
 Technology peripherals
AI
StreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source
Technology peripherals
AI
StreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source
StreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source

Wide shot of battlefield, stormtroopers running...

prompt: Wide shot of battlefield, stormtroopers running...
This 2-minute video with 1,200 frames was generated by a text-to-video model. Although the traces of AI are still obvious, the characters and scenes show quite good consistency.
How is this done? You should know that although the generation quality and text alignment quality of Vincent video technology have been quite good in recent years, most existing methods focus on generating short videos (usually 16 or 24 frames in length). However, existing methods that work for short videos often fail to work with long videos (≥ 64 frames).
Even generating short sequences often requires expensive training, such as training steps exceeding 260K and batch sizes exceeding 4500. If you do not train on longer videos and use a short video generator to produce long videos, the resulting long videos are often of poor quality. The existing autoregressive method (generating a new short video by using the last few frames of the short video, and then synthesizing the long video) also has some problems such as inconsistent scene switching.
In order to make up for the shortcomings of existing methods, Picsart AI Research and other institutions jointly proposed a new Vincent video method: StreamingT2V. This method uses autoregressive technology and combines it with a long short-term memory module, which enables it to generate long videos with strong temporal coherence.

- Paper title: StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
- Paper address: https://arxiv.org/abs/2403.14773
- Project address: https://streamingt2v.github.io/
The following is a 600-frame 1-minute video generation result. You can see that bees and flowers have excellent consistency:
Therefore, the team put forward the conditions Attention Module (CAM). CAM uses its attention mechanism to effectively integrate information from previous frames to generate new frames, and can freely handle motion in new frames without being restricted by the structure or shape of previous frames.
In order to solve the problem of appearance changes of people and objects in the generated video, the team also proposed the Appearance Preservation Module (APM): it can start from an initial image (anchor frame) Extract appearance information of objects or global scenes and use this information to regulate the video generation process for all video patches.
To further improve the quality and resolution of long video generation, the team improved a video enhancement model for the autoregressive generation task. To do this, the team selected a high-resolution Vincent video model and used the SDEdit method to improve the quality of 24 consecutive video blocks (with 8 overlapping frames).
To smooth the video block enhancement transition, they also designed a random blending method that blends overlapping enhanced video blocks in a seamless manner.
Method
First, generate a 5 second long 256 × 256 resolution video (16fps), then enhance it to higher resolution (720 × 720). Figure 2 shows its complete workflow.
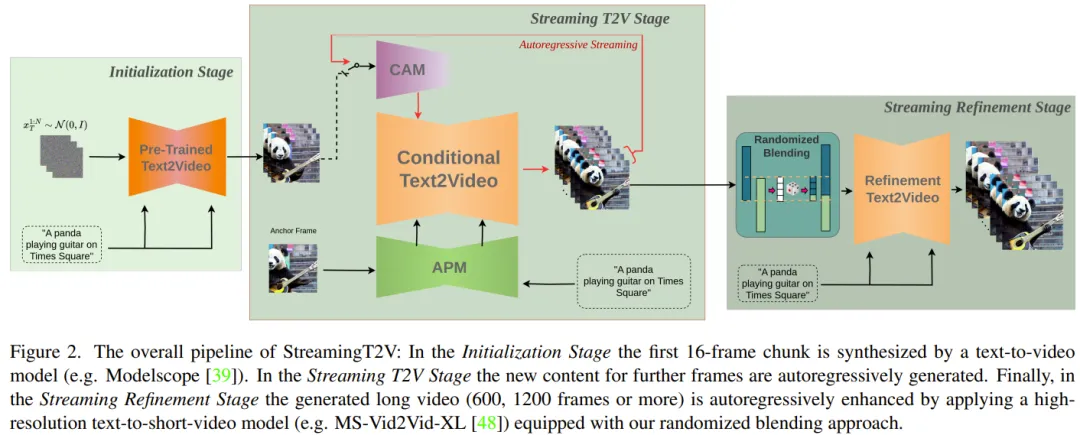
The long video generation part consists of the Initialization Stage and the Streaming T2V Stage.
Among them, the initialization stage is to use a pre-trained Vincent video model (for example, you can use Modelscope) to generate the first 16-frame video block; while the streaming Vincent video stage is Generate new content for subsequent frames in an autoregressive manner.
For the autoregressive process (see Figure 3), the team’s newly proposed CAM can utilize the short-term information of the last 8 frames of the previous video block to achieve seamless switching between blocks. In addition, they will also use the newly proposed APM module to extract long-term information of a fixed anchor frame, so that the autoregressive process can robustly cope with changes in things and scene details during the generation process.
After generating long videos (80, 240, 600, 1200 or more frames), they then improve them through the Streaming Refinement Stage Video quality. This process uses a high-resolution Vison short video model (e.g., MS-Vid2Vid-XL) in an autoregressive manner, coupled with a newly proposed stochastic mixing method for seamless video block processing. Furthermore, the latter step does not require additional training, which makes this method less computationally expensive.
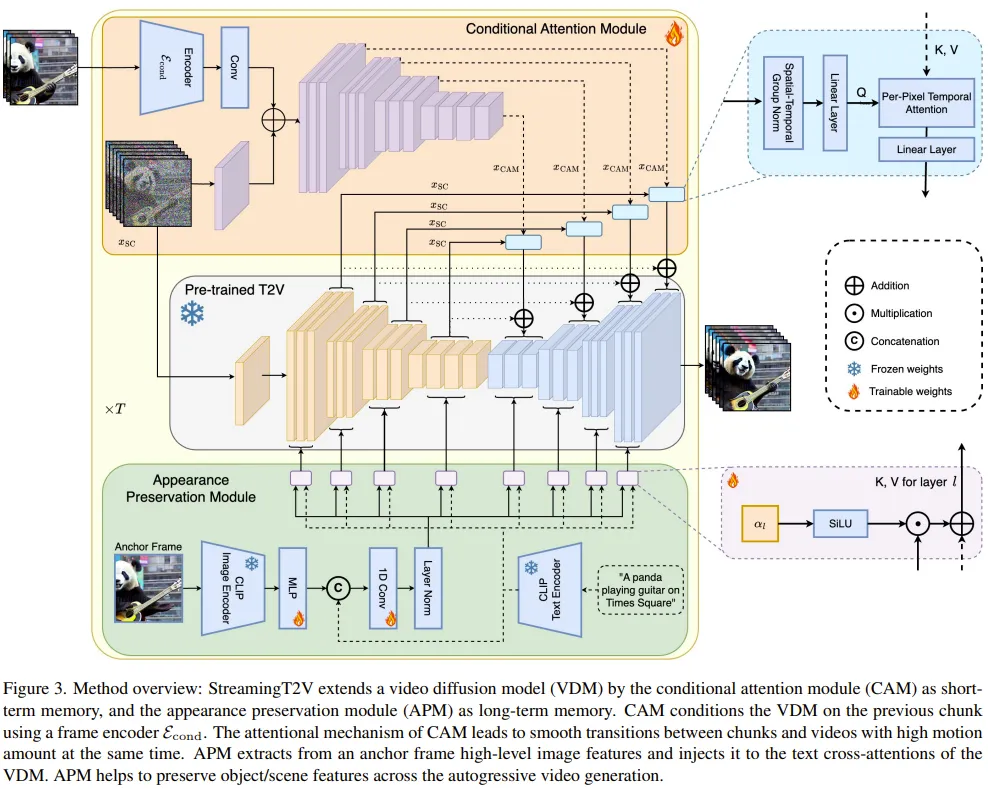
Conditional attention module
First, use the pre-trained text ( Short) video model is denoted as Video-LDM. The attention module (CAM) consists of a feature extractor and a feature injector injected into Video-LDM UNet.
The feature extractor uses a frame-by-frame image encoder, followed by the same encoder layer used by Video-LDM UNet until the middle layer (and initialized by the weight of UNet ).
For feature injection, the design here is to let each long-range jump connection in UNet focus on the corresponding features generated by CAM through cross attention.
Appearance Preservation Module
The APM module can fix the information in the anchor frame by using to integrate long-term memory into the video generation process. This helps maintain scene and object characteristics during video patch generation.
In order to allow APM to balance the processing of guidance information given by anchor frames and text instructions, the team has made two improvements: (1) Combine the CLIP image token of the anchor frame with the text The CLIP text tokens of the instructions are mixed; (2) A weight is introduced for each cross-attention layer to use cross-attention.
Autoregressive Video Enhancement
To autoregressively enhance the generated video block of 24 frames, here we use High-resolution (1280x720) Vincent (short) video model (Refiner Video-LDM, see Figure 3). This process is done by first adding a large amount of noise to the input video block, and then using this Vincent video diffusion model to perform denoising processing.
However, this method is not enough to solve the problem of transition mismatch between video blocks.
To this end, the team’s solution is a random hybrid approach. Please refer to the original paper for specific details.
Experiment
In the experiment, the evaluation metrics used by the team include: SCuts score for evaluating temporal consistency, Motion-aware twist error (MAWE) for amount of motion and twist error, CLIP text-image similarity score (CLIP) for evaluating text alignment quality, aesthetic score (AE).
Ablation Study
To evaluate the effectiveness of various new components, the team Ablation studies were performed on 75 prompts randomly sampled from the validation set.
CAM for conditional processing: CAM helps the model generate more consistent videos, with SCuts scores 88% lower than other baseline models in comparison.
Long-term memory: Figure 6 shows that long-term memory can greatly help maintain the stability of the characteristics of objects and scenes during the autoregressive generation process.

On a quantitative evaluation metric (person re-identification score), APM achieved a 20% improvement.
Random mixing for video enhancement: Compared with the other two benchmarks, random mixing can bring significant quality improvements, which can also be seen from Figure 4: StreamingT2V can get Smoother transitions.

##StreamingT2V compared to the baseline model
The The team compared the integration of the above-mentioned improved StreamingT2V with multiple models through quantitative and qualitative evaluations, including the image-to-video method I2VGen-XL, SVD, DynamiCrafter-XL, SEINE using the autoregressive method, the video-to-video method SparseControl, and the text-to-long video MethodFreeNoise.
Quantitative evaluation: As can be seen from Table 8, quantitative evaluation on the test set shows that StreamingT2V performs best in terms of seamless video block transition and motion consistency. The MAWE score of the new method is also significantly better than all other methods - even more than 50% lower than the second-best SEINE. Similar behavior is seen in SCuts scores.
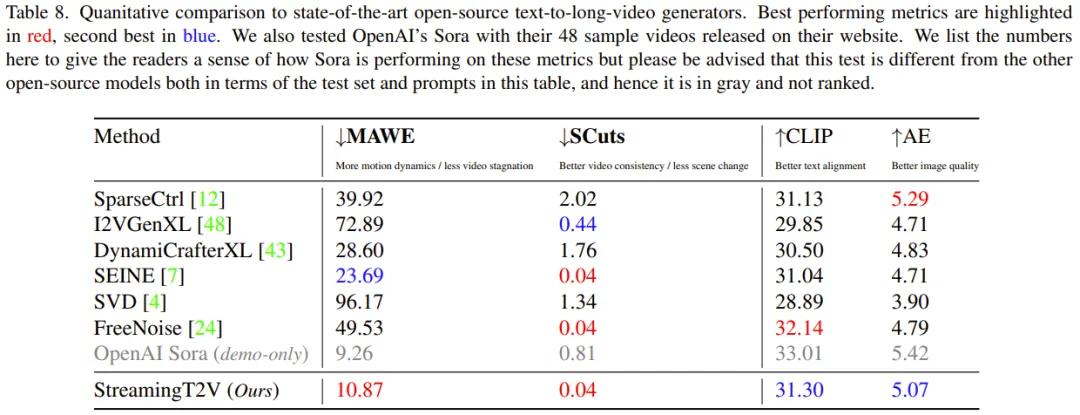
In addition, StreamingT2V is only slightly inferior to SparseCtrl in terms of the single-frame quality of the generated video. This shows that this new method is able to generate high-quality long videos with better temporal consistency and motion dynamics than other comparison methods.
Qualitative evaluation: The following figure shows the comparison of the effects of StreamingT2V with other methods. It can be seen that the new method can maintain better consistency while ensuring the dynamic effect of the video.

For more research details, please refer to the original paper.
The above is the detailed content of StreamingT2V, a long video generator of two minutes and 1200 frames, is here, and the code will be open source. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
When converting strings to objects in Vue.js, JSON.parse() is preferred for standard JSON strings. For non-standard JSON strings, the string can be processed by using regular expressions and reduce methods according to the format or decoded URL-encoded. Select the appropriate method according to the string format and pay attention to security and encoding issues to avoid bugs.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Summary: There are the following methods to convert Vue.js string arrays into object arrays: Basic method: Use map function to suit regular formatted data. Advanced gameplay: Using regular expressions can handle complex formats, but they need to be carefully written and considered. Performance optimization: Considering the large amount of data, asynchronous operations or efficient data processing libraries can be used. Best practice: Clear code style, use meaningful variable names and comments to keep the code concise.
 How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
In order to set the timeout for Vue Axios, we can create an Axios instance and specify the timeout option: In global settings: Vue.prototype.$axios = axios.create({ timeout: 5000 }); in a single request: this.$axios.get('/api/users', { timeout: 10000 }).
 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
MySQL performance optimization needs to start from three aspects: installation configuration, indexing and query optimization, monitoring and tuning. 1. After installation, you need to adjust the my.cnf file according to the server configuration, such as the innodb_buffer_pool_size parameter, and close query_cache_size; 2. Create a suitable index to avoid excessive indexes, and optimize query statements, such as using the EXPLAIN command to analyze the execution plan; 3. Use MySQL's own monitoring tool (SHOWPROCESSLIST, SHOWSTATUS) to monitor the database health, and regularly back up and organize the database. Only by continuously optimizing these steps can the performance of MySQL database be improved.
