
 Technology peripherals
AI
Depth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving
Technology peripherals
AI
Depth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving
Depth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving

Written before & personal understanding
Multi-view depth estimation has achieved high performance in various benchmark tests. However, almost all current multi-view systems rely on a given ideal camera pose, which is unavailable in many real-world scenarios, such as autonomous driving. This work proposes a new robustness benchmark to evaluate depth estimation systems under various noisy pose settings. Surprisingly, it is found that current multi-view depth estimation methods or single-view and multi-view fusion methods fail when given noisy pose settings. To address this challenge, here we propose AFNet, a single-view and multi-view fused depth estimation system that adaptively integrates high-confidence multi-view and single-view results to achieve robust and accurate depth estimation. The adaptive fusion module performs fusion by dynamically selecting high-confidence regions between the two branches based on the parcel confidence map. Therefore, when faced with textureless scenes, inaccurate calibration, dynamic objects, and other degraded or challenging conditions, the system tends to choose the more reliable branch. Under robustness tests, the method outperforms state-of-the-art multi-view and fusion methods. Additionally, state-of-the-art performance is achieved on challenging benchmarks (KITTI and DDAD).
Paper link: https://arxiv.org/pdf/2403.07535.pdf
Paper name: Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
Field Background
Image depth estimation has always been a challenge in the field of computer vision and has a wide range of applications. For vision-based autonomous driving systems, depth perception is key, helping to understand objects on the road and build 3D maps of the environment. With the application of deep neural networks in various visual problems, methods based on convolutional neural networks (CNN) have become the mainstream of depth estimation tasks.
According to the input format, it is mainly divided into multi-view depth estimation and single-view depth estimation. The assumption behind multi-view methods for estimating depth is that, given correct depth, camera calibration, and camera pose, pixels across views should be similar. They rely on epipolar geometry to triangulate high-quality depth measurements. However, the accuracy and robustness of multi-view methods strongly depend on the geometric configuration of the camera and the corresponding matching between views. First, the camera needs to translate enough to allow for triangulation. In a self-driving scenario, the self-vehicle may stop at a traffic light or turn without moving forward, which can cause triangulation to fail. In addition, multi-view methods suffer from the problems of dynamic targets and textureless areas, which are prevalent in autonomous driving scenarios. Another issue is SLAM attitude optimization on moving vehicles. In existing SLAM methods, noise is inevitable, not to mention challenging and unavoidable situations. For example, a robot or self-driving car can be deployed for years without recalibration, resulting in noisy poses. In contrast, since single-view methods rely on semantic understanding of the scene and perspective projection cues, they are more robust to textureless regions, dynamic objects, and do not rely on camera pose. However, due to the ambiguity of scale, its performance still falls far behind multi-view methods. Here, we tend to consider whether the advantages of these two methods can be well combined for robust and accurate monocular video depth estimation in autonomous driving scenarios.
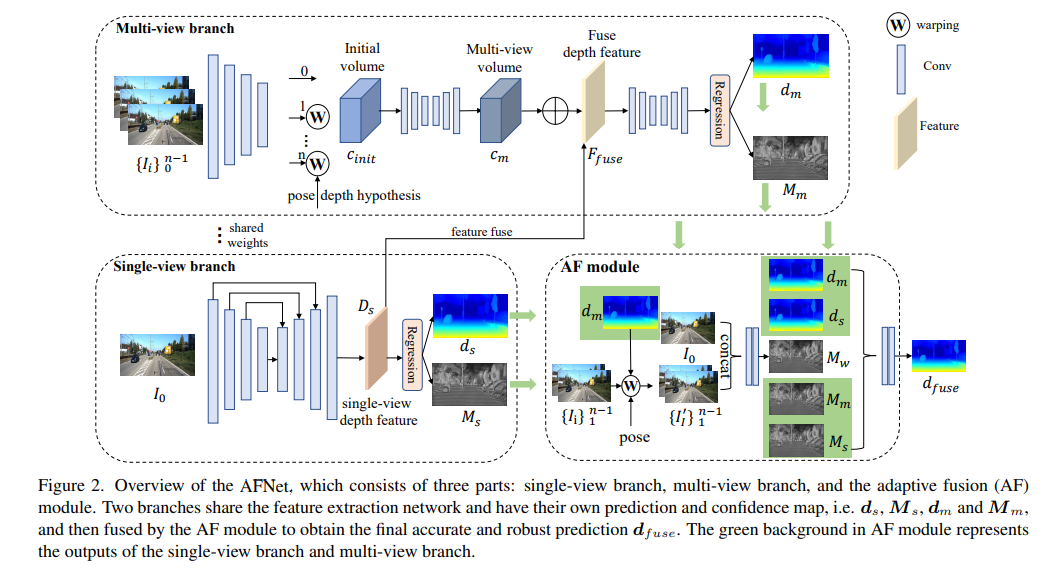
AFNet network structure
The AFNet structure is as follows. It consists of three parts: single-view branch, multi-view branch and adaptive fusion (AF) module. The two branches share the feature extraction network and have their own prediction and confidence maps, i.e., , , and , and are then fused by the AF module to obtain the final accurate and robust prediction. The green background in the AF module represents the single-view branch and The output of the multi-view branch.
Loss function:

Single view and multi-view depth module
In order to merge backbone features and obtain deep features Ds, AFNet builds a multi-scale decoder. In this process, a softmax operation is performed on the first 256 channels of Ds to obtain the depth probability volume Ps. The last channel in the depth feature is used as the single-view depth confidence map Ms. Finally, the single-view depth is calculated through soft weighting.
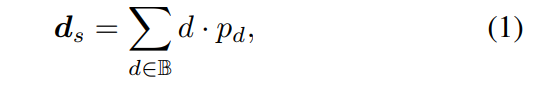
Multi-view branch
The multi-view branch shares the backbone with the single-view branch to extract features of the reference image and the source image. We adopt deconvolution to deconvolve the low-resolution features to quarter-resolution and combine them with the initial quarter-features used to construct the cost volume. A feature volume is formed by wrapping the source features into a hypothetical plane followed by the reference camera. For robust matching that does not require too much information, the channel dimension of the feature is retained in the calculation and a 4D cost volume is constructed, and then the number of channels is reduced to 1 through two 3D convolutional layers.
The sampling method of the depth hypothesis is consistent with the single-view branch, but the number of samples is only 128, and then a stacked 2D hourglass network is used for regularization to obtain the final multi-view cost volume. In order to supplement the rich semantic information of single-view features and the details lost due to cost regularization, a residual structure is used to combine single-view depth features Ds and cost volume to obtain fused depth features, as follows:
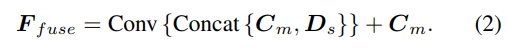
Adaptive fusion module
In order to obtain the final accurate and robust prediction, the AF module is designed to adaptively select the best value between the two branches. The accurate depth is used as the final output, as shown in Figure 2. Fusion mapping is performed through three confidences, two of which are the confidence maps Ms and Mm generated by the two branches respectively. The most critical one is the confidence map Mw generated by forward wrapping to determine whether the prediction of the multi-view branch is reliable. .
Experimental Results
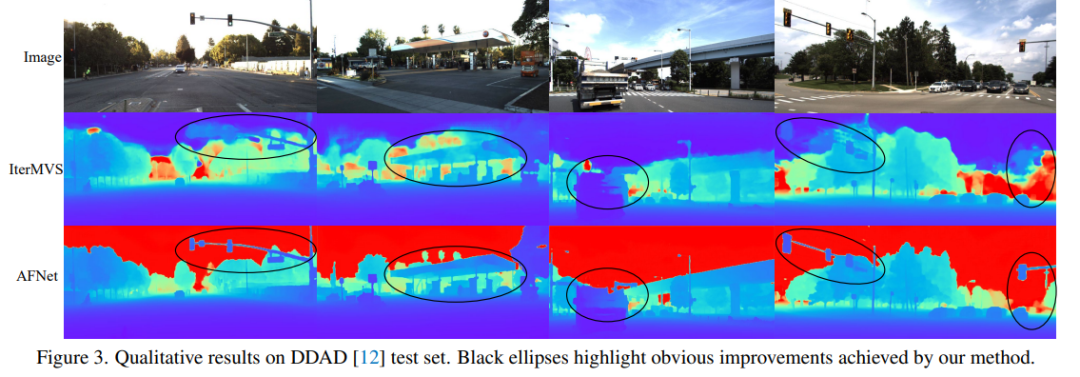
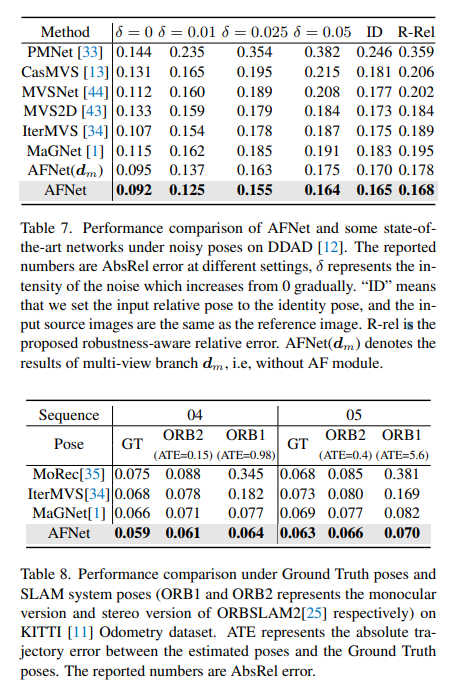
DDAD (Dense Depth for Autonomous Driving) is a new autonomous driving benchmark for dense depth in challenging and diverse urban conditions estimate. It is captured by 6 synchronized cameras and contains accurate ground depth (entire 360-degree field of view) generated by high-density lidar. It has 12650 training samples and 3950 validation samples in a single camera view with a resolution of 1936×1216. All data from 6 cameras are used for training and testing. The KITTI data set provides stereoscopic images of outdoor scenes shot on moving vehicles and corresponding 3D laser scans, with a resolution of approximately 1241×376.
Comparison of evaluation results on DDAD and KITTI. Note that * marks results replicated using their open source code, other reported numbers are from the corresponding original papers.
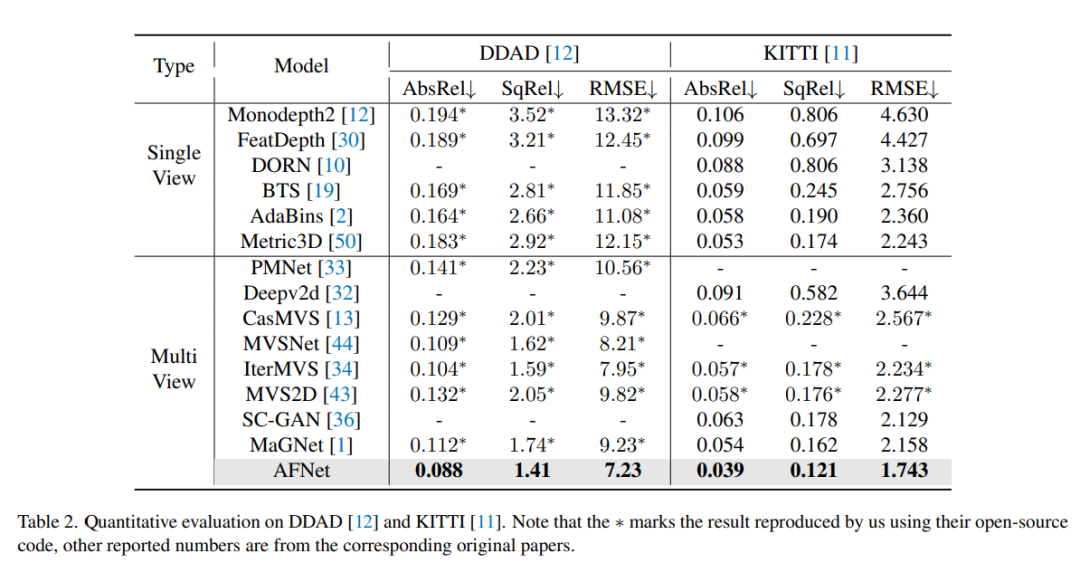
Ablation experimental results for each strategy in the method on DDAD. Single represents the result of single-view branch prediction, Multi- represents the result of multi-view branch prediction, and Fuse represents the fusion result dfuse.
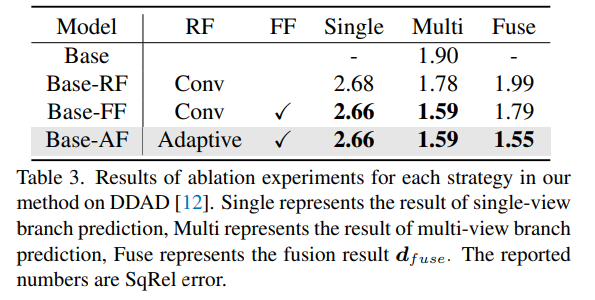
#A method to share network parameters and extract matching information for feature extraction of ablation results.
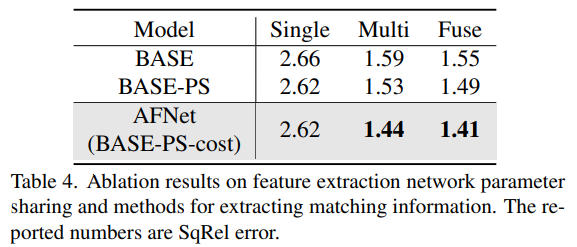
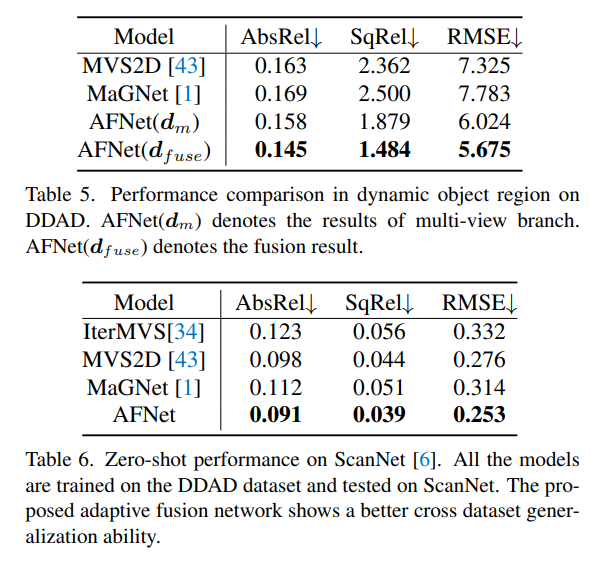

The above is the detailed content of Depth estimation SOTA! Adaptive fusion of monocular and surround depth for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1421
52
1315
25
1266
29
1239
24
14
1421
52
1315
25
1266
29
1239
24

 CUDA's universal matrix multiplication: from entry to proficiency!
Mar 25, 2024 pm 12:30 PM
CUDA's universal matrix multiplication: from entry to proficiency!
Mar 25, 2024 pm 12:30 PM
General Matrix Multiplication (GEMM) is a vital part of many applications and algorithms, and is also one of the important indicators for evaluating computer hardware performance. In-depth research and optimization of the implementation of GEMM can help us better understand high-performance computing and the relationship between software and hardware systems. In computer science, effective optimization of GEMM can increase computing speed and save resources, which is crucial to improving the overall performance of a computer system. An in-depth understanding of the working principle and optimization method of GEMM will help us better utilize the potential of modern computing hardware and provide more efficient solutions for various complex computing tasks. By optimizing the performance of GEMM
 Huawei's Qiankun ADS3.0 intelligent driving system will be launched in August and will be launched on Xiangjie S9 for the first time
Jul 30, 2024 pm 02:17 PM
Huawei's Qiankun ADS3.0 intelligent driving system will be launched in August and will be launched on Xiangjie S9 for the first time
Jul 30, 2024 pm 02:17 PM
On July 29, at the roll-off ceremony of AITO Wenjie's 400,000th new car, Yu Chengdong, Huawei's Managing Director, Chairman of Terminal BG, and Chairman of Smart Car Solutions BU, attended and delivered a speech and announced that Wenjie series models will be launched this year In August, Huawei Qiankun ADS 3.0 version was launched, and it is planned to successively push upgrades from August to September. The Xiangjie S9, which will be released on August 6, will debut Huawei’s ADS3.0 intelligent driving system. With the assistance of lidar, Huawei Qiankun ADS3.0 version will greatly improve its intelligent driving capabilities, have end-to-end integrated capabilities, and adopt a new end-to-end architecture of GOD (general obstacle identification)/PDP (predictive decision-making and control) , providing the NCA function of smart driving from parking space to parking space, and upgrading CAS3.0
 Always new! Huawei Mate60 series upgrades to HarmonyOS 4.2: AI cloud enhancement, Xiaoyi Dialect is so easy to use
Jun 02, 2024 pm 02:58 PM
Always new! Huawei Mate60 series upgrades to HarmonyOS 4.2: AI cloud enhancement, Xiaoyi Dialect is so easy to use
Jun 02, 2024 pm 02:58 PM
On April 11, Huawei officially announced the HarmonyOS 4.2 100-machine upgrade plan for the first time. This time, more than 180 devices will participate in the upgrade, covering mobile phones, tablets, watches, headphones, smart screens and other devices. In the past month, with the steady progress of the HarmonyOS4.2 100-machine upgrade plan, many popular models including Huawei Pocket2, Huawei MateX5 series, nova12 series, Huawei Pura series, etc. have also started to upgrade and adapt, which means that there will be More Huawei model users can enjoy the common and often new experience brought by HarmonyOS. Judging from user feedback, the experience of Huawei Mate60 series models has improved in all aspects after upgrading HarmonyOS4.2. Especially Huawei M
 Which version of Apple 16 system is the best?
Mar 08, 2024 pm 05:16 PM
Which version of Apple 16 system is the best?
Mar 08, 2024 pm 05:16 PM
The best version of the Apple 16 system is iOS16.1.4. The best version of the iOS16 system may vary from person to person. The additions and improvements in daily use experience have also been praised by many users. Which version of the Apple 16 system is the best? Answer: iOS16.1.4 The best version of the iOS 16 system may vary from person to person. According to public information, iOS16, launched in 2022, is considered a very stable and performant version, and users are quite satisfied with its overall experience. In addition, the addition of new features and improvements in daily use experience in iOS16 have also been well received by many users. Especially in terms of updated battery life, signal performance and heating control, user feedback has been relatively positive. However, considering iPhone14
 What are the computer operating systems?
Jan 12, 2024 pm 03:12 PM
What are the computer operating systems?
Jan 12, 2024 pm 03:12 PM
A computer operating system is a system used to manage computer hardware and software programs. It is also an operating system program developed based on all software systems. Different operating systems have different users. So what are the computer systems? Below, the editor will share with you what computer operating systems are. The so-called operating system is to manage computer hardware and software programs. All software is developed based on operating system programs. In fact, there are many types of operating systems, including those for industrial use, commercial use, and personal use, covering a wide range of applications. Below, the editor will explain to you what computer operating systems are. What computer operating systems are Windows systems? The Windows system is an operating system developed by Microsoft Corporation of the United States. than the most
 Differences and similarities of cmd commands in Linux and Windows systems
Mar 15, 2024 am 08:12 AM
Differences and similarities of cmd commands in Linux and Windows systems
Mar 15, 2024 am 08:12 AM
Linux and Windows are two common operating systems, representing the open source Linux system and the commercial Windows system respectively. In both operating systems, there is a command line interface for users to interact with the operating system. In Linux systems, users use the Shell command line, while in Windows systems, users use the cmd command line. The Shell command line in Linux system is a very powerful tool that can complete almost all system management tasks.
 Detailed explanation of how to modify system date in Oracle database
Mar 09, 2024 am 10:21 AM
Detailed explanation of how to modify system date in Oracle database
Mar 09, 2024 am 10:21 AM
Detailed explanation of the method of modifying the system date in the Oracle database. In the Oracle database, the method of modifying the system date mainly involves modifying the NLS_DATE_FORMAT parameter and using the SYSDATE function. This article will introduce these two methods and their specific code examples in detail to help readers better understand and master the operation of modifying the system date in the Oracle database. 1. Modify NLS_DATE_FORMAT parameter method NLS_DATE_FORMAT is Oracle data
 Where is the system font storage path?
Feb 19, 2024 pm 09:11 PM
Where is the system font storage path?
Feb 19, 2024 pm 09:11 PM
In which folder are the system fonts located? In modern computer systems, fonts play a vital role, affecting our reading experience and the beauty of text expression. For some users who are keen on personalization and customization, it is particularly important to understand the storage location of system fonts. So, in which folder are system fonts stored? This article will reveal them one by one for everyone. In the Windows operating system, system fonts are stored in a folder called "Fonts". This folder is located in the Win C drive by default.
