
 Technology peripherals
AI
Tsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars
Technology peripherals
AI
Tsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars
Tsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars

In natural language processing, a lot of information is actually repeated.
If the prompt words can be effectively compressed, it is equivalent to expanding the length of the context supported by the model to some extent.
Existing information entropy methods reduce this redundancy by removing certain words or phrases.
However, the calculation based on information entropy only covers the one-way context of the text and may ignore key information required for compression; moreover, the calculation method of information entropy is not fully consistent with the compression tips the actual purpose of the word.
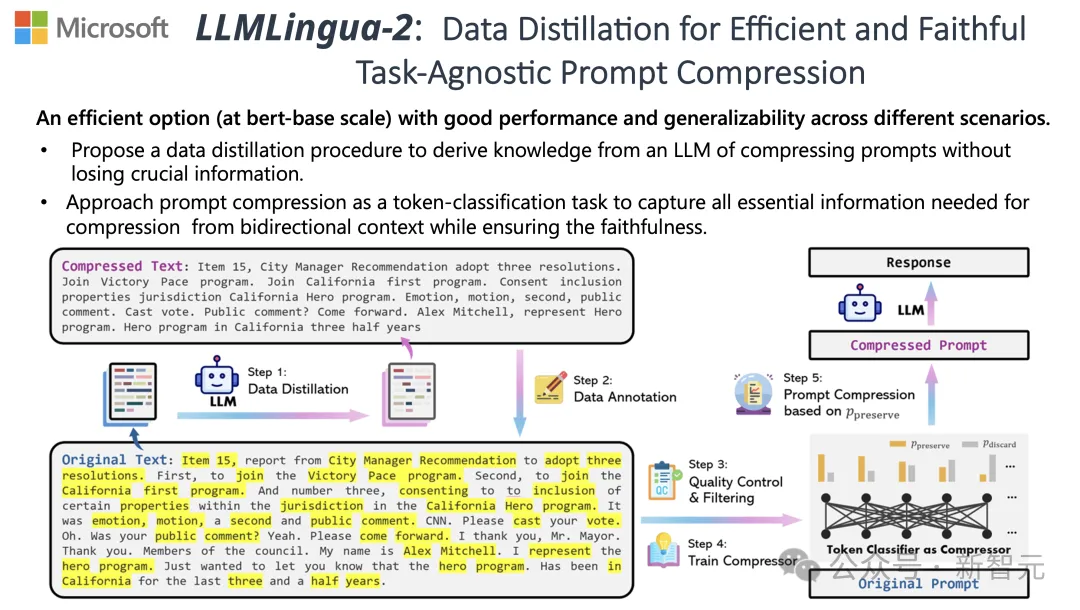
To meet these challenges, researchers from Tsinghua University and Microsoft jointly proposed a new data processing process called LLMLingua-2. It aims to extract knowledge from large language models (LLM) and achieve information refinement by compressing prompt words while ensuring that key information is not lost.
The project has gained 3.1k stars on GitHub
The results show that LLMLingua-2 can The text length is significantly reduced to the original 20%, effectively reducing processing time and costs.
In addition, LLMLingua 2’s processing speed is increased by 3 to 6 times compared to the previous version of LLMLingua and other similar technologies.

Paper address: https://arxiv.org/abs/2403.12968
In this process , raw text is first fed into the model.
The model will evaluate the importance of each word and decide whether to retain or delete it, while also taking into account the relationship between words.
Finally, the model will select those words with the highest scores to form a shorter prompt word.
The team tested the LLMLingua-2 model on multiple datasets including MeetingBank, LongBench, ZeroScrolls, GSM8K and BBH.
Although this model is small, it achieves significant performance improvements in benchmark tests and demonstrates its performance on different large language models (from GPT-3.5 to Mistral- 7B) Excellent generalization ability across languages (from English to Chinese).
System prompt:
As an outstanding linguist, you are good at converting long Condensing paragraphs of text into brief expressions by removing unimportant words while retaining as much information as possible.
User Tips:
Please compress the given text into A short expression that allows you (GPT-4) to restore the original text as accurately as possible. Different from regular text compression, I need you to follow the following five conditions:
1. Only remove unimportant words.
2. Keep the order of the original words unchanged.
3. Keep the original vocabulary unchanged.
4. Do not use any abbreviations or emoticons.
5. Do not add any new words or symbols.
Please compress the original text as much as possible while retaining as much information as possible. If you understand, please compress the following text: {Text to be compressed}
The compressed text is: [...]
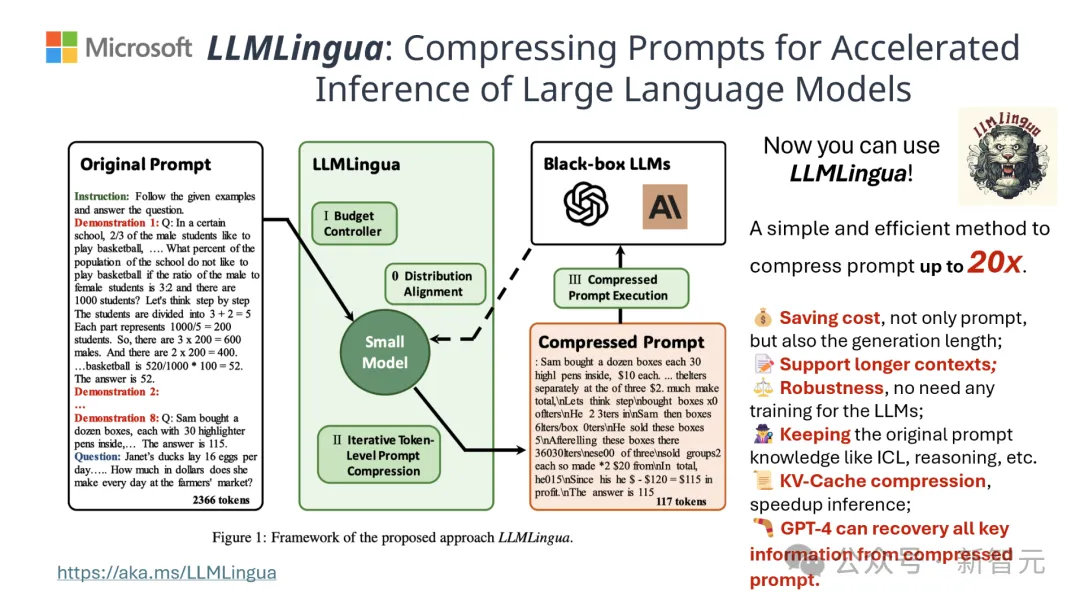
The results show that LLMLingua-2 significantly outperforms the original LLMLingua model and other selective context strategies in multiple language tasks such as question and answer, summary writing, and logical reasoning.
It is worth mentioning that this compression method is equally effective for different large language models (from GPT-3.5 to Mistral-7B) and different languages (from English to Chinese) .
Moreover, the deployment of LLMLingua-2 can be achieved with just two lines of code.
Currently, the model has been integrated into the widely used RAG frameworks LangChain and LlamaIndex.
Implementation method
In order to overcome the problems faced by existing information entropy-based text compression methods, LLMLingua-2 adopts an innovation data extraction strategy.
This strategy extracts essential information from large language models such as GPT-4, achieving efficient text editing without losing key content and avoiding adding erroneous information. compression.
Prompt Design
To fully utilize the text compression potential of GPT-4, the key lies in how to set the precise compression instructions.
That is, when compressing text, instruct GPT-4 to only remove those words that are not so important in the original text, while avoiding the introduction of any new words in the process.
The purpose of this is to ensure that the compressed text maintains the authenticity and integrity of the original text as much as possible.

##Annotation and filtering
The researchers used the GPT-4 Using the knowledge extracted from large language models, a novel data annotation algorithm was developed.
This algorithm can mark each word in the original text and clearly indicate which words must be retained during the compression process.
In order to ensure the high quality of the constructed data set, they also designed two quality monitoring mechanisms specifically to identify and exclude those data samples with poor quality.

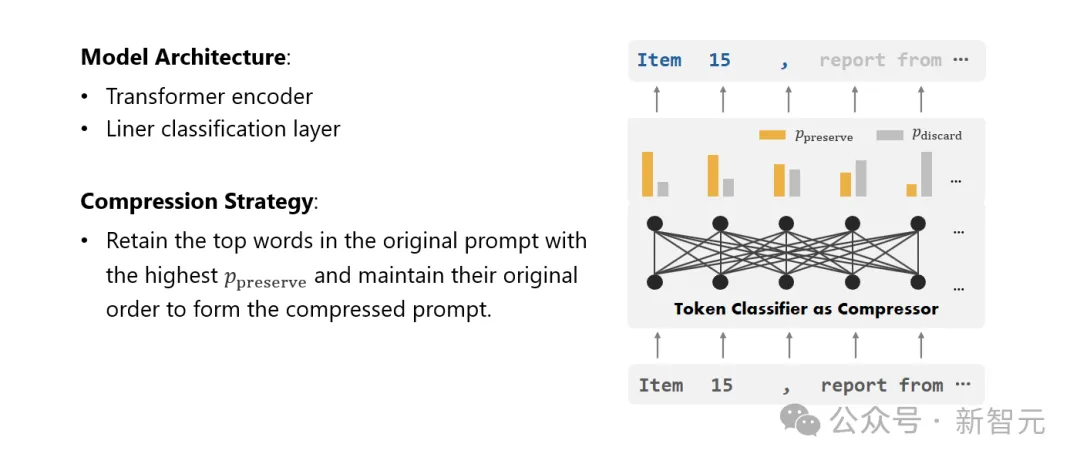
Compressor
Finally, the researchers solved the problem of text compression It is transformed into a task of classifying each word (Token), and a powerful Transformer is used as the feature extractor.
This tool can understand the context of text to accurately capture the information critical for text compression.
By training on a carefully constructed data set, the researchers' model is able to calculate a probability value to decide whether a word should be retained based on its importance. In the final compressed text, it should still be discarded.
Performance Evaluation
The researchers tested the performance of LLMLingua-2 on a range of tasks, These tasks include context learning, text summarization, dialogue generation, multi- and single-document question answering, code generation, and synthesis tasks, including both in-domain and out-of-domain datasets.
Test results show that the researchers’ method reduces minimal performance loss while maintaining high performance, and performs outstandingly among task-unspecific text compression methods.
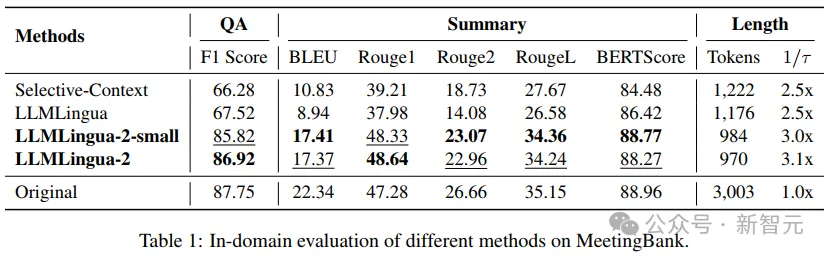
- In-domain test (MeetingBank)
The researchers compared the performance of LLMLingua-2 on the MeetingBank test set with Other powerful baseline methods are compared.
Although their model size is much smaller than the LLaMa-2-7B used in the baseline, the researchers' method not only significantly improved performance on question answering and text summarization tasks, but also was consistent with The original text prompts performed similarly.
##-Out-of-domain testing (LongBench, GSM8K and BBH)
Considering that the researchers’ model was only trained on MeetingBank’s meeting record data, the researchers further explored its generalization capabilities in different scenarios such as long text, logical reasoning, and contextual learning.
It is worth mentioning that although LLMLingua-2 was only trained on one dataset, in out-of-domain testing, its performance was not only comparable to the current state-of-the-art task-independent compression The methods are comparable, and in some cases even better.
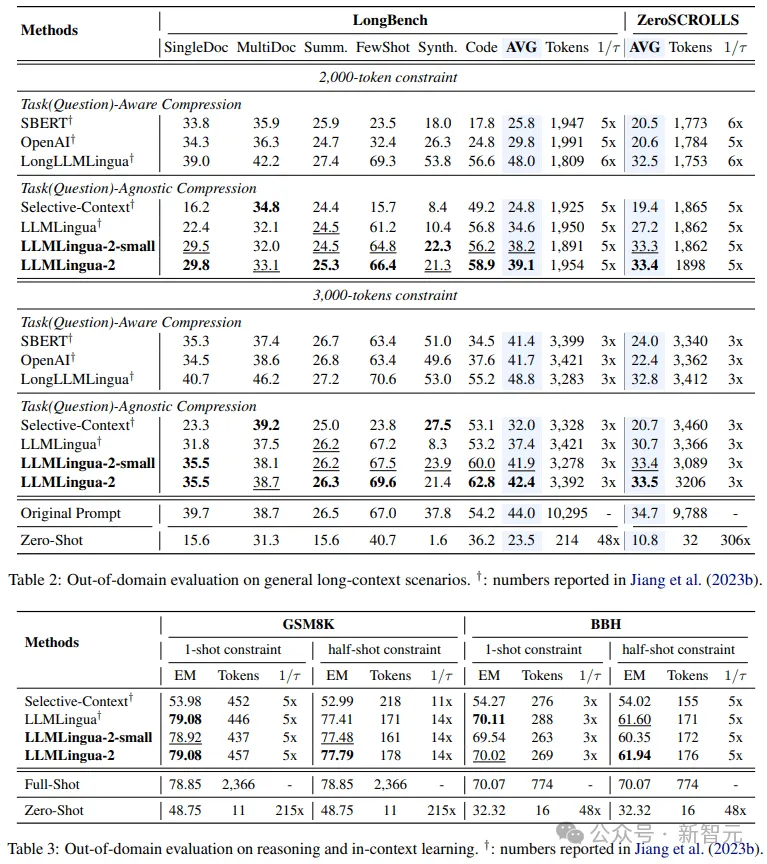
Even the researchers’ smaller model (BERT-base size) was able to achieve comparable performance to the original hint, in some cases Down or even slightly above the original tip.
While the researchers’ approach achieved promising results, it still has shortcomings when compared with other task-aware compression methods, such as LongLLMlingua on Longbench.
The researchers attribute this performance gap to the extra information they get from the questions. However, the researchers' model is task-agnostic, making it an efficient option with good generalizability when deployed in different scenarios.
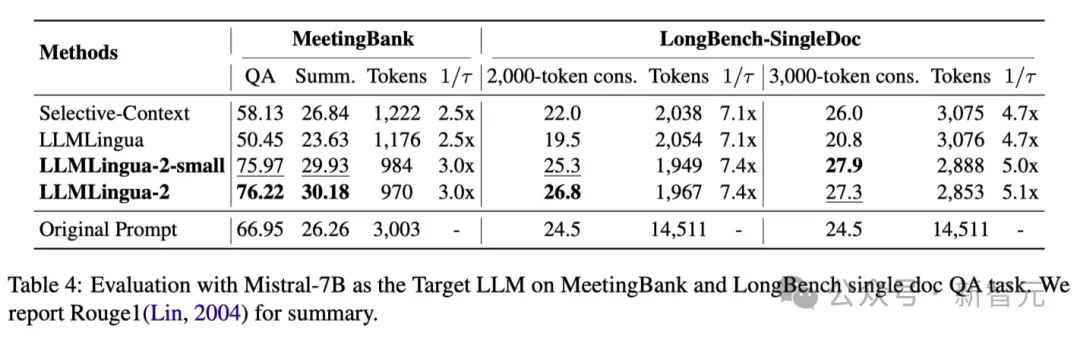
Table 4 above lists the results of different methods using Mistral-7Bv0.1 4 as the target LLM.
Compared with other baseline methods, the researchers' method has a significant improvement in performance, demonstrating its good generalization ability on the target LLM.
It is worth noting that LLMLingua-2 performs even better than the original prompt.
Researchers speculate that Mistral-7B may not be as good at managing long contexts as GPT-3.5-Turbo.
The researchers’ approach effectively improves Mistral7B’s final inference performance by providing short hints with higher information density.
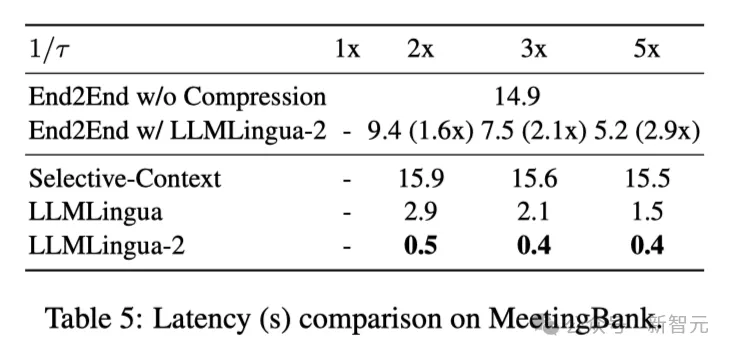
Table 5 above shows the latency of different systems on the V100-32G GPU with different compression ratios.
The results show that compared with other compression methods, LLMLlingua2 has much less computational overhead and can achieve an end-to-end speed improvement of 1.6 times to 2.9 times.
In addition, the researchers' method can reduce GPU memory costs by 8 times, thus reducing the demand for hardware resources.
Context-Aware Observations The researchers observed that as the compression ratio increases, LLMLingua-2 can effectively maintain the most informative words with complete context.
This is thanks to the adoption of a bidirectional context-aware feature extractor and a strategy that is explicitly optimized towards the goal of timely compression.
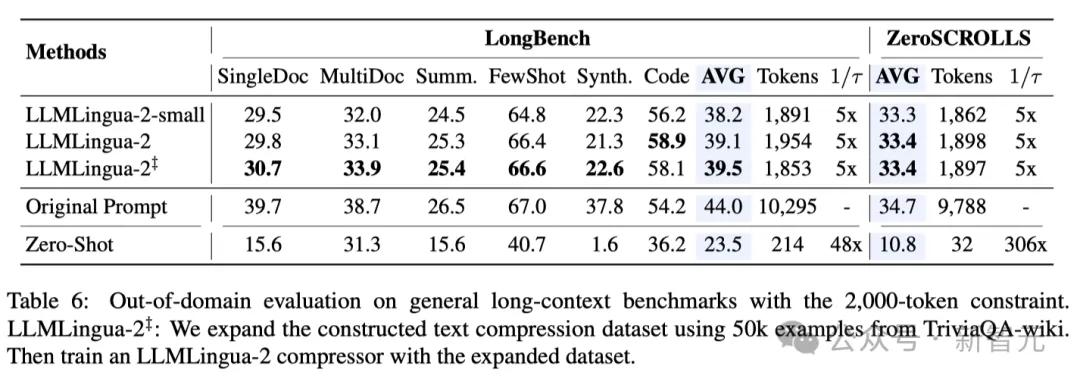
The researchers observed that as the compression ratio increases, LLMLingua-2 can effectively maintain the most informative words related to the complete context. .
This is thanks to the adoption of a bidirectional context-aware feature extractor and a strategy that is explicitly optimized towards the goal of timely compression.
Finally the researchers had GPT-4 reconstruct the original tones from the LLMLlingua-2 compression prompts.
The results show that GPT-4 can effectively reconstruct the original tip, indicating that no essential information is lost during LLMLingua-2 compression.
The above is the detailed content of Tsinghua Microsoft open sourced a new prompt word compression tool, the length dropped by 80%! GitHub gets 3.1K stars. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Microsoft bing international version entrance address (bing search engine entrance)
Mar 14, 2024 pm 01:37 PM
Microsoft bing international version entrance address (bing search engine entrance)
Mar 14, 2024 pm 01:37 PM
Bing is an online search engine launched by Microsoft. The search function is very powerful and has two entrances: the domestic version and the international version. Where are the entrances to these two versions? How to access the international version? Let’s take a look at the details below. Bing Chinese version website entrance: https://cn.bing.com/ Bing international version website entrance: https://global.bing.com/ How to access Bing international version? 1. First enter the URL to open Bing: https://www.bing.com/ 2. You can see that there are options for domestic and international versions. We only need to select the international version and enter keywords.
 Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
According to news on June 3, Microsoft is actively sending full-screen notifications to all Windows 10 users to encourage them to upgrade to the Windows 11 operating system. This move involves devices whose hardware configurations do not support the new system. Since 2015, Windows 10 has occupied nearly 70% of the market share, firmly establishing its dominance as the Windows operating system. However, the market share far exceeds the 82% market share, and the market share far exceeds that of Windows 11, which will be released in 2021. Although Windows 11 has been launched for nearly three years, its market penetration is still slow. Microsoft has announced that it will terminate technical support for Windows 10 after October 14, 2025 in order to focus more on
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 Microsoft Edge upgrade: Automatic password saving function banned? ! Users were shocked!
Apr 19, 2024 am 08:13 AM
Microsoft Edge upgrade: Automatic password saving function banned? ! Users were shocked!
Apr 19, 2024 am 08:13 AM
News on April 18th: Recently, some users of the Microsoft Edge browser using the Canary channel reported that after upgrading to the latest version, they found that the option to automatically save passwords was disabled. After investigation, it was found that this was a minor adjustment after the browser upgrade, rather than a cancellation of functionality. Before using the Edge browser to access a website, users reported that the browser would pop up a window asking if they wanted to save the login password for the website. After choosing to save, Edge will automatically fill in the saved account number and password the next time you log in, providing users with great convenience. But the latest update resembles a tweak, changing the default settings. Users need to choose to save the password and then manually turn on automatic filling of the saved account and password in the settings.
 Microsoft Edge browser update: Added "zoom in image" function to improve user experience
Mar 21, 2024 pm 01:40 PM
Microsoft Edge browser update: Added "zoom in image" function to improve user experience
Mar 21, 2024 pm 01:40 PM
According to news on March 21, Microsoft recently updated its Microsoft Edge browser and added a practical "enlarge image" function. Now, when using the Edge browser, users can easily find this new feature in the pop-up menu by simply right-clicking on the image. What’s more convenient is that users can also hover the cursor over the image and then double-click the Ctrl key to quickly invoke the function of zooming in on the image. According to the editor's understanding, the newly released Microsoft Edge browser has been tested for new features in the Canary channel. The stable version of the browser has also officially launched the practical "enlarge image" function, providing users with a more convenient image browsing experience. Foreign science and technology media also paid attention to this
 Microsoft Win11's function of compressing 7z and TAR files has been downgraded from 24H2 to 23H2/22H2 versions
Apr 28, 2024 am 09:19 AM
Microsoft Win11's function of compressing 7z and TAR files has been downgraded from 24H2 to 23H2/22H2 versions
Apr 28, 2024 am 09:19 AM
According to news from this site on April 27, Microsoft released the Windows 11 Build 26100 preview version update to the Canary and Dev channels earlier this month, which is expected to become a candidate RTM version of the Windows 1124H2 update. The main changes in the new version are the file explorer, Copilot integration, editing PNG file metadata, creating TAR and 7z compressed files, etc. @PhantomOfEarth discovered that Microsoft has devolved some functions of the 24H2 version (Germanium) to the 23H2/22H2 (Nickel) version, such as creating TAR and 7z compressed files. As shown in the diagram, Windows 11 will support native creation of TAR
 Microsoft plans to phase out NTLM in Windows 11 in the second half of 2024 and fully shift to Kerberos authentication
Jun 09, 2024 pm 04:17 PM
Microsoft plans to phase out NTLM in Windows 11 in the second half of 2024 and fully shift to Kerberos authentication
Jun 09, 2024 pm 04:17 PM
In the second half of 2024, the official Microsoft Security Blog published a message in response to the call from the security community. The company plans to eliminate the NTLAN Manager (NTLM) authentication protocol in Windows 11, released in the second half of 2024, to improve security. According to previous explanations, Microsoft has already made similar moves before. On October 12 last year, Microsoft proposed a transition plan in an official press release aimed at phasing out NTLM authentication methods and pushing more enterprises and users to switch to Kerberos. To help enterprises that may be experiencing issues with hardwired applications and services after turning off NTLM authentication, Microsoft provides IAKerb and
 Samsung will provide displays for Microsoft's MR headsets, and the devices are expected to be lighter and have clearer displays
Aug 10, 2024 pm 09:45 PM
Samsung will provide displays for Microsoft's MR headsets, and the devices are expected to be lighter and have clearer displays
Aug 10, 2024 pm 09:45 PM
Recently, Samsung Display and Microsoft signed an important cooperation agreement. According to the agreement, Samsung Display will develop and supply hundreds of thousands of OLEDoS panels for mixed reality (MR) head-mounted devices to Microsoft. Microsoft is developing an MR device for multimedia content such as games and movies. This device is expected to It will be launched after the OLEDoS specifications are finalized, mainly serving the commercial field, and is expected to be delivered as early as 2026. OLEDoS (OLED on Silicon) technology OLEDoS is a new display technology that deposits OLED on a silicon substrate. Compared with traditional glass substrates, it is thinner and has higher pixels. OLEDoS display and ordinary display
