I encountered a problem: how to automatically generate and manage version numbers during development. This problem seems simple, but manual maintenance of the version number is not only cumbersome, but also prone to errors. After some exploration, I found a very useful tool - the sebastian/version library, which was easily integrated into the project through Composer, completely solving my troubles.
