
 Hardware Tutorial
Hardware Review
Google releases 'Vlogger” model: a single picture generates a 10-second video
Hardware Tutorial
Hardware Review
Google releases 'Vlogger” model: a single picture generates a 10-second video
Google releases 'Vlogger” model: a single picture generates a 10-second video

Google has released a new video framework:
You only need a picture of your face and a recording of your speech to get a lifelike video of your speech.
The video duration is variable, and the current example seen is up to 10s.
You can see that whether it is mouth shape or facial expression, it is very natural.
If the input image covers the entire upper body, it can also be matched with rich gestures:

After reading it, netizens said:
Yes With it, we no longer need to fix our hair and get dressed for online video conferences in the future.
Well, just take a portrait and record the speech audio (manual dog head)
Use your voice to control the portrait to generate a video
This framework is called VLOGGER.
It is mainly based on the diffusion model and contains two parts:
One is a random human-to-3d-motion diffusion model.
The other is a new diffusion architecture for enhancing text-to-image models.
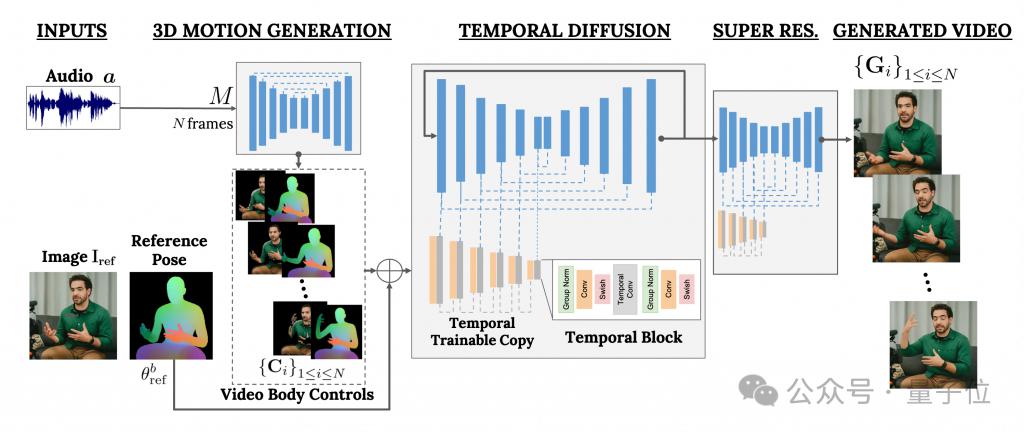
Among them, the former is responsible for using the audio waveform as input to generate the character's body control actions, including eyes, expressions and gestures, overall body posture, etc.
The latter is a temporal dimension image-to-image model that is used to extend the large-scale image diffusion model and use the just predicted actions to generate corresponding frames.
In order to make the results conform to a specific character image, VLOGGER also takes the pose map of the parameter image as input.
The training of VLOGGER is completed on a very large data set (named MENTOR).
How big is it? It is 2,200 hours long and contains a total of 800,000 character videos.
Among them, the video duration of the test set is also 120 hours long, with a total of 4,000 characters.
According to Google, the most outstanding performance of VLOGGER is its diversity:
As shown in the figure below, the darker (red) the color of the final pixel image, the richer the actions.

Compared with previous similar methods in the industry, the biggest advantage of VLOGGER is that it does not need to train everyone, does not rely on face detection and cropping, and The generated video is complete (including both face and lips, body movements) and more.

Specifically, as shown in the following table:
The Face Reenactment method cannot use audio and text to control such video generation.
Audio-to-motion can generate audio by encoding audio into 3D facial movements, but the effect it generates is not realistic enough.
Lip sync can handle videos of different themes, but it can only simulate mouth movements.
In comparison, the latter two methods, SadTaker and Styletalk, perform closest to Google VLOGGER, but they are also defeated by the inability to control the body and further edit the video.

Speaking of video editing, as shown in the figure below, one of the applications of the VLOGGER model is this. It can make the character shut up, close eyes, only close the left eye, or open the whole eye with one click:

Another application is video translation:
For example, change the English speech of the original video into Spanish with the same mouth shape.
Netizens complained
Finally, according to the "old rule", Google did not release the model, and all that can be seen now are more effects and papers.
Well, there are a lot of complaints:
The image quality of the model, the mouth shape is not right, it still looks very robotic, etc.
Therefore, some people do not hesitate to leave negative reviews:
Is this the level of Google?

I'm a bit sorry for the name "VLOGGER".

——Compared with OpenAI’s Sora, the netizen’s statement is indeed not unreasonable. .
What do you think?
More effects:
https://enriccorona.github.io/vlogger/
Full paper:
https://enriccorona.github .io/vlogger/paper.pdf
The above is the detailed content of Google releases 'Vlogger” model: a single picture generates a 10-second video. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to comment deepseek
Feb 19, 2025 pm 05:42 PM
How to comment deepseek
Feb 19, 2025 pm 05:42 PM
DeepSeek is a powerful information retrieval tool. Its advantage is that it can deeply mine information, but its disadvantages are that it is slow, the result presentation method is simple, and the database coverage is limited. It needs to be weighed according to specific needs.
 How to search deepseek
Feb 19, 2025 pm 05:39 PM
How to search deepseek
Feb 19, 2025 pm 05:39 PM
DeepSeek is a proprietary search engine that only searches in a specific database or system, faster and more accurate. When using it, users are advised to read the document, try different search strategies, seek help and feedback on the user experience in order to make the most of their advantages.
 Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Page Registration Link Gate Trading App Registration Website Latest
Feb 28, 2025 am 11:06 AM
This article introduces the registration process of the Sesame Open Exchange (Gate.io) web version and the Gate trading app in detail. Whether it is web registration or app registration, you need to visit the official website or app store to download the genuine app, then fill in the user name, password, email, mobile phone number and other information, and complete email or mobile phone verification.
 Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can't the Bybit exchange link be directly downloaded and installed?
Feb 21, 2025 pm 10:57 PM
Why can’t the Bybit exchange link be directly downloaded and installed? Bybit is a cryptocurrency exchange that provides trading services to users. The exchange's mobile apps cannot be downloaded directly through AppStore or GooglePlay for the following reasons: 1. App Store policy restricts Apple and Google from having strict requirements on the types of applications allowed in the app store. Cryptocurrency exchange applications often do not meet these requirements because they involve financial services and require specific regulations and security standards. 2. Laws and regulations Compliance In many countries, activities related to cryptocurrency transactions are regulated or restricted. To comply with these regulations, Bybit Application can only be used through official websites or other authorized channels
 How to download deepseek
Feb 19, 2025 pm 05:45 PM
How to download deepseek
Feb 19, 2025 pm 05:45 PM
Make sure to access official website downloads and carefully check the domain name and website design. After downloading, scan the file. Read the protocol during installation and avoid the system disk when installing. Test the function and contact customer service to solve the problem. Update the version regularly to ensure the security and stability of the software.
 Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Mobile Version Gateio Trading Platform Download Address
Feb 28, 2025 am 10:51 AM
It is crucial to choose a formal channel to download the app and ensure the safety of your account.
 Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
A detailed introduction to the login operation of the Sesame Open Exchange web version, including login steps and password recovery process. It also provides solutions to common problems such as login failure, unable to open the page, and unable to receive verification codes to help you log in to the platform smoothly.
 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
