
 Technology peripherals
AI
Is the 3D version of Sora coming? UMass, MIT and others propose 3D world models, and embodied intelligent robots achieve new milestones
Technology peripherals
AI
Is the 3D version of Sora coming? UMass, MIT and others propose 3D world models, and embodied intelligent robots achieve new milestones
Is the 3D version of Sora coming? UMass, MIT and others propose 3D world models, and embodied intelligent robots achieve new milestones

In recent research, the input to the vision-language-action (VLA, vision-language-action) model It is basically 2D data and does not integrate the more general 3D physical world.
In addition, existing models perform action prediction by learning "direct mapping of perceived actions", ignoring the dynamics of the world and the relationship between actions and dynamics.
In contrast, when humans think, they introduce world models, which can describe their imagination of future scenarios and plan their next actions.
To this end, researchers from the University of Massachusetts Amherst, MIT and other institutions have proposed the 3D-VLA model. By introducing a new class of embodied foundation models, the generated world can be Models seamlessly connect 3D perception, reasoning and action. 
Project homepage: https://vis-www.cs.umass .edu/3dvla/
Paper address: https://arxiv.org/abs/2403.09631
Specifically, 3D-VLA Built on a 3D-based large language model (LLM) and introducing a set of interaction tokens to participate in embodied environments.
The Ganchuang team trained a series of embodied diffusion models, injecting generative capabilities into the models and aligning them into LLM to predict target images and point clouds.
In order to train the 3D-VLA model, we extracted a large amount of 3D related information from existing robot datasets and constructed a huge 3D embodied instruction dataset.
The research results show that 3D-VLA performs well in handling reasoning, multi-modal generation and planning tasks in embodied environments, which highlights its potential application in real-world scenarios value.
3D Embodied Instruction Tuning Dataset
Due to the billions of data sets on the Internet, VLM performs in multiple tasks It delivers excellent performance, and the million-level video action data set also lays the foundation for specific VLM for robot control.
However, most of the current datasets cannot provide sufficient depth or 3D annotation and precise control for robot operation. This requires the content of 3D spatial reasoning and interaction to be included in the data set. The lack of 3D information makes it difficult for robots to understand and execute instructions that require 3D spatial reasoning, such as "Put the farthest cup in the middle drawer."

To bridge this gap, the researchers constructed a large-scale 3D instruction tuning data set, which provides sufficient "3D related information" and "corresponding text instructions" to train the model.
The researchers designed a pipeline to extract 3D language action pairs from existing embodied datasets, obtaining point clouds, depth maps, 3D bounding boxes, 7D actions of the robot, and text descriptions label.
3D-VLA base model
3D-VLA is a world model for three-dimensional reasoning, goal generation and decision-making in an embodied environment .
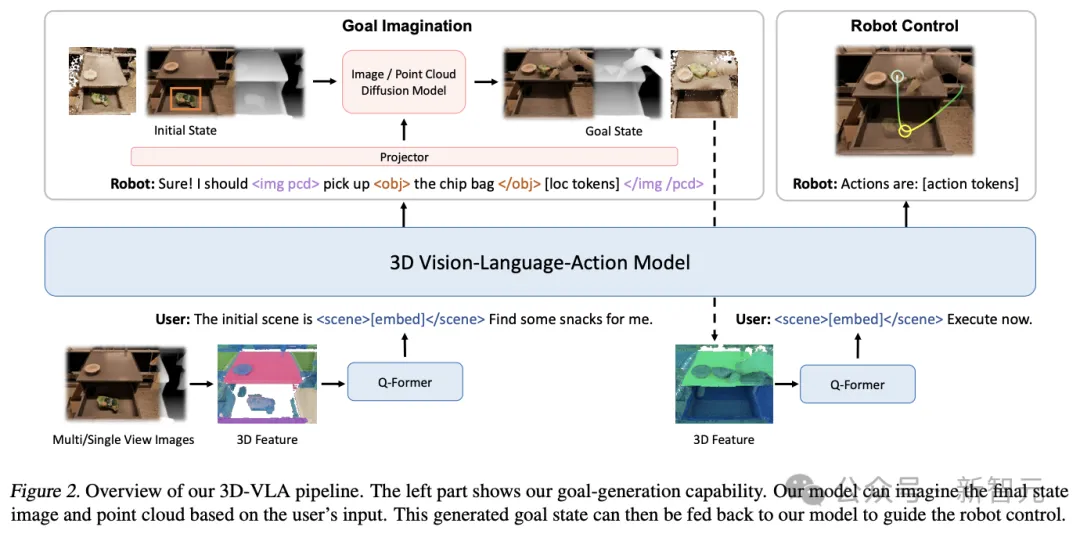
First build the backbone network on top of 3D-LLM, and further enhance the model's ability to interact with the 3D world by adding a series of interactive tokens; Then by pre-training the diffusion model and using projection to align the LLM and diffusion models, the target generation capability is injected into the 3D-VLA
backbone network
In the first stage, the researchers developed the 3D-VLA base model following the 3D-LLM method: since the collected data set did not reach the billion-level scale required to train multi-modal LLM from scratch, Multi-view features need to be used to generate 3D scene features so that visual features can be seamlessly integrated into pre-trained VLM without adaptation.
At the same time, the training data set of 3D-LLM mainly includes objects and indoor scenes, which are not directly consistent with the specific settings, so the researchers chose to use BLIP2-PlanT5XL as the pre-training model .
During the training process, unfreeze the input and output embeddings of the token, and the weights of the Q-Former.
Interaction tokens
In order to enhance the model’s understanding of the 3D scene and the interaction in the environment, the researchers introduced A new set of interactive tokens
First, object tokens are added to the input, including object nouns in parsed sentences (such as
Secondly, in order to better express spatial information in language, the researchers designed a set of location tokens
Third, in order to better perform dynamic encoding,
The architecture is further enhanced by extending the set of specialized tags that represent robot actions. The robot's action has 7 degrees of freedom. Discrete tokens such as
Inject goal generation capabilities
Humans can pre-visualize the final state of the scene, Improving the accuracy of action prediction or decision-making is also a key aspect of building a world model; in preliminary experiments, the researchers also found that providing a realistic final state can enhance the model's reasoning and planning capabilities.
But training MLLM to generate images, depth and point clouds is not simple:
First, video diffusion models are not designed for embodied scenes Tailor-made, for example, when Runway generates future frames of "open drawer", problems such as view changes, object deformation, weird texture replacement, and layout distortion will occur in the scene.
Moreover, how to integrate diffusion models of various modes into a single basic model is still a difficult problem.
So the new framework proposed by the researchers first pre-trains the specific diffusion model based on different forms such as images, depth and point clouds, and then uses the decoder of the diffusion model in the alignment stage. Aligned to the embedding space of 3D-VLA.

Experimental results
3D-VLA is a multifunctional, 3D-based generative world model that can be used in the 3D world In performing reasoning and localization, imagining multi-modal target content, and generating actions for robot operation, the researchers mainly evaluated 3D-VLA from three aspects: 3D reasoning and localization, multi-modal target generation, and embodied action planning. .
3D Inference and Localization
3D-VLA outperforms all 2D VLM methods on language reasoning tasks, study Personnel attributed this to the leverage of 3D information, which provides more accurate spatial information for reasoning.
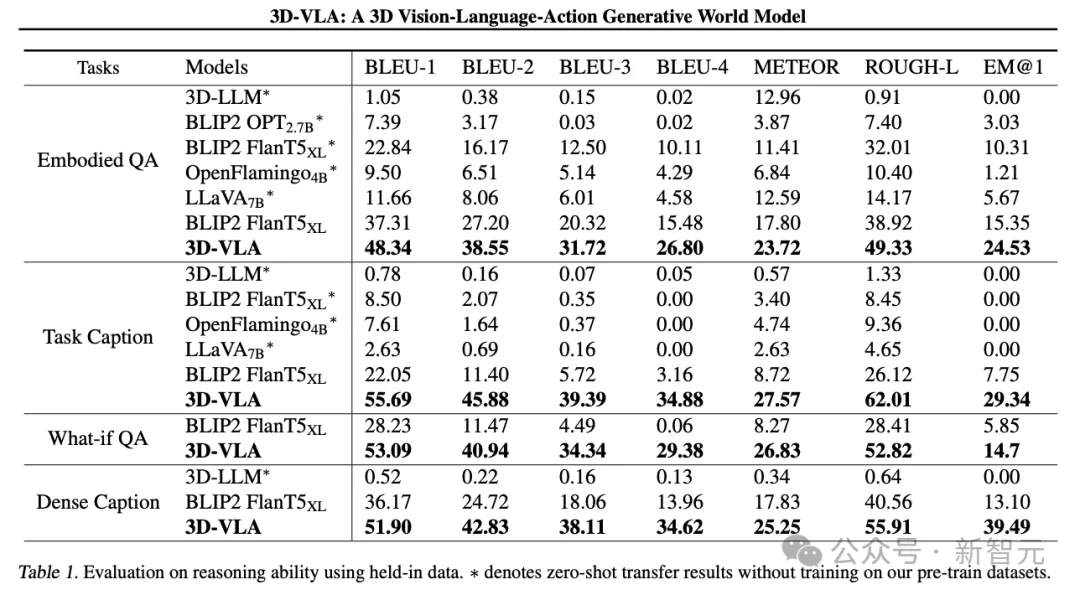
In addition, since the dataset contains a set of 3D positioning annotations, 3D-VLA learns to locate relevant objects, helping the model to focus more on key objects for reasoning.
The researchers found that 3D-LLM performed poorly on these robotic inference tasks, demonstrating the necessity of collecting and training on robotics-related 3D datasets.
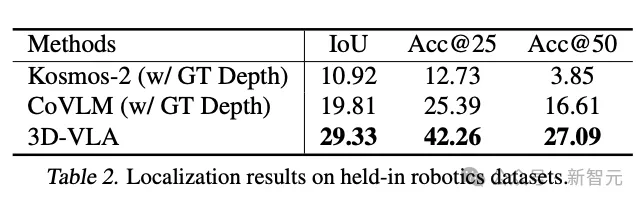
And 3D-VLA performed significantly better than the 2D baseline method in positioning performance. This finding also provides evidence for the effectiveness of the annotation process. Convincing evidence helps the model gain powerful 3D positioning capabilities.
Multi-modal target generation
Compared with existing zero-shot generation methods for migration to the robotics field, 3D-VLA achieves better results in most metrics. The good performance confirms the importance of using "datasets specifically designed for robotic applications" to train world models.
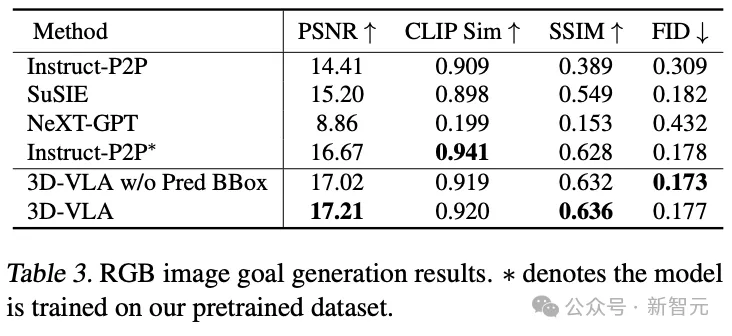
Even in direct comparisons with Instruct-P2P*, 3D-VLA consistently performs better, and the results show that integrating large language models In 3D-VLA, robot operation instructions can be understood more comprehensively and deeply, thereby improving the target image generation performance.
Additionally, a slight performance degradation can be observed when excluding predicted bounding boxes from the input prompt, confirming the effectiveness of using intermediate predicted bounding boxes to aid model understanding The entire scene allows the model to allocate more attention to the specific objects mentioned in a given instruction, ultimately enhancing its ability to imagine the final target image.
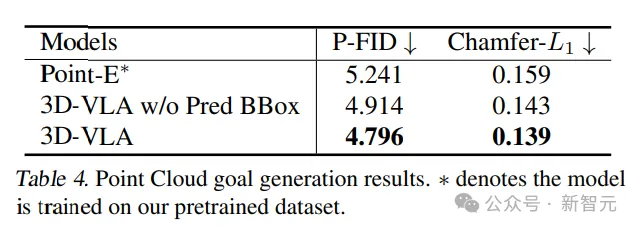
In the comparison of results generated by point clouds, 3D-VLA with intermediate predicted bounding boxes performs best, confirming the importance of understanding instructions and scenes. Contextualize the importance of combining large language models with precise object localization.
Embodied Action Planning
3D-VLA exceeds the baseline in most tasks in RLBench action prediction The performance of the model shows its planning capabilities.
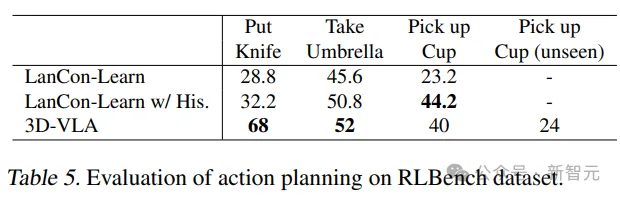
It is worth noting that the baseline model requires the use of historical observations, object status and current status information, while the 3D-VLA model only executes through open-loop control.
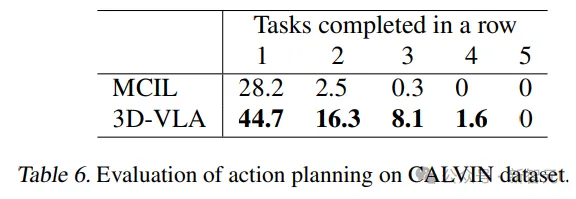
In addition, the generalization ability of the model was demonstrated in the pick-up-cup task, and 3D-VLA was used in CALVIN Better results were also achieved, an advantage the researchers attributed to the ability to locate objects of interest and imagine goal states, providing rich information for inferring actions.
The above is the detailed content of Is the 3D version of Sora coming? UMass, MIT and others propose 3D world models, and embodied intelligent robots achieve new milestones. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Binance is the overlord of the global digital asset trading ecosystem, and its characteristics include: 1. The average daily trading volume exceeds $150 billion, supports 500 trading pairs, covering 98% of mainstream currencies; 2. The innovation matrix covers the derivatives market, Web3 layout and education system; 3. The technical advantages are millisecond matching engines, with peak processing volumes of 1.4 million transactions per second; 4. Compliance progress holds 15-country licenses and establishes compliant entities in Europe and the United States.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
The platforms that have outstanding performance in leveraged trading, security and user experience in 2025 are: 1. OKX, suitable for high-frequency traders, providing up to 100 times leverage; 2. Binance, suitable for multi-currency traders around the world, providing 125 times high leverage; 3. Gate.io, suitable for professional derivatives players, providing 100 times leverage; 4. Bitget, suitable for novices and social traders, providing up to 100 times leverage; 5. Kraken, suitable for steady investors, providing 5 times leverage; 6. Bybit, suitable for altcoin explorers, providing 20 times leverage; 7. KuCoin, suitable for low-cost traders, providing 10 times leverage; 8. Bitfinex, suitable for senior play
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
