
 Technology peripherals
AI
Google releases 'Vlogger” model: a single picture generates a 10-second video
Technology peripherals
AI
Google releases 'Vlogger” model: a single picture generates a 10-second video
Google releases 'Vlogger” model: a single picture generates a 10-second video

Google has released a new video framework:
You only needa picture of you and a recording of your speech, and you can getA lifelike video of my speech.
The video duration is variable, and the current example seen is up to 10s.
You can see that whether it is mouth shape or facial expression, it is very natural.
If the input image covers the entire upper body, it can also be matched with rich gestures:

Netizens see After finishing it, he said:
With it, we no longer need to fix our hair or put on clothes for online video conferences in the future.
Well, just take a portrait and record the speech audio (manual dog head)
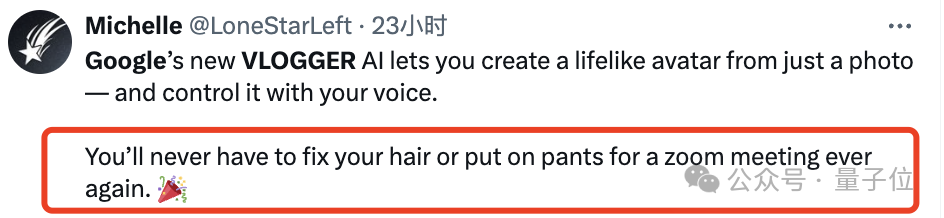
Use voice control Portrait Generation Video
This framework is calledVLOGGER.
It is mainly based on the diffusion model and contains two parts:
One is the random human-to-3D-motion (human-to-3d-motion) Diffusion model.
The other is a new diffusion architecture for enhancing text-to-image models.
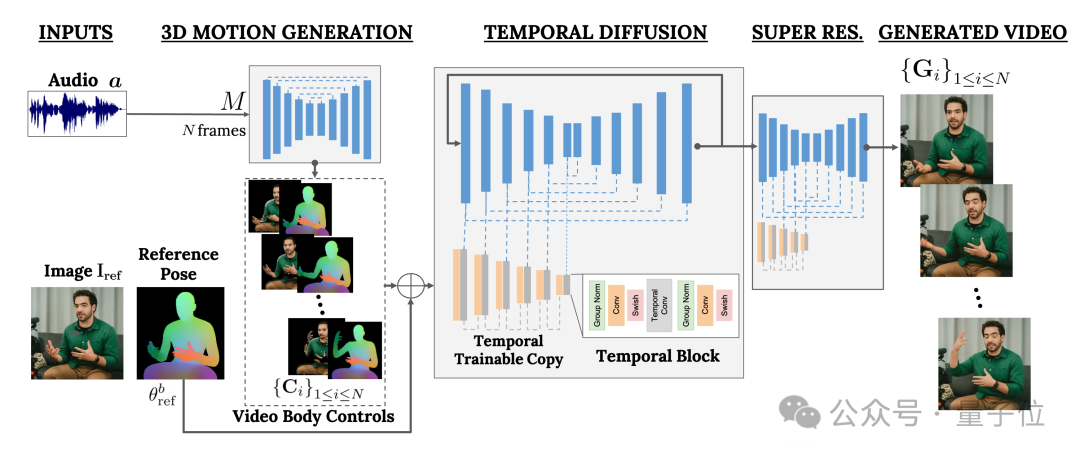
Among them, the former is responsible for using the audio waveform as input to generate the character's body control actions, including eyes, expressions and gestures, overall body posture, etc.
The latter is a temporal dimension image-to-image model that is used to extend the large-scale image diffusion model and use the just predicted actions to generate corresponding frames.
In order to make the results conform to a specific character image, VLOGGER also takes the pose diagram of the parameter image as input.
The training of VLOGGER is completed on a very large data set (named MENTOR) .
How big is it? It has a total length of 2,200 hours and contains a total of 800,000 character videos.
Among them, the video duration of the test set is also 120 hours long, with a total of 4,000 characters.
According to Google, the most outstanding performance of VLOGGER is its diversity:
As shown in the figure below, the darker the color of the final pixel image (red) represents The richer the action.

Compared with previous similar methods in the industry, the biggest advantage of VLOGGER is that it does not require training for each person, does not rely on face detection and cropping, and The generated video is very complete (including both face and lips, as well as body movements) and so on.

Specifically, as shown in the following table:
The Face Reenactment method cannot use audio and text to control such video generation.
Audio-to-motion can generate audio by encoding audio into 3D facial movements, but the effect it generates is not realistic enough.
Lip sync can handle videos of different themes, but it can only simulate mouth movements.
In comparison, the latter two methods SadTaker and Styletalk perform closest to Google VLOGGER, but they are also defeated by the inability to control the body and further edit the video.

Speaking of video editing, as shown in the figure below, one of the applications of the VLOGGER model is this. It can make the character shut up, close eyes, and only close the left eye with one click. Or keep your eyes open the whole time:

#Another application is video translation:
For example, change the English speech in the original video into Spanish with the same mouth shape.
Netizens complained
Finally, according to the "old rule", Google did not release the model. Now all we can see are more effects and papers.
Well, there are a lot of complaints:
The image quality of the model, the mouth shape is not right, it still looks very robotic, etc.
Therefore, some people do not hesitate to leave negative reviews:
Is this the level of Google?

I’m a bit sorry for the name “VLOGGER”.

#——Compared with OpenAI’s Sora, the netizen’s statement is indeed not unreasonable. .
What do you think?
More effects:https://enriccorona.github.io/vlogger/
Full paper:https://enriccorona.github.io/vlogger/paper.pdf
The above is the detailed content of Google releases 'Vlogger” model: a single picture generates a 10-second video. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 How to record screen video with OPPO phone (simple operation)
May 07, 2024 pm 06:22 PM
How to record screen video with OPPO phone (simple operation)
May 07, 2024 pm 06:22 PM
Game skills or teaching demonstrations, in daily life, we often need to use mobile phones to record screen videos to show some operating steps. Its function of recording screen video is also very good, and OPPO mobile phone is a powerful smartphone. Allowing you to complete the recording task easily and quickly, this article will introduce in detail how to use OPPO mobile phones to record screen videos. Preparation - Determine recording goals You need to clarify your recording goals before you start. Do you want to record a step-by-step demonstration video? Or want to record a wonderful moment of a game? Or want to record a teaching video? Only by better arranging the recording process and clear goals. Open the screen recording function of OPPO mobile phone and find it in the shortcut panel. The screen recording function is located in the shortcut panel.
 How to switch language in Adobe After Effects cs6 (Ae cs6) Detailed steps for switching between Chinese and English in Ae cs6 - ZOL download
May 09, 2024 pm 02:00 PM
How to switch language in Adobe After Effects cs6 (Ae cs6) Detailed steps for switching between Chinese and English in Ae cs6 - ZOL download
May 09, 2024 pm 02:00 PM
1. First find the AMTLanguages folder. We found some documentation in the AMTLanguages folder. If you install Simplified Chinese, there will be a zh_CN.txt text document (the text content is: zh_CN). If you installed it in English, there will be a text document en_US.txt (the text content is: en_US). 3. Therefore, if we want to switch to Chinese, we need to create a new text document of zh_CN.txt (the text content is: zh_CN) under the AdobeAfterEffectsCCSupportFilesAMTLanguages path. 4. On the contrary, if we want to switch to English,
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 How to shoot videos on Douyin? How to turn on the microphone for video shooting?
May 09, 2024 pm 02:40 PM
How to shoot videos on Douyin? How to turn on the microphone for video shooting?
May 09, 2024 pm 02:40 PM
As one of the most popular short video platforms today, the quality and effect of Douyin’s videos directly affect the user’s viewing experience. So, how to shoot high-quality videos on Douyin? 1. How to shoot videos on Douyin? 1. Open the Douyin APP and click the "+" button in the middle at the bottom to enter the video shooting page. 2. Douyin provides a variety of shooting modes, including normal shooting, slow motion, short video, etc. Choose the appropriate shooting mode according to your needs. 3. On the shooting page, click the "Filter" button at the bottom of the screen to choose different filter effects to make the video more personalized. 4. If you need to adjust parameters such as exposure and contrast, you can click the "Parameters" button in the lower left corner of the screen to set it. 5. During shooting, you can click on the left side of the screen
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
