

Training large language models (llm) is a computationally intensive task, even those with "only" 7 billion parameters. This level of training requires resources beyond the capabilities of most individual enthusiasts. To bridge this gap, parameter-efficient methods such as low-rank adaptation (LoRA) have emerged, allowing fine-tuning of a large number of models on consumer-grade GPUs.
GaLore is an innovative method that uses optimized parameter training to reduce VRAM requirements rather than simply reducing the number of parameters. This means that GaLore is a new model training strategy that allows the model to fully utilize all parameters for learning and save memory more efficiently than LoRA.
GaLore effectively reduces the computational burden by mapping these gradients into a low-dimensional space while retaining key training information. Unlike traditional optimizers that update all layers at once during backpropagation, GaLore uses a layer-by-layer update method for backpropagation. This strategy significantly reduces the memory footprint during training and further optimizes performance.
Just like LoRA, GaLore allows us to fine-tune 7B models on consumer-grade GPUs equipped with up to 24 GB of VRAM. The results show that the model's performance is comparable to full-parameter fine-tuning and even seems to be better than LoRA.
Better than there is currently no official code for Hugging Face, so let’s manually use the paper’s code for training and compare it with LoRA
First we need to install GaLore
pip install galore-torch
Then we also need to check these libraries, and Please note that version
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
Galore hierarchical optimizer is Activated via model weight hooks. Since we use Hugging Face Trainer, we also need to implement an abstract class of optimizer and scheduler ourselves. The structures of these classes do not perform any operations.
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrsThe GaLore optimizer targets specific parameters, mainly those on the linear Parameters named attn or mlp in the layer. By systematically hooking functions to these target parameters, the GaLore 8-bit optimizer gets to work.
from transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()After preparing the optimizer, we start to use Trainer for training. Below is a simple example of fine-tuning llama2-7b on the Open Assistant dataset using TRL's SFTTrainer (a subclass of Trainer) and running on a 24 GB VRAM GPU such as RTX 3090/4090.
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,save_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "user", response_template = "assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()The GaLore optimizer has some hyperparameters that need to be set as follows:
target_modules_list: Specify the layer GaLore targets
rank: the rank of the projection matrix. Similar to LoRA, the higher the rank, the closer the fine-tuning is to full-parameter fine-tuning. The author of GaLore recommends 7B to use 1024
update_proj_gap: The number of steps to update the projection. This is an expensive step and takes about 15 minutes for 7B. Defines the interval for updating the projection, the recommended range is between 50 and 1000 steps.
scale: A scaling factor similar to LoRA's alpha, used to adjust the update intensity. After trying several values, I found that scale=2 is closest to classic full-parameter fine-tuning.
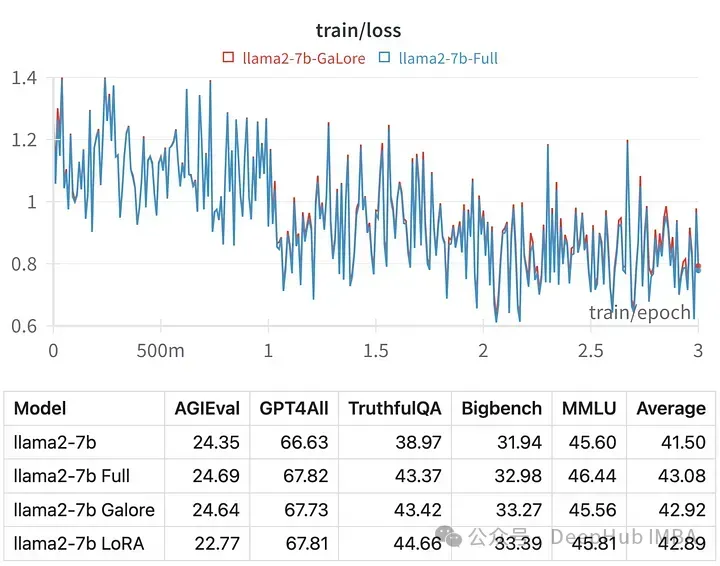
The training loss for a given hyperparameter is very similar to the trajectory of full-parameter tuning, indicating that the GaLore layered method is indeed are equivalent.
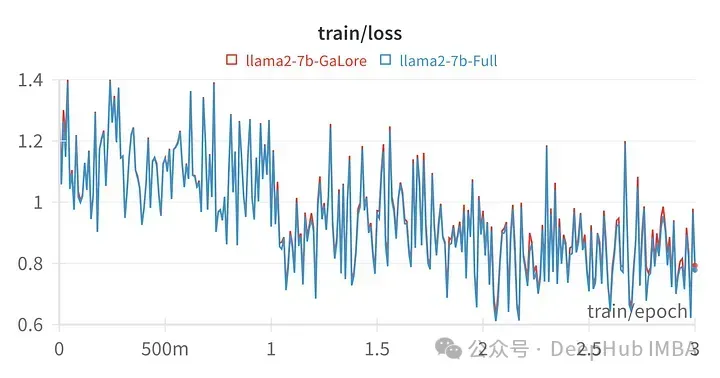
Model trained with GaLore scores very similar to full parameter fine-tuning.
GaLore can save about 15 GB of VRAM, but it takes longer to train due to regular projection updates.
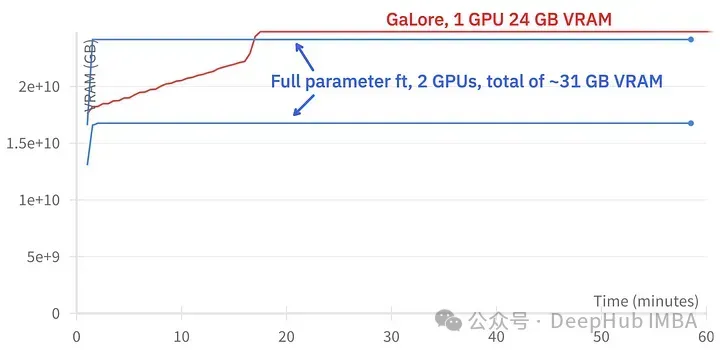
The picture above shows the memory usage comparison of two 3090
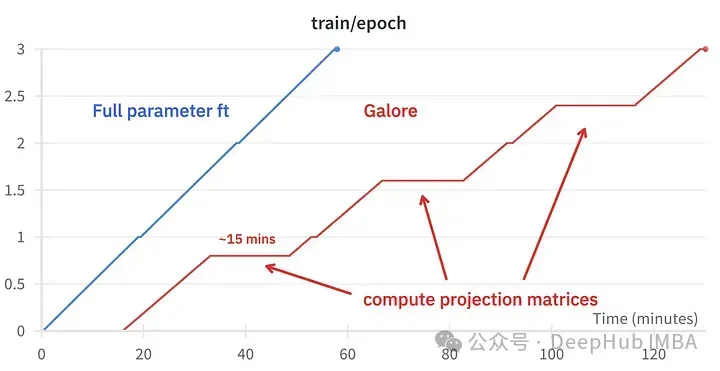
Training event comparison, fine-tuning: ~58 minutes. GaLore: About 130 minutes
Finally let’s take a look at the comparison between GaLore and LoRA
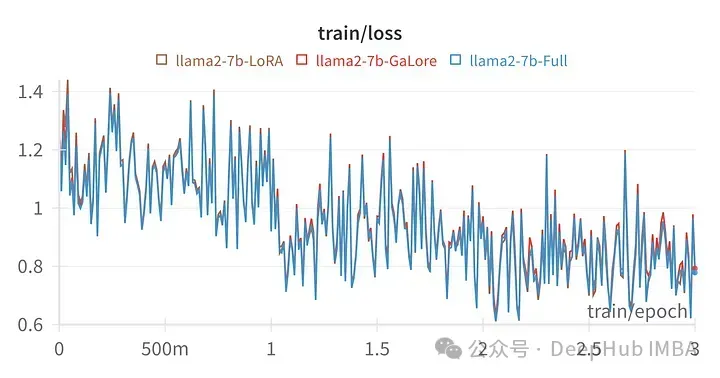
Above picture Fine-tuning all linear layers for LoRA, loss map of rank64, alpha 16
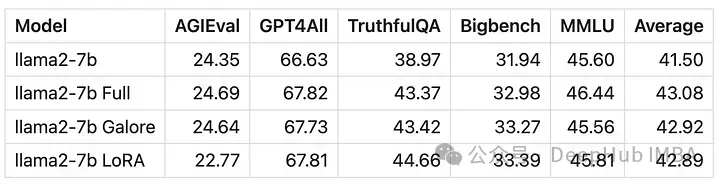
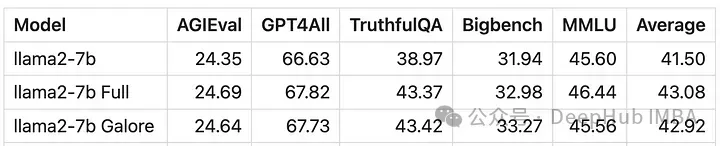
It can be seen numerically that GaLore is an approximate full-parameter training The performance of the new method is comparable to fine-tuning and much better than LoRA.
GaLore can save VRAM, allowing training of 7B models on consumer-grade GPUs, but is slower than fine-tuning and LoRA It takes almost twice as long.
The above is the detailed content of Efficient LLM tuning on local GPU using GaLore. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



