
 Technology peripherals
AI
Stable Video 3D makes a shocking debut: a single image generates 3D video without blind spots, and model weights are opened
Technology peripherals
AI
Stable Video 3D makes a shocking debut: a single image generates 3D video without blind spots, and model weights are opened
Stable Video 3D makes a shocking debut: a single image generates 3D video without blind spots, and model weights are opened

Stability AI has a new member in its great model family.
Yesterday, after launching Stable Diffusion and Stable Video Diffusion, Stability AI brought a large 3D video generation model "Stable Video 3D" (SV3D) to the community. .
The model is built based on Stable Video Diffusion, its main advantage is that it significantly improves the quality of 3D generation and multi-view consistency. Compared with the previous Stable Zero123 launched by Stability AI and the joint open source Zero123-XL, the effect of this model is even better.
Currently, Stable Video 3D supports both commercial use, which requires joining Stability AI membership (Membership); and non-commercial use, where users can download the model weights on Hugging Face.

Stability AI provides two model variants, SV3D_u and SV3D_p. SV3D_u generates orbital video based on a single image input without the need for camera adjustments, while SV3D_p further extends the generation capabilities by adapting a single image and orbital perspective, allowing users to create 3D videos along a specified camera path.
Currently, the research paper on Stable Video 3D has been released, with three core authors.

- Paper address: https://stability.ai/s/SV3D_report.pdf
- Blog address: https://stability.ai/news/introducing-stable-video-3d
- Huggingface address: https:// huggingface.co/stabilityai/sv3d
Technology Overview
Stable Video 3D delivers significant advancements in 3D generation, especially in Novel view synthesis (NVS).
Previous approaches often tend to solve the problem of limited viewing angles and inconsistent inputs, while Stable Video 3D is able to provide a coherent view from any given angle and generalize well. As a result, the model not only increases pose controllability but also ensures consistent object appearance across multiple views, further improving key issues affecting realistic and accurate 3D generation.
As shown in the figure below, compared with Stable Zero123 and Zero-XL, Stable Video 3D can generate novel multi-views with stronger details, more faithfulness to the input image, and more consistent multi-viewpoints .

In addition, Stable Video 3D leverages its multi-view consistency to optimize 3D Neural Radiance Fields (NeRF) to improve direct resynchronization. The quality of the 3D mesh generated by the view.
To this end, Stability AI designed a masked fractional distillation sampling loss that further enhances the 3D quality of unseen regions in the predicted view. Also to alleviate baked lighting issues, Stable Video 3D uses a decoupled lighting model that is optimized with 3D shapes and textures.
The image below shows an example of improved 3D mesh generation through 3D optimization when using the Stable Video 3D model and its output.

The following figure shows the comparison of the 3D mesh results generated using Stable Video 3D with those generated by EscherNet and Stable Zero123.

Architecture details
The architecture of the Stable Video 3D model is as shown in Figure 2 As shown, it is built based on the Stable Video Diffusion architecture and contains a UNet with multiple layers, each of which contains a residual block sequence with a Conv3D layer, and two with attention layers (spatial and time) transformer block.
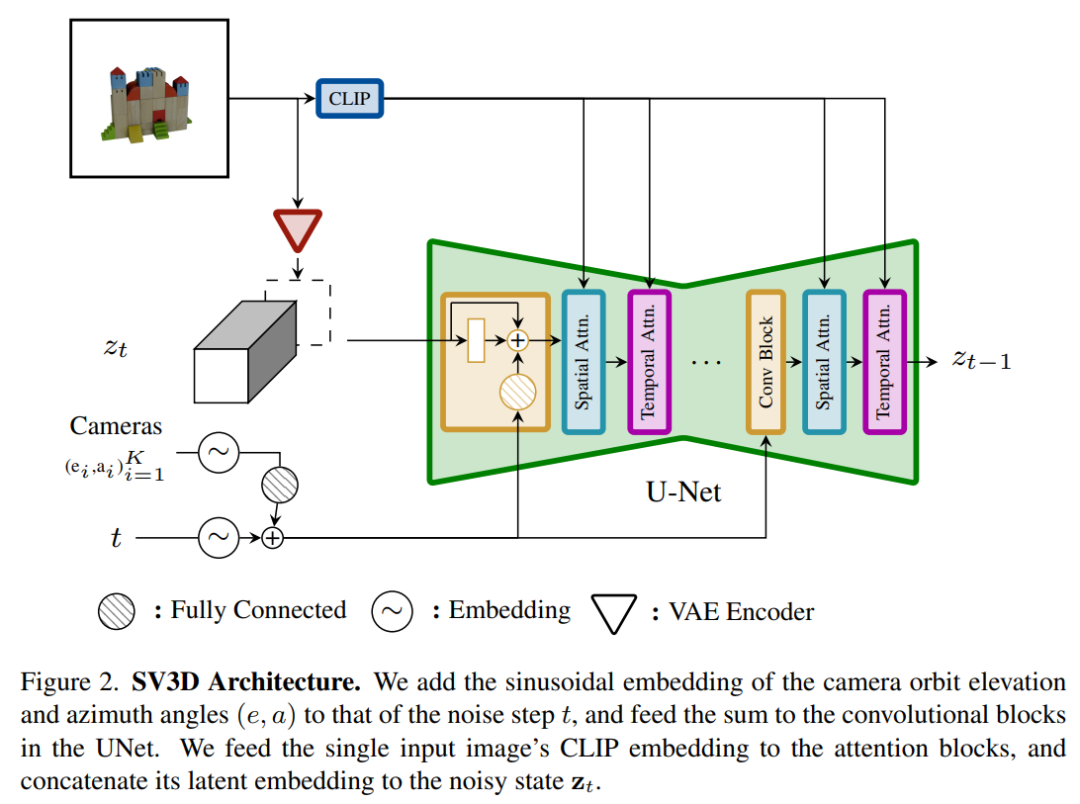
The specific process is as follows:
(i) Delete "fps id" and "motion bucket id", because they have nothing to do with Stable Video 3D;
(ii) The conditional image is embedded into the latent space through the VAE encoder of Stable Video Diffusion, and then passed to The noise latent state input zt of UNet at time step t is connected to the noise latent state input zt;
#(iii) The CLIPembedding matrix of the conditional image is provided to the cross-attention layer of each transformer block to act as a key and values, and the query becomes the feature of the corresponding layer;
(iv) The camera trajectory is fed into the residual block along the diffusion noise time step. The camera pose angles ei and ai and the noise time step t are first embedded into the sinusoidal position embedding, then the camera pose embeddings are concatenated together for linear transformation and added to the noise time step embedding, and finally fed into each residual block and is added to the input features of the block.
In addition, Stability AI designed static orbits and dynamic orbits to study the impact of camera pose adjustments, as shown in Figure 3 below.
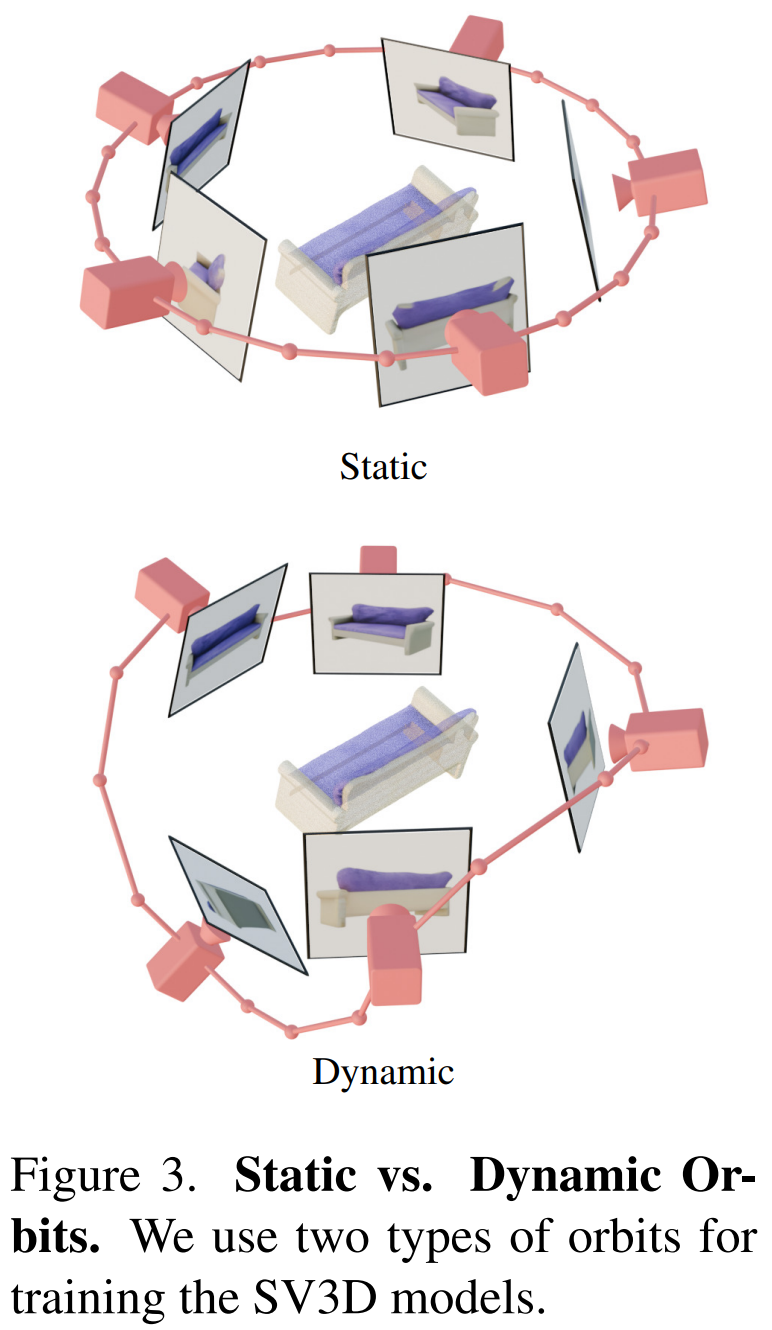
#On a static orbit, the camera rotates around the object in equidistant azimuth using the same elevation angle as the condition image. The disadvantage of this is that based on the adjusted elevation angle, you may not get any information about the top or bottom of the object. In a dynamic orbit, the azimuth angles can be unequal, and the elevation angles of each view can also be different.
To build dynamic orbits, Stability AI samples a static orbit, adding small random noise to its azimuth and a randomly weighted combination of sinusoids of different frequencies to its elevation. Doing so provides temporal smoothness and ensures that the camera trajectory ends along the same azimuth and elevation loop as the condition image.
Experimental Results
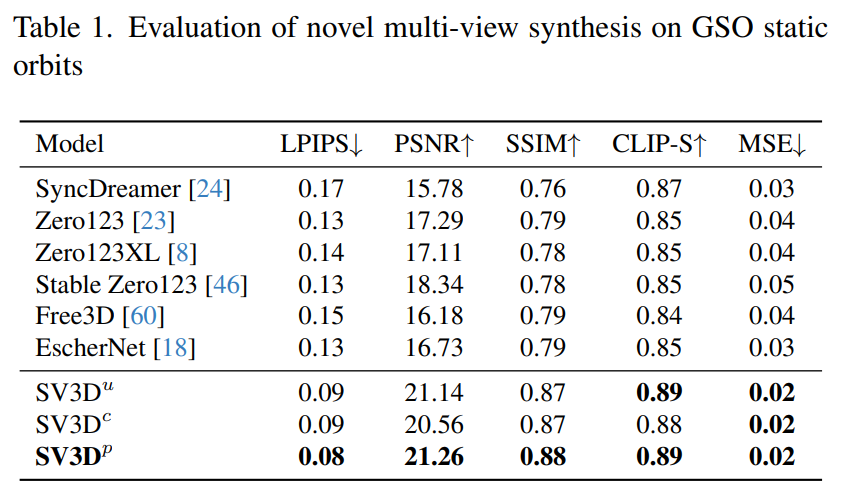
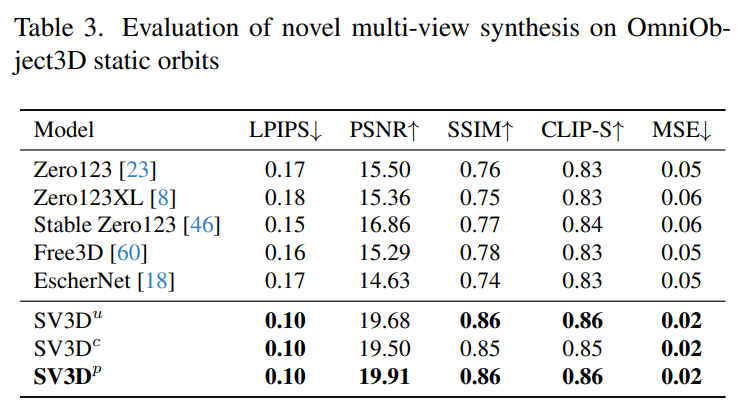
Stability AI evaluated Stable Video on static and dynamic orbits on unseen GSO and OmniObject3D datasets 3D composite multi-view effect. The results, shown in Tables 1 through 4 below, show that Stable Video 3D achieves state-of-the-art performance in novel multi-view synthesis.
Tables 1 and 3 show the results of Stable Video 3D and other models on static orbits, showing that even the model SV3D_u without pose adjustment performs better than all previous methods. better.
Ablation analysis results show that SV3D_c and SV3D_p outperform SV3D_u in the generation of static trajectories, although the latter is trained exclusively on static trajectories.
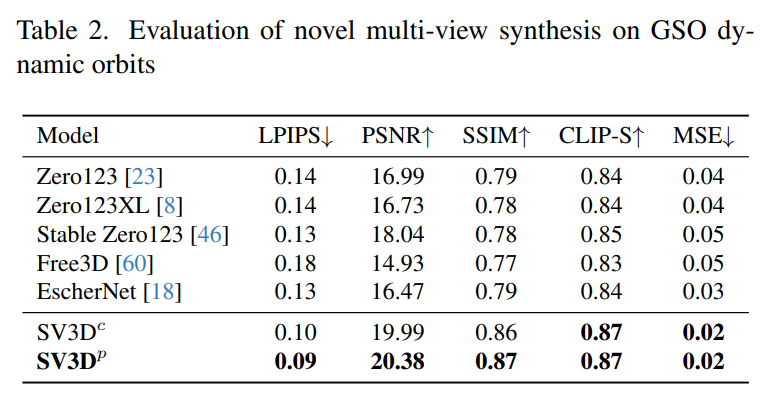
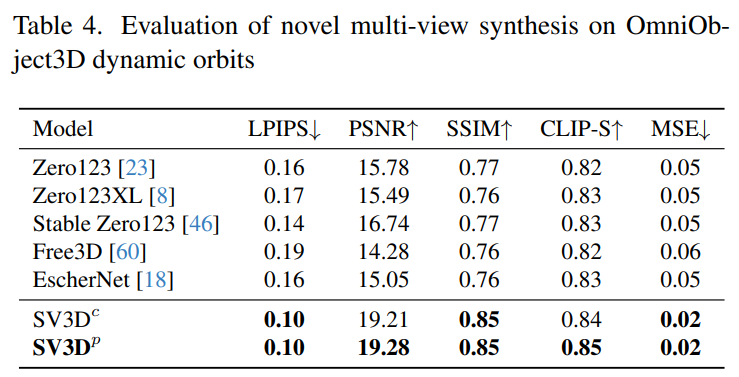
##Table 2 and Table 4 below show the generation results of dynamic orbits, including pose adjustment models SV3D_c and SV3D_p, which achieves SOTA on all metrics.
The visual comparison results in Figure 6 below further demonstrate that Stable Video 3D The resulting images are more detailed, more faithful to the conditional image, and more consistent across multiple viewing angles.

#Please refer to the original paper for more technical details and experimental results.
The above is the detailed content of Stable Video 3D makes a shocking debut: a single image generates 3D video without blind spots, and model weights are opened. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
 Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
The platforms that have outstanding performance in leveraged trading, security and user experience in 2025 are: 1. OKX, suitable for high-frequency traders, providing up to 100 times leverage; 2. Binance, suitable for multi-currency traders around the world, providing 125 times high leverage; 3. Gate.io, suitable for professional derivatives players, providing 100 times leverage; 4. Bitget, suitable for novices and social traders, providing up to 100 times leverage; 5. Kraken, suitable for steady investors, providing 5 times leverage; 6. Bybit, suitable for altcoin explorers, providing 20 times leverage; 7. KuCoin, suitable for low-cost traders, providing 10 times leverage; 8. Bitfinex, suitable for senior play
