
 Hardware Tutorial
Hardware Review
Stardust Data launches MorningStar, its first product focused on data value discovery
Hardware Tutorial
Hardware Review
Stardust Data launches MorningStar, its first product focused on data value discovery
Stardust Data launches MorningStar, its first product focused on data value discovery

On March 11, Stardust AI, a leading international AI data technology company, held its 2024 spring product launch conference in Beijing and launched MorningStar, a data closed-loop product for AI. MorningStar is the first AI data platform focused on data value discovery. Compared with traditional data management tools, this AI data discovery, management, collaboration, and iteration platform with advanced concepts, easy operation, and rich functions is designed for discovering data value. Accelerate model iteration and solve the problem of AI data debt. The creation can support the key link of efficient iteration of enterprise AI data and avoid problems such as accumulation of data debt risk, waste of low-value data costs, and long feedback chain of model training and application effects.

▲ MorningStar officially released
Currently, the MorningStar data management platform is open for applications. You can go to the official website to view more introductions and submit requirements.
1. What is MorningStar?
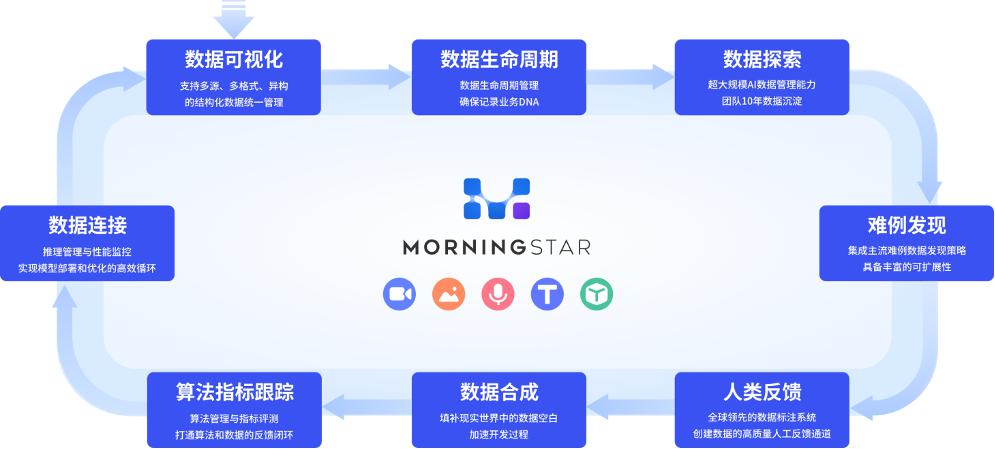
▲ MorningStar Data Closed Loop
MorningStar is an all-round tool that meets the data management needs of the AI2.0 era, aiming to improve unstructured data management for algorithm engineers. Data management efficiency saves companies data asset management costs and model online iteration time, with leading data life cycle management, comprehensive data mining tools, powerful indicator tracking and difficult case discovery capabilities, efficient and compliant data asset management and other products The advantages far exceed similar products at home and abroad, making algorithm development smoother and more agile, allowing the value of data to be fully released.
2. Who are the users of MorningStar?
By creating a data-centered collaborative environment, MorningStar can eliminate the problem of enterprise AI data debt and mainly serves three types of users: machine learning algorithm engineers, business personnel, and technical managers. For different users, MorningStar can meet various needs, covering rich usage scenarios such as data hard case discovery, model iteration, indicator tracking; data value mining, business effect feedback, operational testing; data element management and enterprise value precipitation.
3. Why choose MorningStar?
Data technology has promoted three changes in artificial intelligence. In the era of big models, all walks of life need to create super employees based on their own data to improve enterprise production efficiency. Models and computing power can be purchased, but data requires refined and full-process management to unlock real value. Enterprises need to build a discoverable, manageable, collaborative, and iterable data pipeline to have the ability to obtain data, produce data, and continuously iterate data, and promote internal data-centered collaboration to obtain data in the AI 2.0 era. core competitiveness.
MorningStar is the only closed-loop data product on the market specifically designed for enterprises in the AI 2.0 era. It comprehensively covers closed-loop links such as data management, iteration, optimization, and mining of AI algorithms from training to production. , is committed to helping enterprises establish efficient data closed-loop systems, maximize data value and optimize model effects, and help create differentiated competitiveness barriers.

▲ MorningStar product advantages
(1) Leading data life cycle management
Algorithm engineers can use MorningStar to manage the life cycle of AI data, strengthen data version control, fast data slicing, traceable data lineage and security control. The platform's automated workflow ensures that data is properly managed and optimized at every stage.
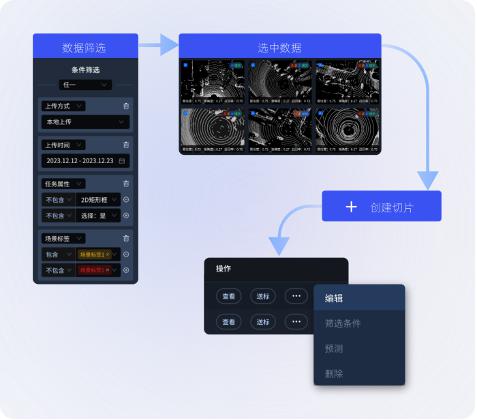
▲Data slicing
Flexible data slicing function allows algorithm engineers to select the algorithm iteration data direction with one click for subsequent data processing processes.
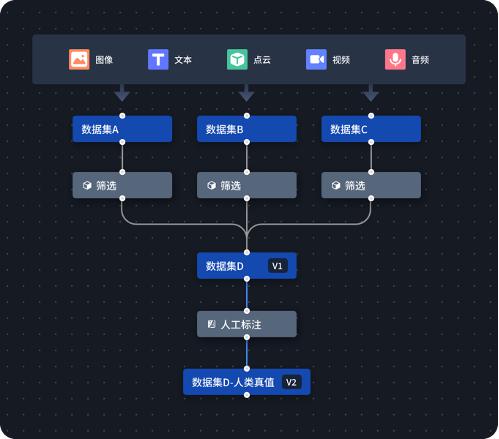
▲Data flow: Record the version production process of data containing different semantic information
Data process orchestration and scheduling, algorithm engineers can easily record the data processing process and semantic results and perform version management, record the full life cycle data information, and ensure the traceability of data and the reproducibility of operations.
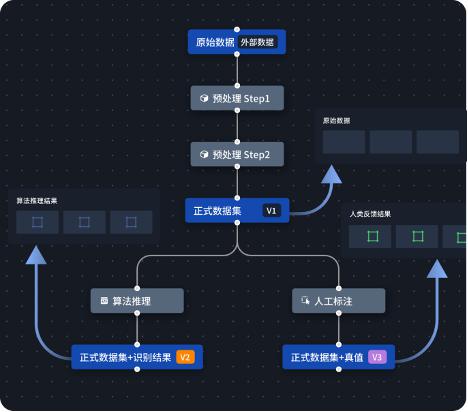
▲Data flow: data source and data delivery
Algorithm engineers can conduct model true value comparison through the platform, through a series of data tracing and model debugging and analysis generation tools to discover difficult data and send it to the Rosetta data annotation system with one click.
(2) Comprehensive data mining tool
MorningStar supports in-depth mining of data value, including fine-grained visualization, indicator calculation, data distribution exploration, and cross-modal data Retrieval, etc., can obtain the optimal algorithm at a lower cost through manual supervision, semantic retrieval, feature generation and data enhancement, and help users discover and solve problems in model training through visual data mining logic.
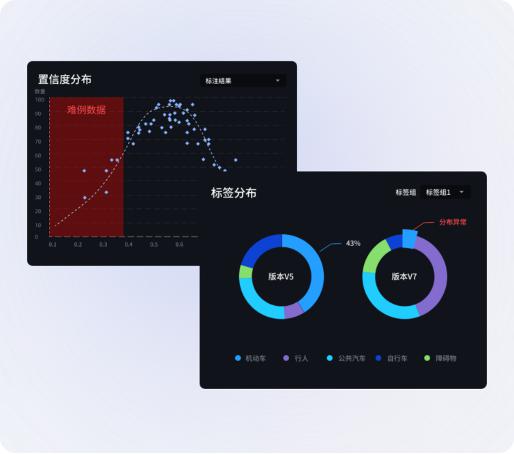
▲Distribution visualization
The above figure shows MorningStar’s ability to find difficult case data and data with abnormal label distribution through visual data mining logic. It has rich Scalability.
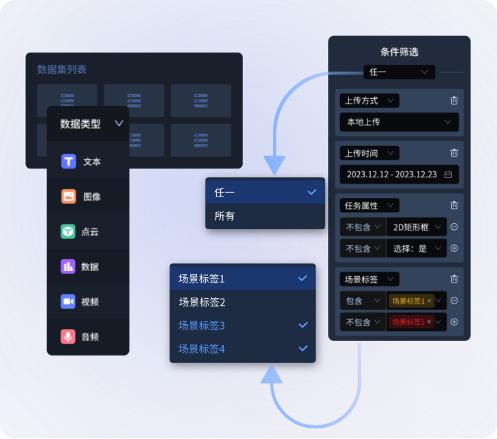
▲Data exploration
Algorithm engineers can use MorningStar to conduct data retrieval in various scenarios and dimensions, quickly grasp the data situation, and formulate algorithm experiment ideas .
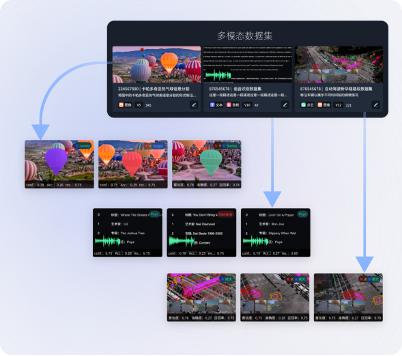
MorningStar supports various types of multi-modal data visualization and semantic retrieval, making it easier and faster to directionally mine the high-value data required.
(3) Powerful indicator tracking and difficult case discovery capabilities
As the first data closed-loop product that integrates difficult case discovery strategies, MorningStar can ensure that the model training process is reliable Trace iterable. Through a series of data tracing, model debugging and analysis generation tools, it helps to realize and maintain high-quality and reproducible Al models.
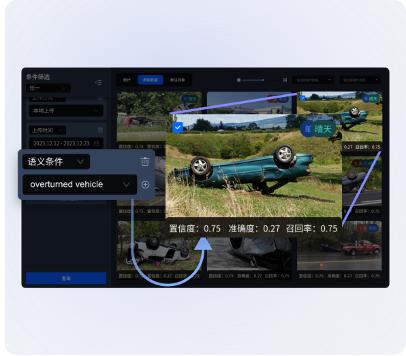
▲Data traceability: Through data flow, the data used for algorithm evaluation can be traced to the source at any time.
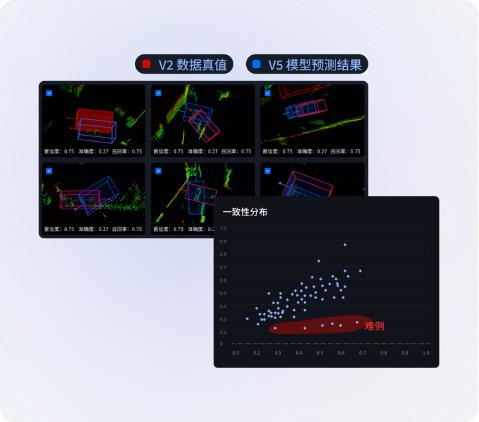
▲Version comparison
By selecting different data versions, the algorithm prediction results and the true value can be compared, and the visualization function can be used to conveniently locate and analyze difficult case data .
▲Indicator tracking and effect detection
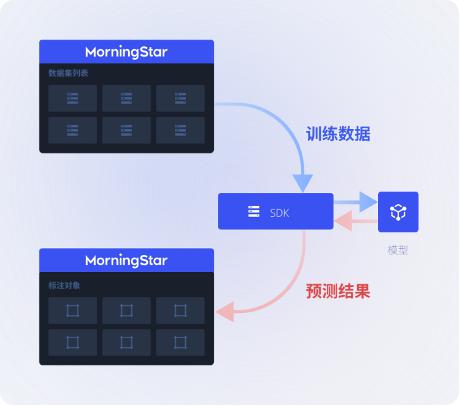
MorningStar uses SDK to conveniently connect the model training environment, training data analysis management, and indicator analysis environment, and conveniently carry out algorithms Iterate.
(4) Efficient and compliant data asset management
MorningStar supports comprehensive analysis of data sets and helps business managers achieve enterprise-level data element management and analysis , presenting asset information from data asset scale, content distribution, ownership and other dimensions at a glance.
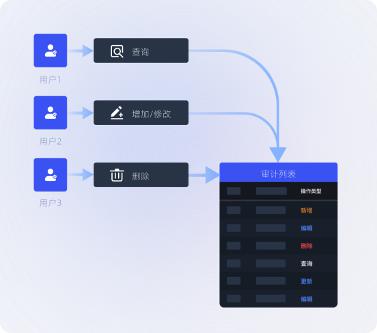
▲Data Compliance Audit
Teams can integrate data assets and share use value through MorningStar. Through authority management and usage records, data circulation between departments is accelerated while ensuring data security.

▲Data asset display
In addition, MorningStar integrates multi-source, multi-format, heterogeneous data, manages ultra-large capacity data, and realizes visual modeling of enterprise assets ; Support the classification and inventory of multi-dimensional fine-grained data, promote in-depth understanding of internal data within the enterprise, and improve the efficiency of data flow in cross-department collaboration within the enterprise.

The above figure shows the popularity value ranking of data sets through MorningStar. The value of data assets to algorithm iteration is evaluated through data usage times, scene labels, annotation results, etc. to help data elements. economic benefit analysis.
(5) More functions
As an excellent algorithm engineer, are you still using original self-built tools, temporary tools, or even Excel to process data? As a professional AI data discovery, management, collaboration, and iteration platform, MorningStar not only allows you to perform the above advanced operations, but also has a wealth of practical functions! For example, it supports the unified management of multi-source, multi-format, and heterogeneous structured data; supports SDK, can perform model performance evaluation and monitoring, and obtain a comprehensive model evaluation report.
It is worth mentioning that the CIF-Bench automated evaluation created by Stardust Data and Hong Kong University of Science and Technology will soon be launched on MorningStar! The 28 model evaluation lists focus on evaluating 20 basic dimensions and examining the model's ability to follow instructions on 150 types of tasks. List link: https://yizhillll.github.io/CIF-Bench/.
An autonomous driving algorithm engineer once reported that difficult cases that originally took a day to discover can only be found through the platform in 1-2 hours, greatly improving iteration efficiency.
In the future, MorningStar will continue to carry out iterative updates. Users are welcome to give us valuable suggestions and work with us to reconstruct data closed-loop management to make AI algorithm iterations more efficient!
5. MorningStar is officially released
According to Stardust Data founder & CEO Zhang Lei: "In the AI 2.0 era, mastering your own data means mastering your own model." The core of enterprise data value lies in defining, managing and iterating data. In the ever-evolving wave of AI technology, continuous management, optimization and iteration of data will become a key factor for enterprises to stand out in the AI2.0 era. If your company hopes to use its own data and tens of billions of large-scale models to create its own super employees, MorningStar sincerely invites you to communicate with us. No matter what type of user you are with AI data management needs, MorningStar can provide comprehensive solutions and flexible usage methods, including SaaS, enterprise privatization deployment, and support for customized software development.
Product official website address: https://stardust.ai/MorningStar
Requirement submission address: https://stardust.ai/contact
The above is the detailed content of Stardust Data launches MorningStar, its first product focused on data value discovery. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Detailed explanation of database ACID attributes ACID attributes are a set of rules to ensure the reliability and consistency of database transactions. They define how database systems handle transactions, and ensure data integrity and accuracy even in case of system crashes, power interruptions, or multiple users concurrent access. ACID Attribute Overview Atomicity: A transaction is regarded as an indivisible unit. Any part fails, the entire transaction is rolled back, and the database does not retain any changes. For example, if a bank transfer is deducted from one account but not increased to another, the entire operation is revoked. begintransaction; updateaccountssetbalance=balance-100wh
 The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The primary key of mysql can be null
Apr 08, 2025 pm 03:03 PM
The MySQL primary key cannot be empty because the primary key is a key attribute that uniquely identifies each row in the database. If the primary key can be empty, the record cannot be uniquely identifies, which will lead to data confusion. When using self-incremental integer columns or UUIDs as primary keys, you should consider factors such as efficiency and space occupancy and choose an appropriate solution.
 Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
Master SQL LIMIT clause: Control the number of rows in a query
Apr 08, 2025 pm 07:00 PM
SQLLIMIT clause: Control the number of rows in query results. The LIMIT clause in SQL is used to limit the number of rows returned by the query. This is very useful when processing large data sets, paginated displays and test data, and can effectively improve query efficiency. Basic syntax of syntax: SELECTcolumn1,column2,...FROMtable_nameLIMITnumber_of_rows;number_of_rows: Specify the number of rows returned. Syntax with offset: SELECTcolumn1,column2,...FROMtable_nameLIMIToffset,number_of_rows;offset: Skip
