
 Technology peripherals
AI
CMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds
Technology peripherals
AI
CMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds
CMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds

A simple sketch can be transformed into a multi-style painting with one click, and additional descriptions can be added. This was achieved in a study jointly launched by CMU and Adobe.
CMU Assistant Professor Junyan Zhu is an author of the study, and his team published a related study at the ICCV 2021 conference. This study shows how an existing GAN model can be customized with a single or a few hand-drawn sketches to generate images that match the sketch.

- Paper address: https://arxiv.org/pdf/2403.12036.pdf
- GitHub address: https://github.com/GaParmar/img2img-turbo
- Trial address: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
- Paper title: One-Step Image Translation with Text -to-Image Models
How effective is it? We tried it out and came to the conclusion that it is very playable. The output image styles are diverse, including cinematic style, 3D models, animation, digital art, photography style, pixel art, fantasy school, neon punk and comics.
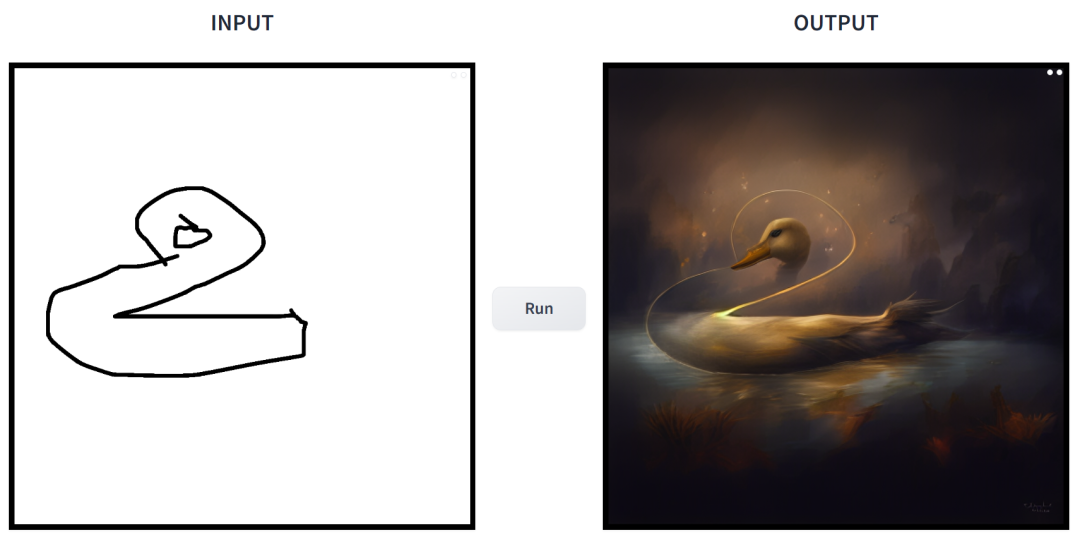
prompt is "duck".
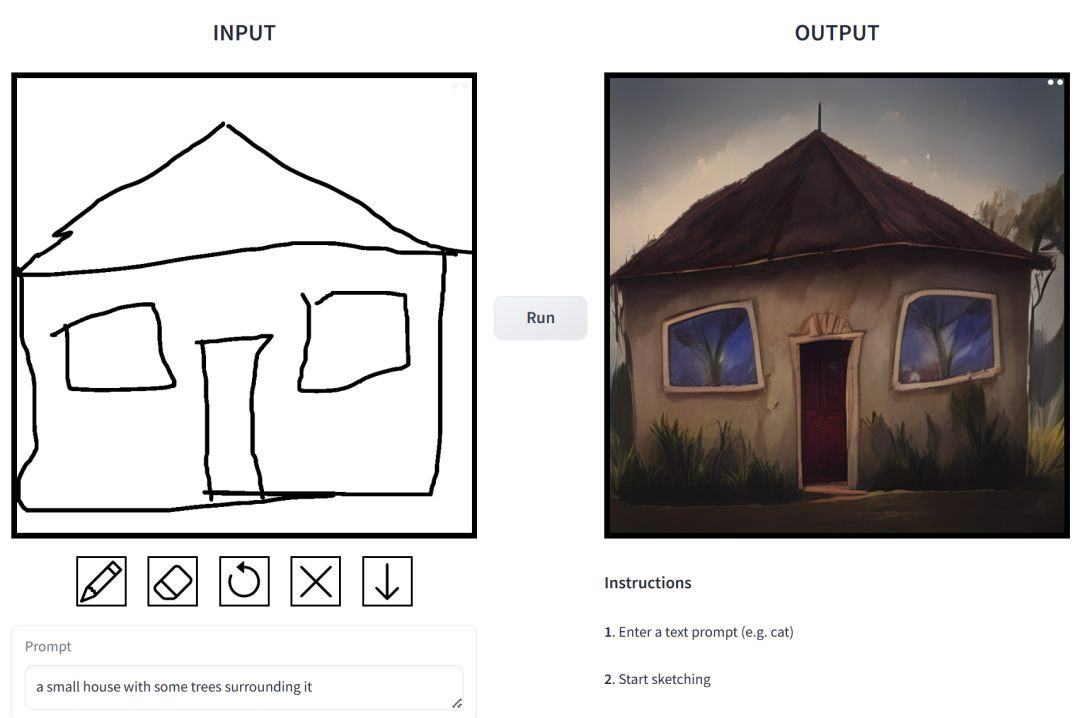
prompt is "a small house surrounded by vegetation".
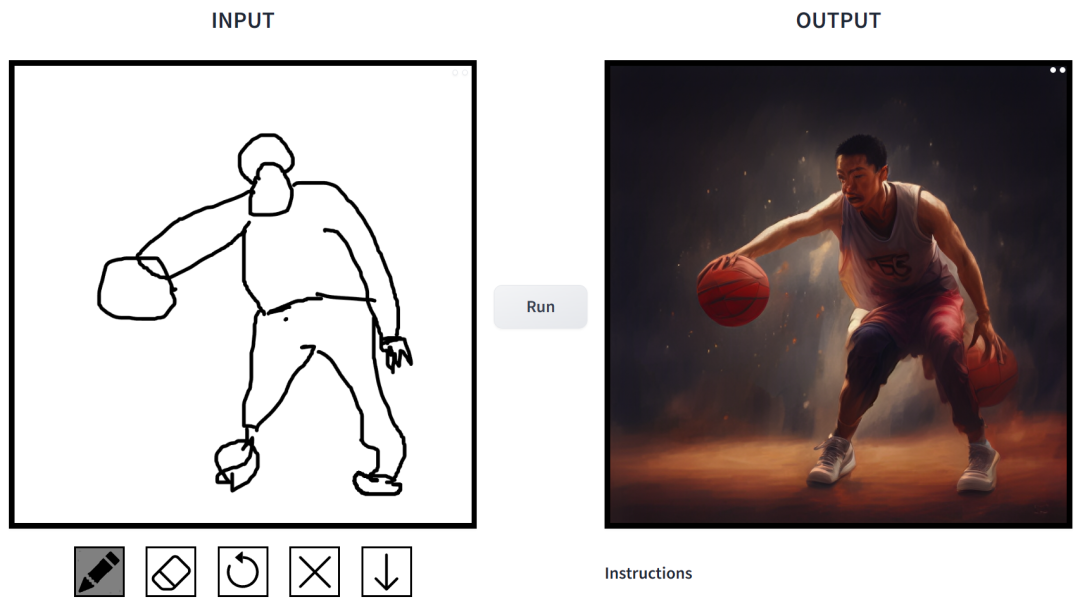
prompt is "Chinese boys playing basketball".
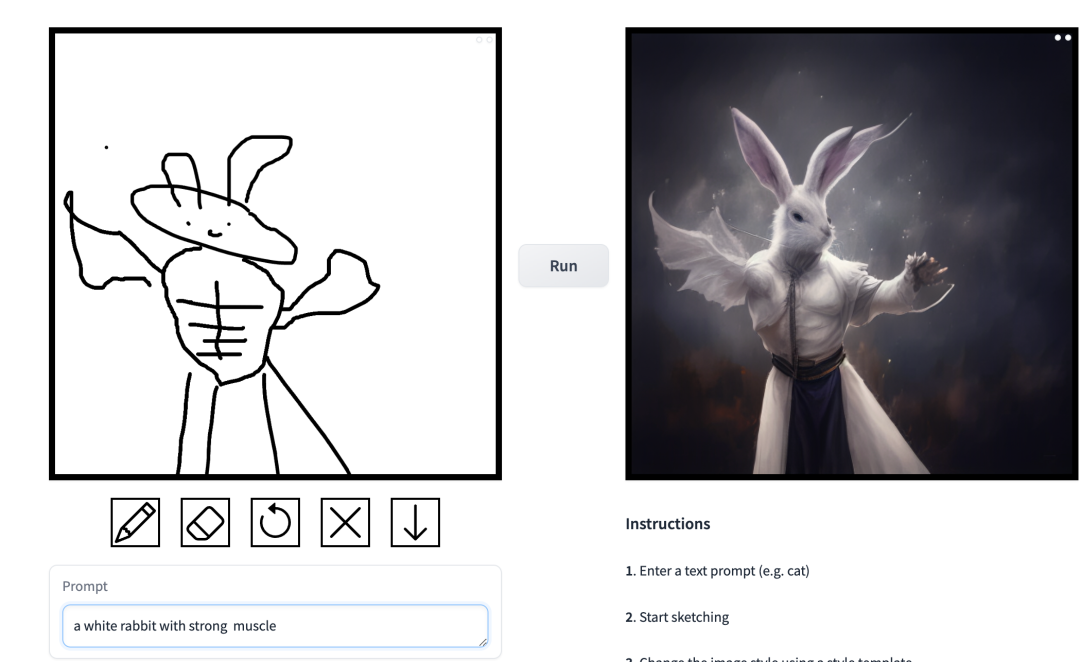
prompt is "Muscle Man Rabbit".
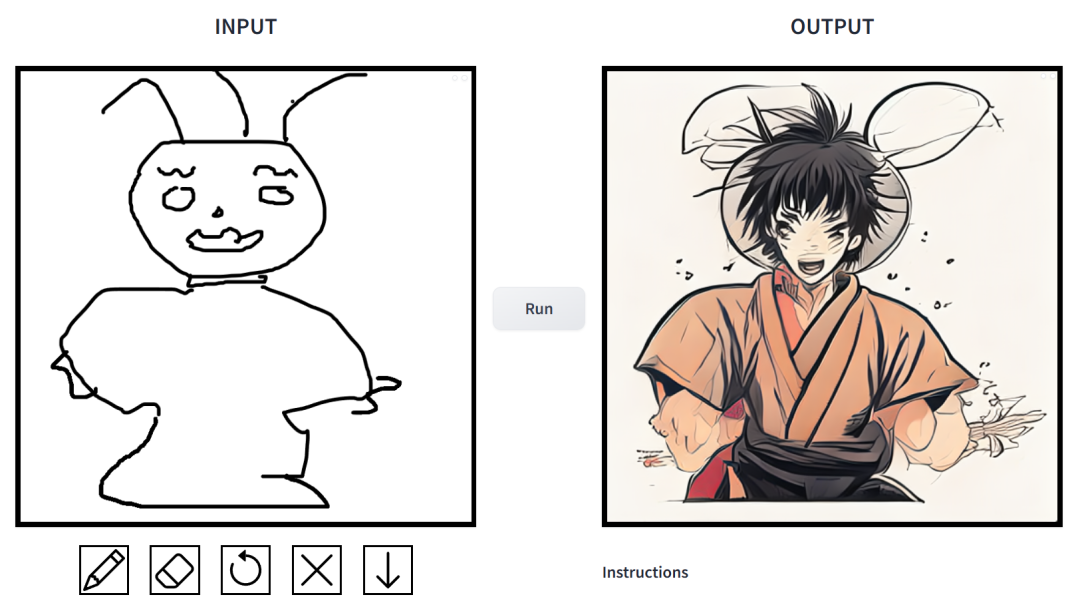

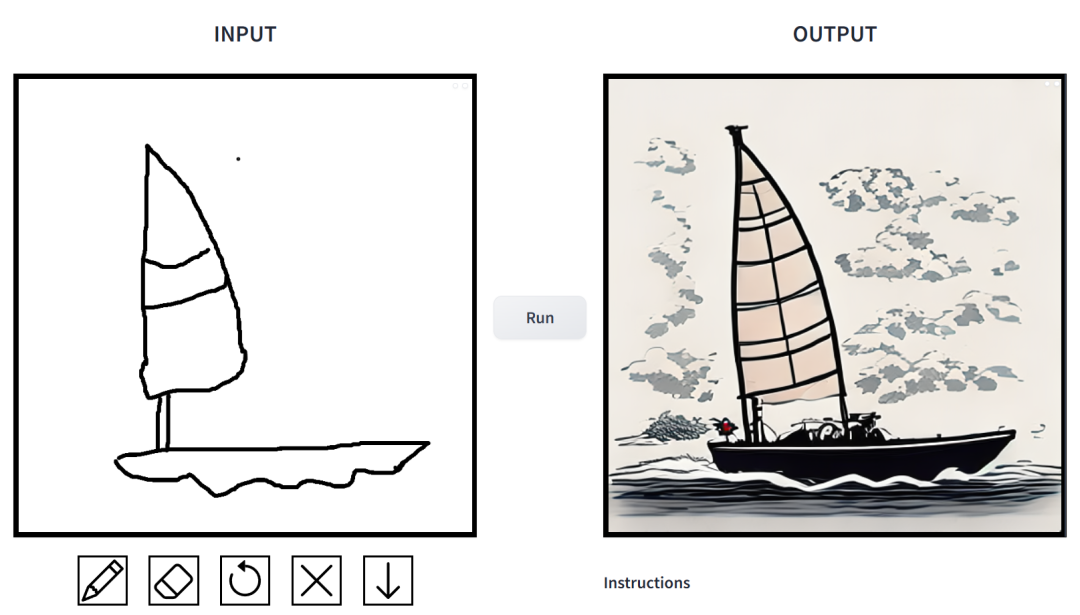 #
#
In this work, researchers have made targeted improvements to the problems existing in the application of conditional diffusion models in image synthesis. Such models allow users to generate images based on spatial conditions and text prompts, with precise control over scene layout, user sketches, and human poses.
But the problem is that the iteration of the diffusion model causes the inference speed to slow down, limiting real-time applications, such as interactive Sketch2Photo. In addition, model training usually requires large-scale paired data sets, which brings huge costs to many applications and is not feasible for some other applications.
In order to solve the problems of the conditional diffusion model, researchers have introduced a general method that uses adversarial learning objectives to adapt the single-step diffusion model to new tasks and new fields. Specifically, they integrate individual modules of a vanilla latent diffusion model into a single end-to-end generator network with small trainable weights, thereby enhancing the model's ability to preserve the structure of the input image while reducing overfitting.
Researchers have launched the CycleGAN-Turbo model. In an unpaired setting, this model can outperform existing GAN and diffusion-based methods in various scene conversion tasks, such as day and night. Convert, add or remove weather effects such as fog, snow, rain.
At the same time, in order to verify the versatility of their own architecture, the researchers conducted experiments on paired settings. The results show that their model pix2pix-Turbo achieves visual effects comparable to Edge2Image and Sketch2Photo, and reduces the inference step to 1 step.
In summary, this work demonstrates that one-step pre-trained text-to-image models can serve as a powerful, versatile backbone for many downstream image generation tasks.
Method introduction
This study proposes a general method that combines a single-step diffusion model (such as SD-Turbo) with adversarial learning Adapt to new tasks and domains. This leverages the internal knowledge of the pre-trained diffusion model while enabling efficient inference (e.g., 0.29 seconds on the A6000 and 0.11 seconds on the A100 for a 512x512 image).
Additionally, the single-step conditional models CycleGAN-Turbo and pix2pix-Turbo can perform a variety of image-to-image translation tasks, suitable for both pairwise and non-pairwise settings. CycleGAN-Turbo surpasses existing GAN-based and diffusion-based methods, while pix2pix-Turbo is on par with recent work such as ControlNet for Sketch2Photo and Edge2Image, but with the advantage of single-step inference.
Add conditional input
In order to convert the text-to-image model into an image-conversion model, the first thing to do is Find an efficient way to incorporate the input image x into the model.
A common strategy for incorporating conditional inputs into Diffusion models is to introduce additional adapter branches, as shown in Figure 3.
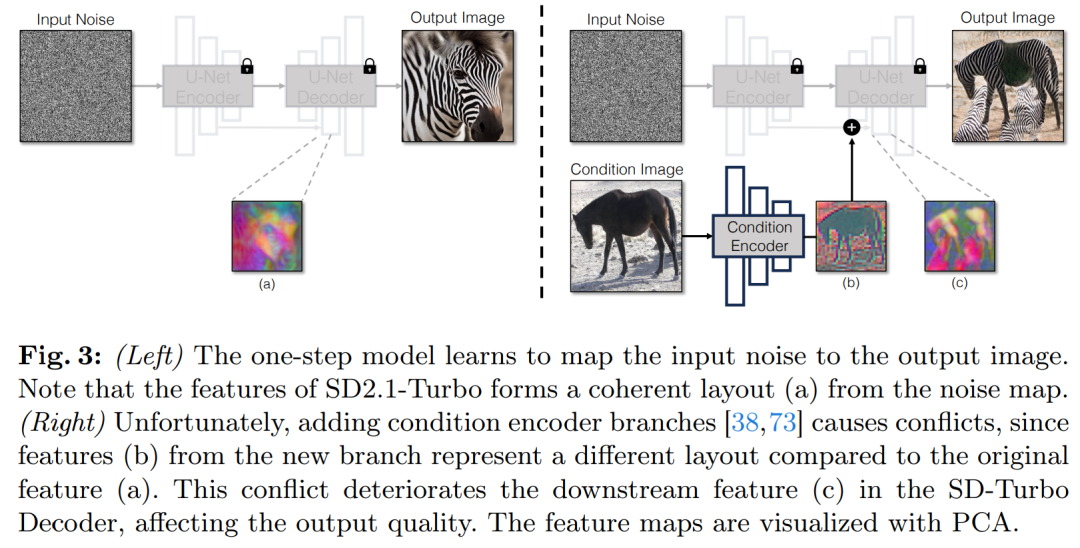
Specifically, this study initializes a second encoder and labels it as a condition encoder (Condition Encoder). The Control Encoder accepts the input image x and outputs feature maps of multiple resolutions to the pre-trained Stable Diffusion model through residual connections. This method achieves remarkable results in controlling diffusion models.
As shown in Figure 3, this study uses two encoders (U-Net encoder and conditional encoder) in a single-step model to process noisy images and input image encounters challenges. Unlike multi-step diffusion models, the noise map in single-step models directly controls the layout and pose of the generated image, which often contradicts the structure of the input image. Therefore, the decoder receives two sets of residual features representing different structures, which makes the training process more challenging.
Direct conditional input. Figure 3 also illustrates that the image structure generated by the pre-trained model is significantly affected by the noise map z. Based on this insight, the study recommends feeding conditional inputs directly to the network. To adapt the backbone model to new conditions, the study added several LoRA weights to various layers of U-Net (see Figure 2).
Preserve input details
Latent diffusion models (LDMs) image encoders work by spatially resolving the input image into The rate compression is 8 times while increasing the number of channels from 3 to 4 to speed up the training and inference process of the diffusion model. While this design can speed up training and inference, it may not be ideal for image conversion tasks that require preserving the details of the input image. Figure 4 illustrates this problem, where we take an input image of daytime driving (left) and convert it to a corresponding image of nighttime driving, using an architecture that does not use skip connections (center). It can be observed that fine-grained details such as text, street signs, and distant cars are not preserved. In contrast, the resulting transformed image using an architecture that includes skip connections (right) does a better job of preserving these complex details.

To capture the fine-grained visual details of the input image, the study added skip connections between the encoder and decoder networks (see Figure 2 ). Specifically, the study extracts four intermediate activations after each downsampling block within the encoder and processes them through a 1 × 1 zero convolutional layer before feeding them into the corresponding upsampling block in the decoder. . This approach ensures that intricate details are preserved during image conversion.
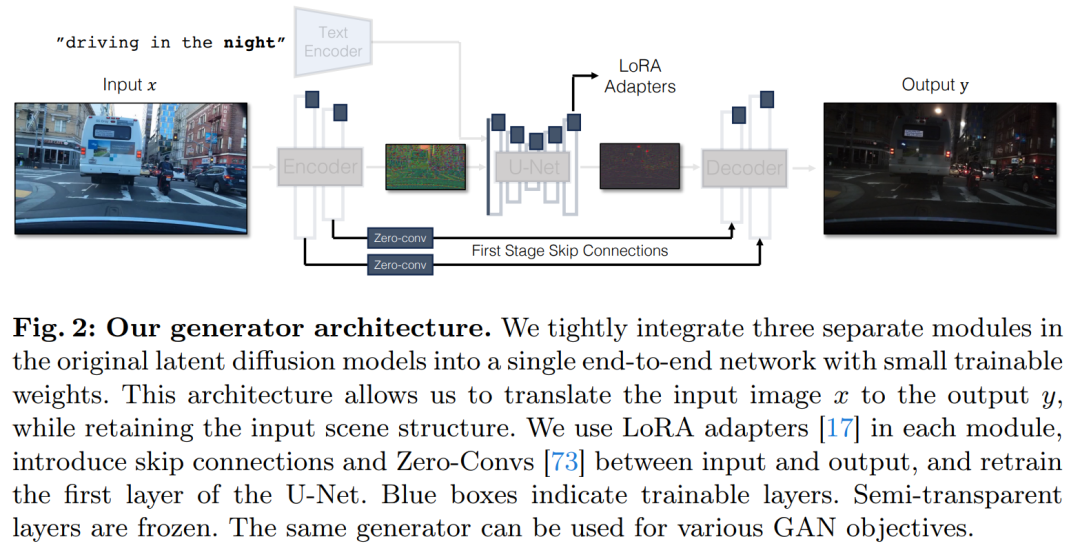
Experiment
This study combines CycleGAN-Turbo with previous GAN-based non-paired images Conversion methods were compared. From a qualitative analysis, Figure 5 and Figure 6 show that neither the GAN-based method nor the diffusion-based method can achieve a balance between output image realism and maintaining structure.


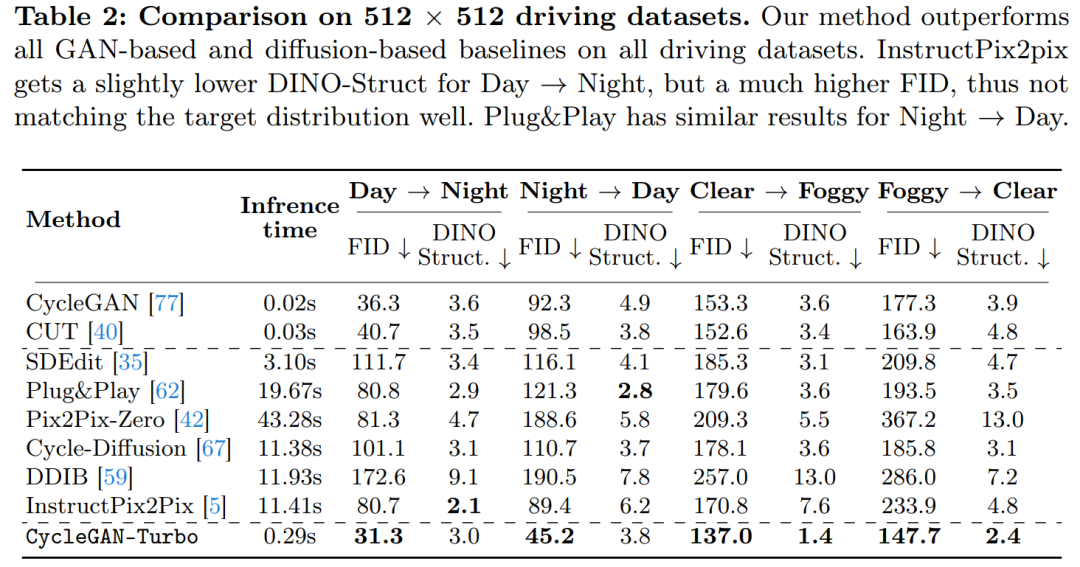
The study also compared CycleGAN-Turbo to CycleGAN and CUT. Tables 1 and 2 present the results of quantitative comparisons on eight unpaired switching tasks.
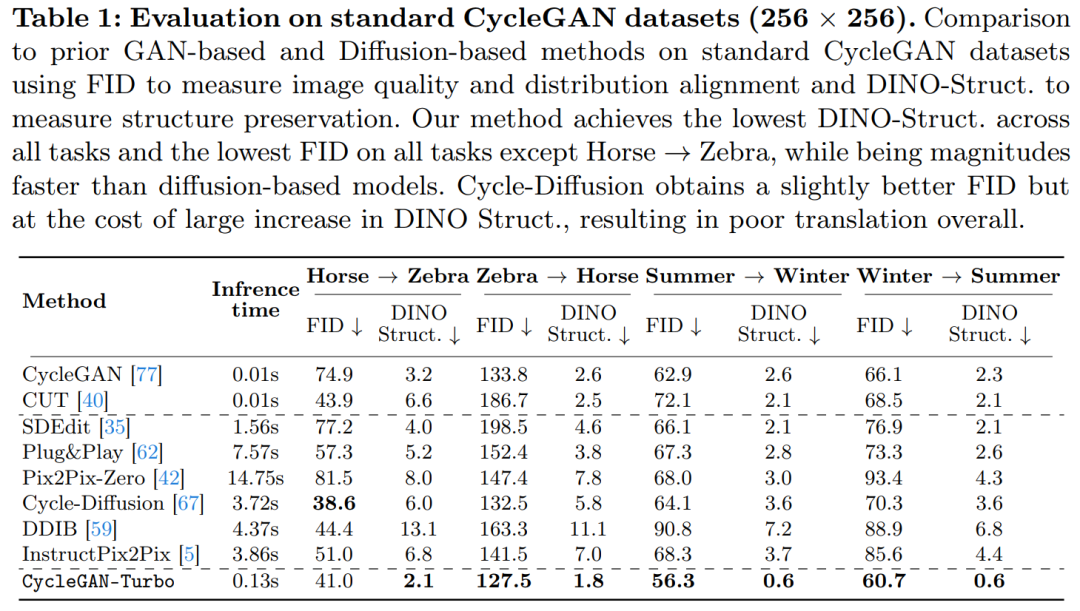
##CycleGAN and CUT on simpler, object-centric data On the set, such as horse → zebra (Fig. 13), it shows effective performance and achieves low FID and DINO-Structure scores. Our method slightly outperforms these methods in FID and DINO-Structure distance metrics.

As shown in Table 1 and Figure 14, in the object-centered data set (such as horse → zebra) These methods can generate realistic zebras, but have difficulties in accurately matching object poses.
On the driving dataset, these editing methods perform significantly worse for three reasons: (1) the model has difficulty generating complex scenes containing multiple objects, (2) these methods ( Except for Instruct-pix2pix) the image needs to be inverted into a noise map first, introducing potential human error, (3) the pre-trained model cannot synthesize street view images similar to those captured by the driving dataset. Table 2 and Figure 16 show that on all four driving transition tasks, these methods output images of poor quality and do not follow the structure of the input image.


The above is the detailed content of CMU Zhu Junyan and Adobe's new work: 512x512 image inference, A100 only takes 0.11 seconds. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 How to Download Windows Spotlight Wallpaper Image on PC
Aug 23, 2023 pm 02:06 PM
How to Download Windows Spotlight Wallpaper Image on PC
Aug 23, 2023 pm 02:06 PM
Windows are never one to neglect aesthetics. From the bucolic green fields of XP to the blue swirling design of Windows 11, default desktop wallpapers have been a source of user delight for years. With Windows Spotlight, you now have direct access to beautiful, awe-inspiring images for your lock screen and desktop wallpaper every day. Unfortunately, these images don't hang out. If you have fallen in love with one of the Windows spotlight images, then you will want to know how to download them so that you can keep them as your background for a while. Here's everything you need to know. What is WindowsSpotlight? Window Spotlight is an automatic wallpaper updater available from Personalization > in the Settings app
 A deep dive into models, data, and frameworks: an exhaustive 54-page review of efficient large language models
Jan 14, 2024 pm 07:48 PM
A deep dive into models, data, and frameworks: an exhaustive 54-page review of efficient large language models
Jan 14, 2024 pm 07:48 PM
Large-scale language models (LLMs) have demonstrated compelling capabilities in many important tasks, including natural language understanding, language generation, and complex reasoning, and have had a profound impact on society. However, these outstanding capabilities require significant training resources (shown in the left image) and long inference times (shown in the right image). Therefore, researchers need to develop effective technical means to solve their efficiency problems. In addition, as can be seen from the right side of the figure, some efficient LLMs (LanguageModels) such as Mistral-7B have been successfully used in the design and deployment of LLMs. These efficient LLMs can significantly reduce inference memory while maintaining similar accuracy to LLaMA1-33B
 The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Sep 25, 2023 pm 04:49 PM
The most comprehensive review of multimodal large models is here! 7 Microsoft researchers cooperated vigorously, 5 major themes, 119 pages of document
Sep 25, 2023 pm 04:49 PM
The most comprehensive review of multimodal large models is here! Written by 7 Chinese researchers at Microsoft, it has 119 pages. It starts from two types of multi-modal large model research directions that have been completed and are still at the forefront, and comprehensively summarizes five specific research topics: visual understanding and visual generation. The multi-modal large-model multi-modal agent supported by the unified visual model LLM focuses on a phenomenon: the multi-modal basic model has moved from specialized to universal. Ps. This is why the author directly drew an image of Doraemon at the beginning of the paper. Who should read this review (report)? In the original words of Microsoft: As long as you are interested in learning the basic knowledge and latest progress of multi-modal basic models, whether you are a professional researcher or a student, this content is very suitable for you to come together.
 How to use image semantic segmentation technology in Python?
Jun 06, 2023 am 08:03 AM
How to use image semantic segmentation technology in Python?
Jun 06, 2023 am 08:03 AM
With the continuous development of artificial intelligence technology, image semantic segmentation technology has become a popular research direction in the field of image analysis. In image semantic segmentation, we segment different areas in an image and classify each area to achieve a comprehensive understanding of the image. Python is a well-known programming language. Its powerful data analysis and data visualization capabilities make it the first choice in the field of artificial intelligence technology research. This article will introduce how to use image semantic segmentation technology in Python. 1. Prerequisite knowledge is deepening
 Crushing H100, Nvidia's next-generation GPU is revealed! The first 3nm multi-chip module design, unveiled in 2024
Sep 30, 2023 pm 12:49 PM
Crushing H100, Nvidia's next-generation GPU is revealed! The first 3nm multi-chip module design, unveiled in 2024
Sep 30, 2023 pm 12:49 PM
3nm process, performance surpasses H100! Recently, foreign media DigiTimes broke the news that Nvidia is developing the next-generation GPU, the B100, code-named "Blackwell". It is said that as a product for artificial intelligence (AI) and high-performance computing (HPC) applications, the B100 will use TSMC's 3nm process process, as well as more complex multi-chip module (MCM) design, and will appear in the fourth quarter of 2024. For Nvidia, which monopolizes more than 80% of the artificial intelligence GPU market, it can use the B100 to strike while the iron is hot and further attack challengers such as AMD and Intel in this wave of AI deployment. According to NVIDIA estimates, by 2027, the output value of this field is expected to reach approximately
 How to batch resize images using PowerToys on Windows
Aug 23, 2023 pm 07:49 PM
How to batch resize images using PowerToys on Windows
Aug 23, 2023 pm 07:49 PM
Those who have to work with image files on a daily basis often have to resize them to fit the needs of their projects and jobs. However, if you have too many images to process, resizing them individually can consume a lot of time and effort. In this case, a tool like PowerToys can come in handy to, among other things, batch resize image files using its image resizer utility. Here's how to set up your Image Resizer settings and start batch resizing images with PowerToys. How to Batch Resize Images with PowerToys PowerToys is an all-in-one program with a variety of utilities and features to help you speed up your daily tasks. One of its utilities is images
 iOS 17: How to use one-click cropping in photos
Sep 20, 2023 pm 08:45 PM
iOS 17: How to use one-click cropping in photos
Sep 20, 2023 pm 08:45 PM
With the iOS 17 Photos app, Apple makes it easier to crop photos to your specifications. Read on to learn how. Previously in iOS 16, cropping an image in the Photos app involved several steps: Tap the editing interface, select the crop tool, and then adjust the crop using a pinch-to-zoom gesture or dragging the corners of the crop tool. In iOS 17, Apple has thankfully simplified this process so that when you zoom in on any selected photo in your Photos library, a new Crop button automatically appears in the upper right corner of the screen. Clicking on it will bring up the full cropping interface with the zoom level of your choice, so you can crop to the part of the image you like, rotate the image, invert the image, or apply screen ratio, or use markers
 How to edit photos on iPhone using iOS 17
Nov 30, 2023 pm 11:39 PM
How to edit photos on iPhone using iOS 17
Nov 30, 2023 pm 11:39 PM
Mobile photography has fundamentally changed the way we capture and share life’s moments. The advent of smartphones, especially the iPhone, played a key role in this shift. Known for its advanced camera technology and user-friendly editing features, iPhone has become the first choice for amateur and experienced photographers alike. The launch of iOS 17 marks an important milestone in this journey. Apple's latest update brings an enhanced set of photo editing features, giving users a more powerful toolkit to turn their everyday snapshots into visually engaging and artistically rich images. This technological development not only simplifies the photography process but also opens up new avenues for creative expression, allowing users to effortlessly inject a professional touch into their photos
