
 Technology peripherals
AI
Stability AI open source new release: 3D generation introduces video diffusion model, quality consistency up, 4090 playable
Technology peripherals
AI
Stability AI open source new release: 3D generation introduces video diffusion model, quality consistency up, 4090 playable
Stability AI open source new release: 3D generation introduces video diffusion model, quality consistency up, 4090 playable

Stability AI, the company behind Stable Diffusion, has launched something new.
What this time brings is new progress in Tusheng 3D:
Stable Video 3D (SV3D) based on Stable Video Diffusion can generate high-quality 3D networks with only one picture grid.

Stable Video Diffusion (SVD) is a model previously released by Stability AI for generating high-resolution videos. The advent of SV3D marks the first time that the video diffusion model has been successfully applied to the field of 3D generation.
Officially stated that based on this, SV3D has greatly improved the quality and view consistency of 3D generation.

The model weights are still open source, but they can only be used for non-commercial purposes. If you want to use them commercially, you have to buy a Stability AI membership~
Not much to say , let’s take a look at the details of the paper.
Using the video diffusion model for 3D generation
Introducing the latent video diffusion model, the core purpose of SV3D is to use the temporal consistency of the video model to improve the consistency of 3D generation.
And the video data itself is easier to obtain than 3D data.
Stability AI provides two versions of SV3D this time:
- SV3D_u: Generate orbit video based on a single image.
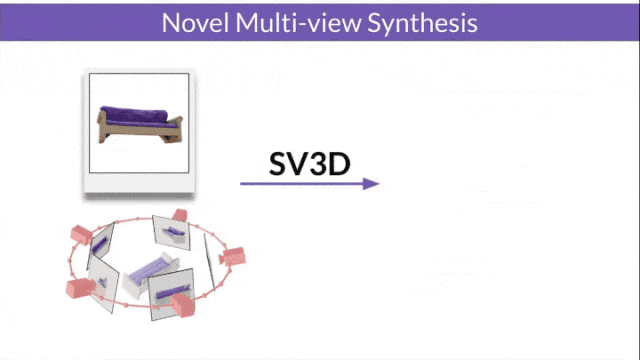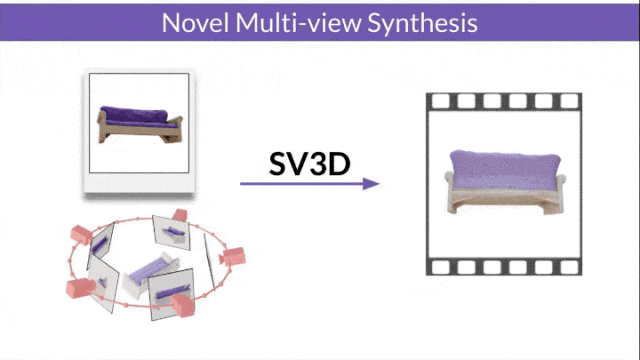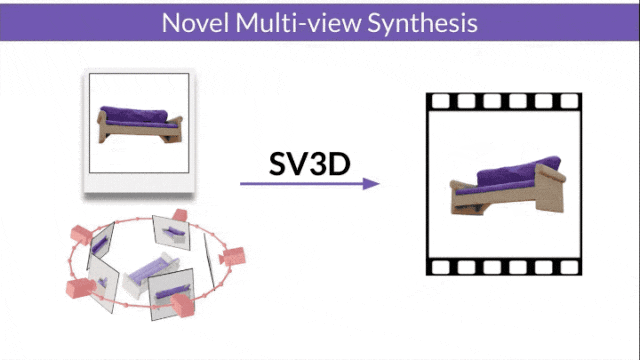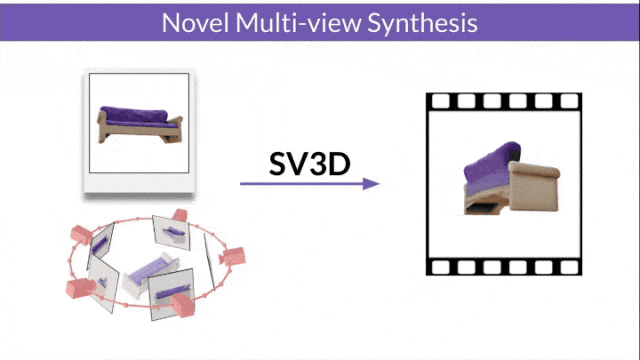
- SV3D_p: Extends the functionality of SV3D_u to create 3D model videos based on specified camera paths.
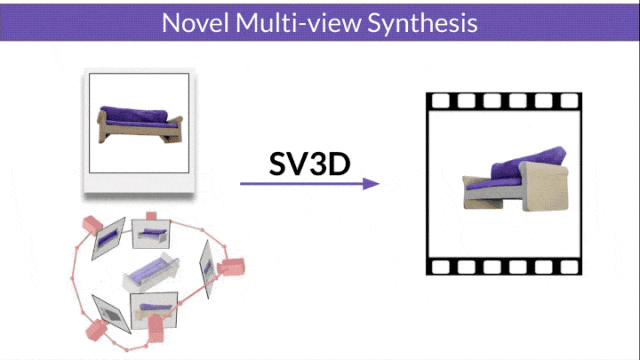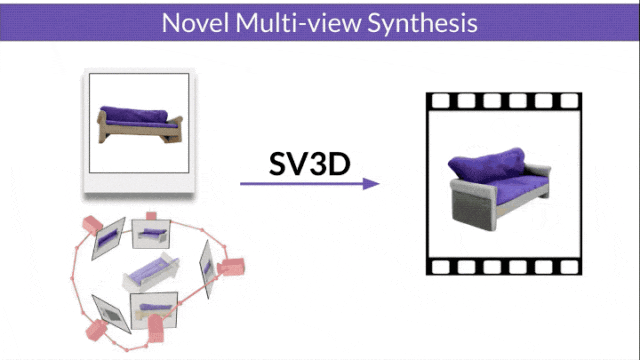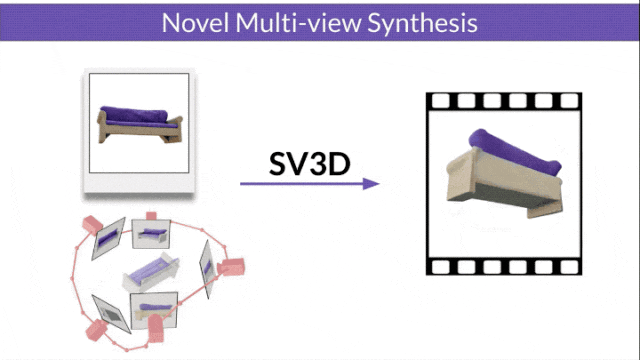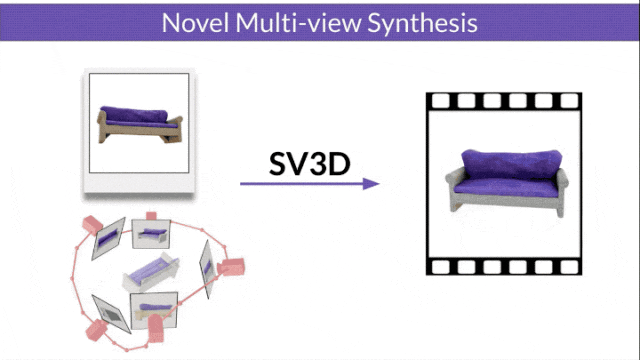
The researchers also improved the 3D optimization technology: using a coarse-to-fine training strategy to optimize NeRF and DMTet meshes to generate 3D objects.
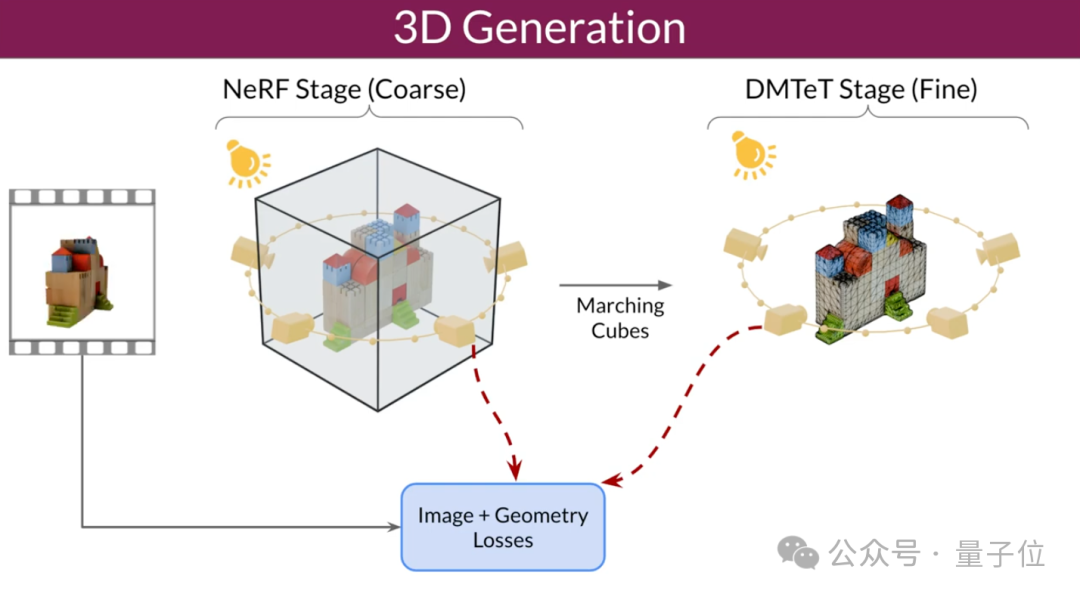
They also designed a special loss function called Masked Score Distillation Sampling (SDS) to improve performance by optimizing areas that are not directly visible in the training data. Quality and consistency of generated 3D models.
At the same time, SV3D introduces a lighting model based on spherical Gaussian to separate lighting effects and textures, effectively reducing built-in lighting problems while maintaining texture clarity.
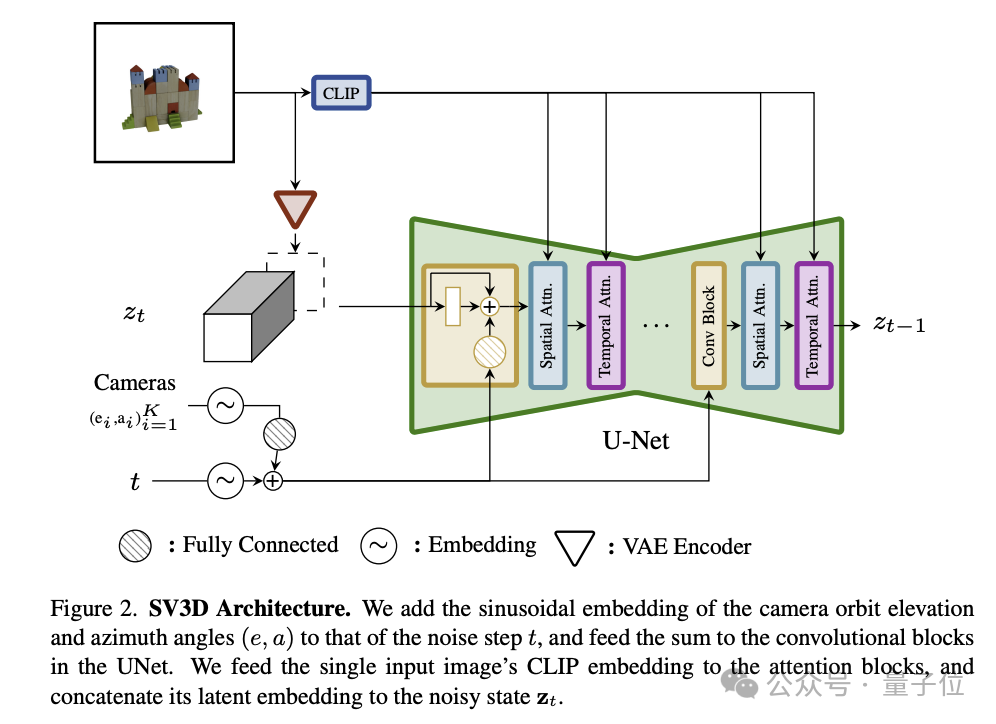
Specifically in terms of architecture, SV3D contains the following key components:
- UNet: SV3D is built on the basis of SVD and contains a multi-layer UNet, where each layer has a series of residual blocks (including 3D convolutional layers) and two to process spatial and temporal information respectively. Transformer module.
- Conditional input: The input image is embedded into the latent space through the VAE encoder, and will be merged with the noise potential state and input into UNet together; the CLIP embedding matrix of the input image is used as the cross attention of each Transformer module Key-value pairs for the force layer.
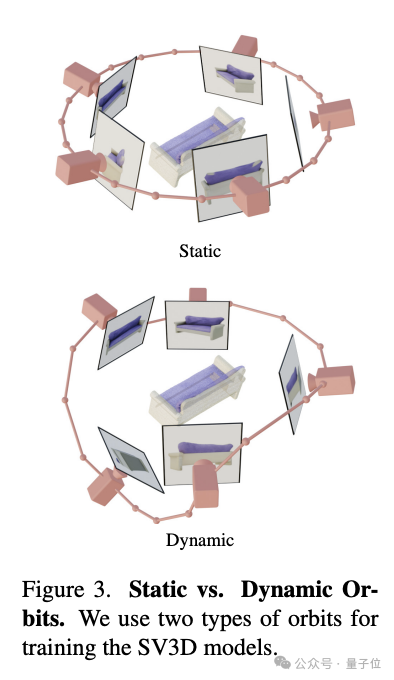
- Camera trajectory encoding: SV3D designs two types of trajectories, static and dynamic, to study the impact of camera attitude conditions. In a static orbit, the camera surrounds the object at regularly spaced azimuth angles; a dynamic orbit allows for irregularly spaced azimuth angles and different elevation angles.
The camera's motion trajectory information and the time information of the diffusion noise will be input into the residual module together and converted into sinusoidal position embeddings. Then these embedded information will be integrated and linearly transformed, and added to the noise The time step is embedded in.
This design aims to improve the model's ability to process images by finely controlling camera trajectories and noise input.
In addition, SV3D uses CFG (classifier-free guidance) during the generation process to control the sharpness of the generation, especially when generating the last few frames of the track, using triangles CFG scaling to avoid over-sharpening.
The researchers trained SV3D on the Objaverse dataset, with an image resolution of 575×576 and a field of view of 33.8 degrees. The paper reveals that all three models (SV3D_u, SV3D_c, SV3D_p) were trained on 4 nodes for about 6 days, each node equipped with 8 80GB A100 GPUs.
Experimental results
In terms of new perspective synthesis (NVS) and 3D reconstruction, SV3D surpasses other existing methods and reaches SOTA.
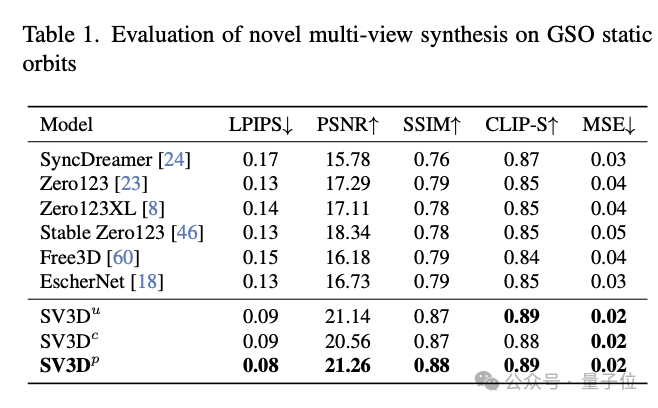
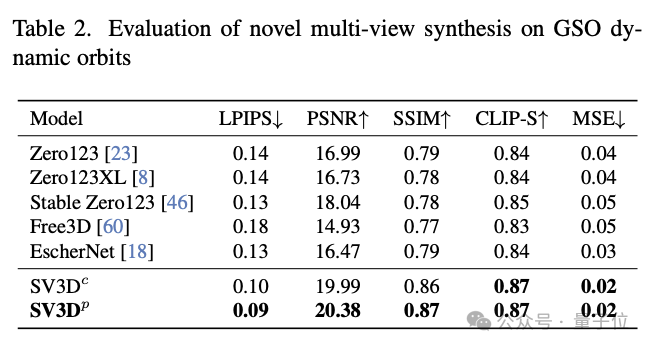
#From the results of qualitative comparison, the multi-view view generated by SV3D has richer details and is closer to the original input image. In other words, SV3D can more accurately capture details and maintain consistency when viewing angle changes in understanding and reconstructing the 3D structure of objects.

Such results have aroused the emotion of many netizens:
It is conceivable that in the next 6-12 months, 3D generation Technology will be used in gaming and video projects.

There are always some bold ideas in the comment area...
And the project is open source, the first wave of friends have already started playing it, and they can run it on 4090.

Reference link:
[1]https://twitter.com/StabilityAI/status/1769817136799855098.
[2]https://stability.ai/news/introducing-stable-video-3d.
[3]https://sv3d.github.io/index.html.
The above is the detailed content of Stability AI open source new release: 3D generation introduces video diffusion model, quality consistency up, 4090 playable. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 What is the method of converting Vue.js strings into objects?
Apr 07, 2025 pm 09:18 PM
What is the method of converting Vue.js strings into objects?
Apr 07, 2025 pm 09:18 PM
Using JSON.parse() string to object is the safest and most efficient: make sure that strings comply with JSON specifications and avoid common errors. Use try...catch to handle exceptions to improve code robustness. Avoid using the eval() method, which has security risks. For huge JSON strings, chunked parsing or asynchronous parsing can be considered for optimizing performance.
 The first fully automated scientific discovery AI system, Transformer author startup Sakana AI launches AI Scientist
Aug 13, 2024 pm 04:43 PM
The first fully automated scientific discovery AI system, Transformer author startup Sakana AI launches AI Scientist
Aug 13, 2024 pm 04:43 PM
Editor | ScienceAI A year ago, Llion Jones, the last author of Google's Transformer paper, left to start a business and co-founded the artificial intelligence company SakanaAI with former Google researcher David Ha. SakanaAI claims to create a new basic model based on nature-inspired intelligence! Now, SakanaAI has handed in its answer sheet. SakanaAI announces the launch of AIScientist, the world’s first AI system for automated scientific research and open discovery! From conceiving, writing code, running experiments and summarizing results, to writing entire papers and conducting peer reviews, AIScientist unlocks AI-driven scientific research and acceleration
 HyperOS 2.0 debuts with Xiaomi 15, AI is the focus
Sep 01, 2024 pm 03:39 PM
HyperOS 2.0 debuts with Xiaomi 15, AI is the focus
Sep 01, 2024 pm 03:39 PM
Recently, news broke that Xiaomi will launch the highly anticipated HyperOS 2.0 version in October. 1.HyperOS2.0 is expected to be released simultaneously with the Xiaomi 15 smartphone. HyperOS 2.0 will significantly enhance AI capabilities, especially in photo and video editing. HyperOS2.0 will bring a more modern and refined user interface (UI), providing smoother, clearer and more beautiful visual effects. The HyperOS 2.0 update also includes a number of user interface improvements, such as enhanced multitasking capabilities, improved notification management, and more home screen customization options. The release of HyperOS 2.0 is not only a demonstration of Xiaomi's technical strength, but also its vision for the future of smartphone operating systems.
 Former Google CEO Schmidt made a surprising statement: AI entrepreneurship can be 'stealed' first and 'processed' later
Aug 15, 2024 am 11:53 AM
Former Google CEO Schmidt made a surprising statement: AI entrepreneurship can be 'stealed' first and 'processed' later
Aug 15, 2024 am 11:53 AM
According to news from this website on August 15, a speech given by former Google CEO and Chairman Eric Schmidt at Stanford University yesterday caused huge controversy. In addition to causing controversy by saying that Google employees believe that "working from home is more important than winning," when talking about the future development of artificial intelligence, he openly stated that AI startups can first steal intellectual property (IP) through AI tools and then hire Lawyers handle legal disputes. Schmidt talks about the impact of the TikTok ban. Schmidt takes the short video platform TikTok as an example, claiming that if TikTok is banned, anyone can use AI to generate a similar application and directly steal all users, all music and other content (MakemeacopyofTikTok,stealalltheuse
 C language data structure: the key role of data structures in artificial intelligence
Apr 04, 2025 am 10:45 AM
C language data structure: the key role of data structures in artificial intelligence
Apr 04, 2025 am 10:45 AM
C Language Data Structure: Overview of the Key Role of Data Structure in Artificial Intelligence In the field of artificial intelligence, data structures are crucial to processing large amounts of data. Data structures provide an effective way to organize and manage data, optimize algorithms and improve program efficiency. Common data structures Commonly used data structures in C language include: arrays: a set of consecutively stored data items with the same type. Structure: A data type that organizes different types of data together and gives them a name. Linked List: A linear data structure in which data items are connected together by pointers. Stack: Data structure that follows the last-in first-out (LIFO) principle. Queue: Data structure that follows the first-in first-out (FIFO) principle. Practical case: Adjacent table in graph theory is artificial intelligence
 What are the best practices for converting XML into images?
Apr 02, 2025 pm 08:09 PM
What are the best practices for converting XML into images?
Apr 02, 2025 pm 08:09 PM
Converting XML into images can be achieved through the following steps: parse XML data and extract visual element information. Select the appropriate graphics library (such as Pillow in Python, JFreeChart in Java) to render the picture. Understand the XML structure and determine how the data is processed. Choose the right tools and methods based on the XML structure and image complexity. Consider using multithreaded or asynchronous programming to optimize performance while maintaining code readability and maintainability.
 What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
When converting strings to objects in Vue.js, JSON.parse() is preferred for standard JSON strings. For non-standard JSON strings, the string can be processed by using regular expressions and reduce methods according to the format or decoded URL-encoded. Select the appropriate method according to the string format and pay attention to security and encoding issues to avoid bugs.
 How to distinguish between closing a browser tab and closing the entire browser using JavaScript?
Apr 04, 2025 pm 10:21 PM
How to distinguish between closing a browser tab and closing the entire browser using JavaScript?
Apr 04, 2025 pm 10:21 PM
How to distinguish between closing tabs and closing entire browser using JavaScript on your browser? During the daily use of the browser, users may...
