

MySQL服务维护笔记 续_MySQL

服务的备份
尽量使用MySQL DUMP而不是直接备份数据文件,以下是一个按weekday将数据轮循备份的脚本:备份的间隔和周期可以根据备份的需求确定
/home/mysql/bin/mysqldump -S/data/app_1/mysql.sock -umysql db_name | gzip -f>/path/to/backup/db_name.`data +%w`.dump.gz
因此写在CRONTAB中一般是:
15 4 * * * /home/mysql/bin/mysqldump -S/data/app_1/mysql.sock -umysql db_name | gzip -f>/path/to/backup/db_name.`data +/%w`.dump.gz
注意:
1. 在crontab中'%'需要转义成'/%'
2. 根据日志统计,应用负载最低的时候一般是在早上4-6点
先备份在本地然后传到远程的备份服务器上,或者直接建立一个数据库备份帐号,直接在远程的服务器上备份,远程备份只需要将以上脚本中的-S /path/to/msyql.sock改成-h IP.ADDRESS即可。
数据的恢复和系统的升级
日常维护和数据迁移:在数据盘没有被破坏的情况下硬盘一般是系统中寿命最低的硬件。而系统(包括操作系统和MySQL应用)的升级和硬件升级,都会遇到数据迁移的问题。
只要数据不变,先装好服务器,然后直接将数据盘(硬盘2)安装上,只需要将启动脚本重新加入到rc.local文件中,系统就算是很好的恢复了。
灾难恢复:数据库数据本身被破坏的情况下确定破坏的时间点,然后从备份数据中恢复。
应用的设计要点
如果MySQL应用占用的CPU超过10%就应该考虑优化了。
如果这个服务可以被其他非数据库应用代替(比如很多基于数据库的计数器完全可以用WEB日志统计代替)最好将其禁用:
非用数据库不可吗?虽然数据库的确可以简化很多应用的结构设计,但本身也是一个系统资源消耗比较大的应用。在某些情况下文本,DBM比数据库是更好的选择,比如:很多应用如果没有很高的实时统计需求的话,完全可以先记录到文件日志中,定期的导入到数据库中做后续统计分析。如果还是需要记录简单的2维键-值对应结构的话可以使用类似于DBM的HEAP类型表。因为HEAP表全部在内存中存取,效率非常高,但服务器突然断电时有可能出现数据丢失,所以非常适合存储在线用户信息,日志等临时数据。即使需要使用数据库的,应用如果没有太复杂的数据完整性需求的化,完全可以不使用那些支持外键的商业数据库,比如MySQL。只有非常需要完整的商业逻辑和事务完整性的时候才需要Oracle这样的大型数据库。对于高负载应用来说完全可以把日志文件,DBM,MySQL等轻量级方式做前端数据采集格式,然后用Oracle MSSQL DB2 Sybase等做数据库仓库以完成复杂的数据库挖掘分析工作。
有朋友和我说用标准的MyISAM表代替了InnoDB表以后,数据库性能提高了20倍。
数据库服务的主要瓶颈:单个服务的连接数对于一个应用来说,如果数据库表结构的设计能够按照数据库原理的范式来设计的话,并且已经使用了最新版本的MySQL,并且按照比较优化的方式运行了,那么最后的主要瓶颈一般在于单个服务的连接数,即使一个数据库可以支持并发500个连接,最好也不要把应用用到这个地步,因为并发连接数过多数据库服务本身用于调度的线程的开销也会非常大了。所以如果应用允许的话:让一台机器多跑几个MySQL服务分担。将服务均衡的规划到多个MySQL服务端口上:比如app_1 ==> 3301 app_2 ==> 3302...app_9 ==> 3309。一个1G内存的机器跑上10个MySQL是很正常的。让10个MySQLD承担1000个并发连接效率要比让2个MySQLD承担1000个效率高的多。当然,这样也会带来一些应用编程上的复杂度;
使用单独的数据库服务器(不要让数据库和前台WEB服务抢内存),MySQL拥有更多的内存就可能能有效的进行结果集的缓存;在前面的启动脚本中有一个-O key_buffer=32M参数就是用于将缺省的8M索引缓存增加到32M(当然对于)
应用尽量使用PCONNECT和polling机制,用于节省MySQL服务建立连接的开销,但也会造成MySQL并发链接数过多(每个HTTPD都会对应一个MySQL线程);
表的横向拆分:让最常被访问的10%的数据放在一个小表里,90%的历史数据放在一个归档表里(所谓:快慢表),数据中间通过定期“搬家”和定期删除无效数据来节省,毕竟大部分应用(比如论坛)访问2个月前数据的几率会非常少,而且价值也不是很高。这样对于应用来说总是在一个比较小的结果级中进行数据选择,比较有利于数据的缓存,不要指望MySQL中对单表记录条数在10万级以上还有比较高的效率。而且有时候数据没有必要做那么精确,比如一个快表中查到了某个人发表的文章有60条结果,快表和慢表的比例是1:20,那么就可以简单的估计这个人一共发表了1200篇。Google的搜索结果数也是一样:对于很多上十万的结果数,后面很多的数字都是通过一定的算法估计出来的。
数据库字段设计:表的纵向拆分(过渡范化):将所有的定长字段(char, int等)放在一个表里,所有的变长字段(varchar,text,blob等)放在另外一个表里,2个表之间通过主键关联,这样,定长字段表可以得到很大的优化(这样可以使用HEAP表类型,数据完全在内存中存取),这里也说明另外一个原则,对于我们来说,尽量使用定长字段可以通过空间的损失换取访问效率的提高。在MySQL4中也出现了支持外键和事务的InnoDB类型表,标准的MyISAM格式表和基于HASH结构的HEAP内存表,MySQL之所以支持多种表类型,实际上是针对不同应用提供了不同的优化方式;
仔细的检查应用的索引设计:可以在服务启动参数中加入 --log-slow-queries[=file]用于跟踪分析应用瓶颈,对于跟踪服务瓶颈最简单的方法就是用MySQL的status查看MySQL服务的运行统计和show processlist来查看当前服务中正在运行的SQL,如果某个SQL经常出现在PROCESS LIST中,一.有可能被查询的此时非常多,二.里面有影响查询的字段没有索引,三.返回的结果数过多数据库正在排序(SORTING);所以做一个脚本:比如每2秒运行以下show processlist;把结果输出到文件中,看到底是什么查询在吃CPU。
全文检索:如果相应字段没有做全文索引的话,全文检索将是一个非常消耗CPU的功能,因为全文检索是用不上一般数据库的索引的,所以要进行相应字段记录遍历。关于全文索引可以参考一下基于Java的全文索引引擎lucene的介绍。
前台应用的记录缓存:比如一个经常使用数据库认证,如果需要有更新用户最后登陆时间的操作,最好记录更新后就把用户放到一个缓存中(设置2个小时后过期),这样如果用户在2个小时内再次使用到登陆,就直接从缓存里认证,避免了过于频繁的数据库操作。
查询优先的表应该尽可能为where和order by字句中的字段加上索引,数据库更新插入优先的应用索引越少越好。
总之:对于任何数据库单表记录超过100万条优化都是比较困难的,关键是要把应用能够转化成数据库比较擅长的数据上限内。也就是把复杂需求简化成比较成熟的解决方案内。
一次优化实战
以下例子是对一个论坛应用进行的优化:
用Webalizer代替了原来的通过数据库的统计。
首先通过TOP命令查看MySQL服务的CPU占用左右80%和内存占用:10M,说明数据库的索引缓存已经用完了,修改启动参数,增加了-O key_buffer=32M,过一段时间等数据库稳定后看的内存占用是否达到上限。最后将缓存一直增加到64M,数据库缓存才基本能充分使用。对于一个数据库应用来说,把内存给数据库比给WEB服务实用的多,因为MySQL查询速度的提高能加快web应用从而节省并发的WEB服务所占用的内存资源。
用show processlist;统计经常出现的SQL:
每分钟运行一次show processlist并记录日志:
* * * * * (/home/mysql/bin/mysql -uuser -ppassword > /home/chedong/mysql_processlist.log)
show_processlist.sql里就一句:
show processlist;
比如可以从日志中将包含where的字句过滤出来:
grep where mysql_processlist.log
如果发现有死锁,一定要重新审视一下数据库设计了,对于一般情况:查询速度很慢,就将SQL where字句中没有索引的字段加上索引,如果是排序慢就将order by字句中没有索引的字段加上。对于有%like%的查询,考虑以后禁用和使用全文索引加速。
还是根据show processlist;看经常有那些数据库被频繁使用,考虑将数据库拆分到其他服务端口上。
MSSQL到MySQL的数据迁移:ACCESS+MySQL ODBC Driver
在以前的几次数据迁移实践过程中,我发现最简便的数据迁移过程并不是通过专业的数据库迁移工具,也不是MSSQL自身的DTS进行数据迁移(迁移过程中间会有很多表出错误警告),但通过将MSSQL数据库通过ACCESS获取外部数据导入到数据库中,然后用ACCESS的表==>右键==>导出,制定ODBC,通过MySQL的DSN将数据导出。这样迁移大部分数据都会非常顺利,如果导出的表有索引问题,还会出添加索引提示(DTS就不行),然后剩余的工作就是在MySQL中设计字段对应的SQL脚本了。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 How to fix 'Service is not responding' error in Windows.
Apr 27, 2023 am 08:16 AM
How to fix 'Service is not responding' error in Windows.
Apr 27, 2023 am 08:16 AM
The NETSTART command is a built-in command in Windows that can be used to start and stop services and other programs. Sometimes, you may encounter NetHelpmsg2186 error while running this command. Most users who encounter this error try to restart the Windows Update service by running the NETSTARTWUAUSERV command. If the Windows Update service is disabled or not running, your system may be at risk as you will not be able to get the latest updates. Let’s explore in detail why this error occurs and how to bypass it. Okay? What is error 2186? Windows Update service installs the latest critical updates and security features
 Solution to Windows 10 Security Center service being disabled
Jul 16, 2023 pm 01:17 PM
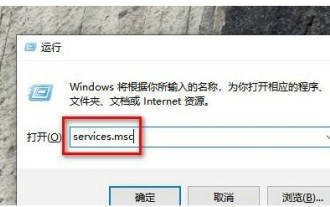
Solution to Windows 10 Security Center service being disabled
Jul 16, 2023 pm 01:17 PM
The Security Center service is a built-in computer protection function in the win10 system, which can protect computer security in real time. However, some users encounter a situation where the Security Center service is disabled when booting the computer. What should they do? It's very simple. You can open the service panel, find the SecurityCenter item, then right-click to open its properties window, set the startup type to automatic, and then click Start to start the service again. What to do if the Win10 Security Center service is disabled: 1. Press "Win+R" to open the "Operation" window. 2. Then enter the "services.msc" command and press Enter. 3. Then find the "SecurityCenter" item in the right window and double-click it to open its properties window.
 How to open Remote Desktop Connection Service using command
Dec 31, 2023 am 10:38 AM
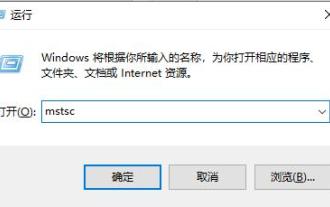
How to open Remote Desktop Connection Service using command
Dec 31, 2023 am 10:38 AM
Remote desktop connection has brought convenience to many users' daily lives. Some people want to use commands to connect remotely, which is more convenient to operate. So how to connect? Remote Desktop Connection Service can help you solve this problem by using a command to open it. How to set up the remote desktop connection command: Method 1. Connect remotely by running the command 1. Press "Win+R" to open "Run" and enter mstsc2, then click "Show Options" 3. Enter the IP address and click "Connect". 4. It will show that it is connecting. Method 2: Connect remotely through the command prompt 1. Press "Win+R" to open "Run" and enter cmd2. In the "Command Prompt" enter mstsc/v:192.168.1.250/console
 How to enable audio service in win7
Jul 10, 2023 pm 05:13 PM
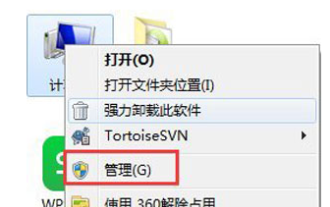
How to enable audio service in win7
Jul 10, 2023 pm 05:13 PM
Computers have many system services to support the application of various programs. If the computer has no sound and most audio services are not turned on after troubleshooting hardware problems, how do you enable audio services in win7? Many friends are confused, so for the question of how to enable the audio service in win7, the editor below will introduce how to enable the audio service in win7. How to enable audio service in win7. 1. Find the computer on the computer desktop under Windows 7 system, right-click and select the management option. 2. Find and open the service item under Services and Applications in the computer management interface that opens. Find WindowsAudio on the service interface on the right and double-click to open the modification. 4. Switch to the regular project and click Start to enable the function.
 What is the correct way to restart a service in Linux?
Mar 15, 2024 am 09:09 AM
What is the correct way to restart a service in Linux?
Mar 15, 2024 am 09:09 AM
What is the correct way to restart a service in Linux? When using a Linux system, we often encounter situations where we need to restart a certain service, but sometimes we may encounter some problems when restarting the service, such as the service not actually stopping or starting. Therefore, it is very important to master the correct way to restart services. In Linux, you can usually use the systemctl command to manage system services. The systemctl command is part of the systemd system manager
 Verification codes can't stop robots! Google AI can accurately identify blurry text, while GPT-4 pretends to be blind and asks for help
Apr 12, 2023 am 09:46 AM
Verification codes can't stop robots! Google AI can accurately identify blurry text, while GPT-4 pretends to be blind and asks for help
Apr 12, 2023 am 09:46 AM
“The most annoying thing is all kinds of weird (or even perverted) verification codes when you log into a website.” Now, there is good news and bad news. The good news is: AI can do this for you. If you don’t believe me, here are three real cases of increasing recognition difficulty: And these are the answers given by a model called “Pix2Struct”: Are they all accurate and word for word? Some netizens lamented: Sure, the accuracy is better than mine. So can it be made into a browser plug-in? ? Yes, some people said: Even though these cases are relatively simple, if you just fine-tune it, I can't imagine how powerful the effect will be. So, the bad news is - the verification code will soon be unable to stop the robots! (Danger danger danger...) How to do it? Pix2St
 Solution to Ubuntu PHP service failing to start normally
Feb 28, 2024 am 10:48 AM
Solution to Ubuntu PHP service failing to start normally
Feb 28, 2024 am 10:48 AM
Title: Methods and specific code examples to solve the problem that the PHP service cannot start normally under Ubuntu. When using Ubuntu to build a website or application, you often encounter the problem that the PHP service cannot start normally, which will cause the website to be unable to be accessed normally or the application to be unable to function normally. run. This article will introduce how to solve the problem that the PHP service cannot start normally under Ubuntu, and provide specific code examples to help readers quickly solve such failures. 1. Check the PHP configuration file First, we need to check the PHP configuration file
 How to execute service restart command in Linux?
Mar 14, 2024 am 11:06 AM
How to execute service restart command in Linux?
Mar 14, 2024 am 11:06 AM
In Linux, to execute the service restart command, you usually need to use the Systemd service manager. Systemd is a widely used service management tool on Linux, which can easily manage and control system services. The following will introduce how to execute the service restart command through Systemd in Linux and provide specific code examples. Step 1: Confirm the service name. Before executing the service restart command, you first need to confirm the name of the service to be restarted. You can view the list of services running on the system with the following command:
