
 Technology peripherals
AI
Detailed explanation of Latte: the world's first open source Vincent video DiT launched at the end of last year
Technology peripherals
AI
Detailed explanation of Latte: the world's first open source Vincent video DiT launched at the end of last year
Detailed explanation of Latte: the world's first open source Vincent video DiT launched at the end of last year

With the successful launch of Sora, the video DiT model has attracted widespread attention and discussion. Designing stable and very large-scale neural networks has always been a focus of research in the field of vision generation. The success of the DiT model brings new possibilities for scaling image generation.
However, due to the highly structured and complex nature of video data, extending DiT to the field of video generation is a challenging task. A team composed of research teams from the Shanghai Artificial Intelligence Laboratory and other institutions answered this question through large-scale experiments.
In November last year, the team had released a self-developed model called Latte, whose technology is similar to Sora. Latte is the world's first open source Wensheng video DiT and has received widespread attention. Many open source frameworks such as Open-Sora Plan (PKU) and Open-Sora (ColossalAI) are using and referring to Latte's model design.

- ##Open source link: https://github.com/Vchitect/Latte
- Project homepage: https://maxin-cn.github.io/latte_project/
- Paper link: https:/ /arxiv.org/pdf/2401.03048v1.pdf
Let’s first look at Latte’s video generation effect.

Method introduction
In general, Latte contains two key modules: pre-trained VAE and video DiT. In the pre-trained VAE, the encoder is responsible for compressing the video from pixel space to latent space frame by frame, while the video DiT is responsible for extracting tokens and performing spatiotemporal modeling to process the latent representation. Finally, the VAE decoder maps the features back Pixel space to generate video. In order to obtain the best video quality, the researchers focused on two important aspects in Latte design, namely the overall structural design of the video DiT model and the best practice details of model training.
(1) Latte overall model structure design study
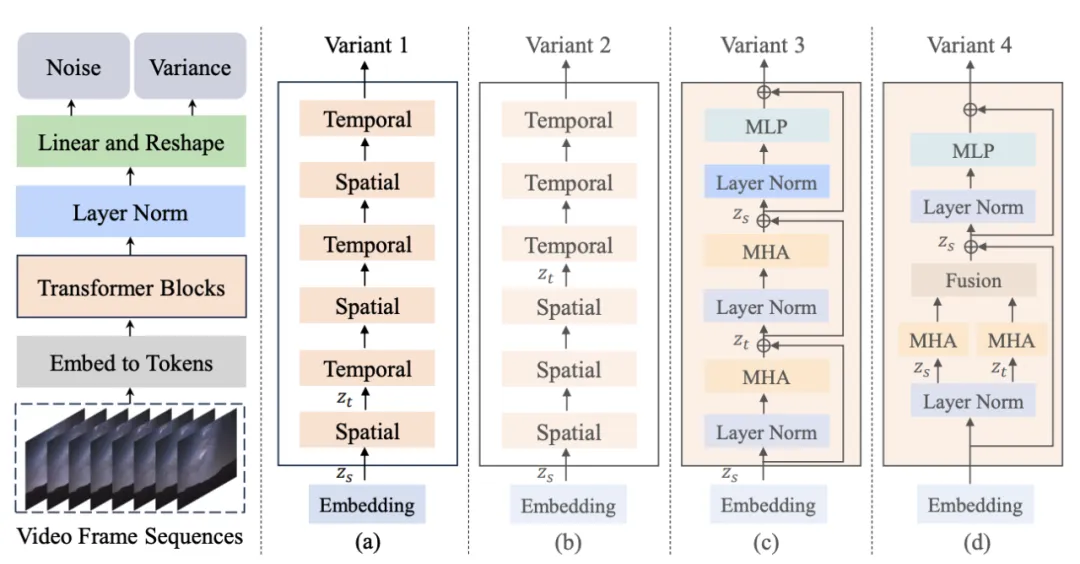
Figure 1 . Latte model structure and its variants
The author proposed 4 different Latte variants (Figure 1), and designed two Transformer modules from the perspective of spatiotemporal attention mechanism. Two variants (Variant) were studied in each module:
1. Single attention mechanism module, in each module only Contains time or space attention.
- Space-time interleaved modeling (Variant 1): The time module is inserted after each space module.
- Space-time sequential modeling (Variant 2): The time module is placed entirely after the space module.
2. Multiple attention mechanism module, each module contains both temporal and spatial attention mechanisms (Open-sora reference Variants).
- Serial spatiotemporal attention mechanism (Variant 3): Serial modeling of spatiotemporal attention mechanism.
- Parallel spatiotemporal attention mechanism (Variant 4): Parallel modeling and feature fusion of spatiotemporal attention mechanism.
Experiments show that (Figure 2), by setting the same parameter amounts for the four model variants, variant 4 has better performance in FLOPS than the other three variants. There is an obvious difference, so the FVD is also relatively the highest. The other three variants have similar overall performance. Variant 1 achieved the best performance. The author plans to conduct a more detailed discussion on large-scale data in the future.
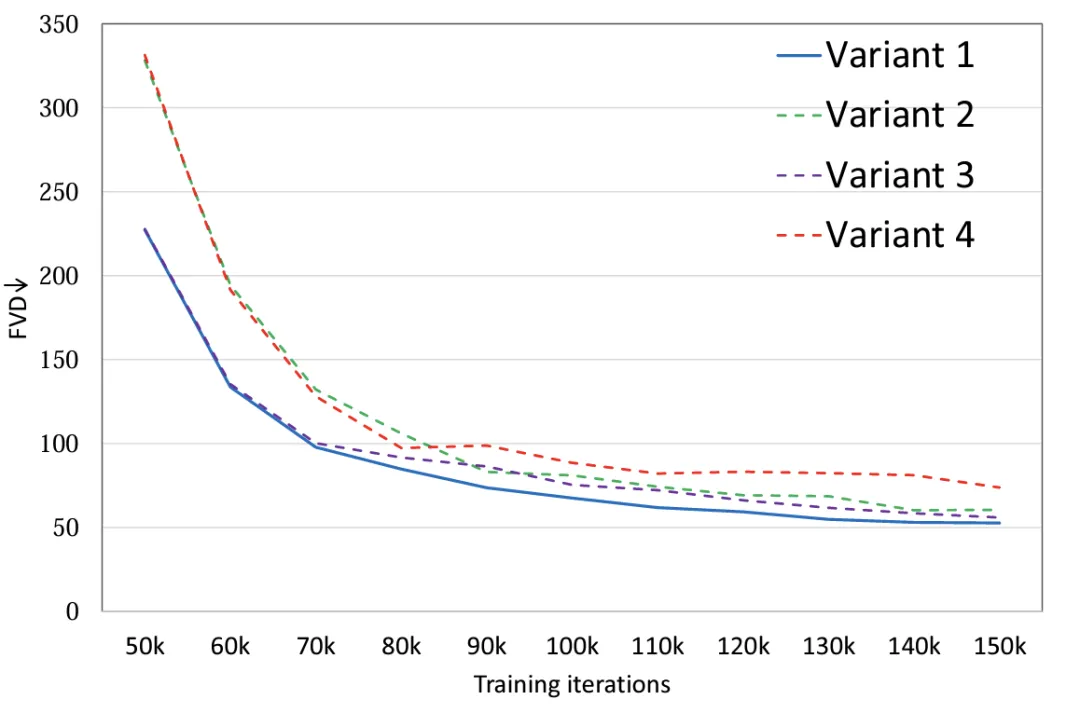
Figure 2. Model structure FVD
(2) Latte model and training details Exploring the optimal design (The best practices)
In addition to the overall structure design of the model, the author also explored factors that affect the generation effect in other models and training.
1.Token extraction: Two methods, single-frame token (a) and spatio-temporal token (b), were explored. The former only compresses tokens at the spatial level, while the latter compresses spatio-temporal information at the same time. Experiments show that single-frame token is better than spatio-temporal token (Figure 4). Comparing with Sora, the author speculates that the spatio-temporal token proposed by Sora is pre-compressed in the time dimension through video VAE, and similar to Latte's design in the latent space, only single-frame token processing is performed.
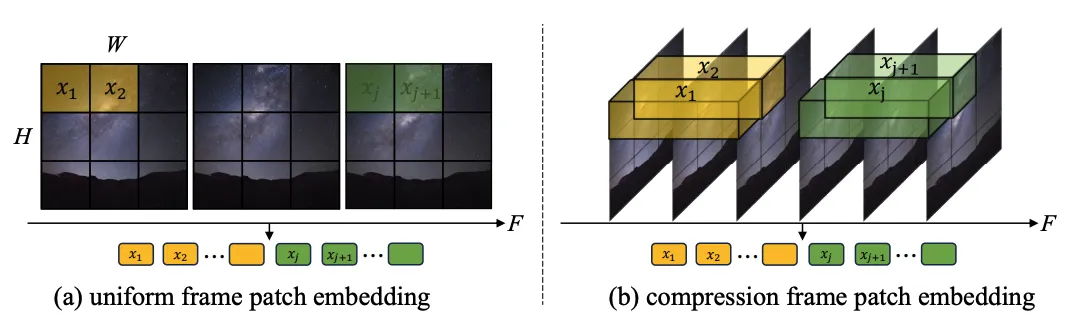
Figure 3. Token extraction method, (a) single frame token and (b) space-time token
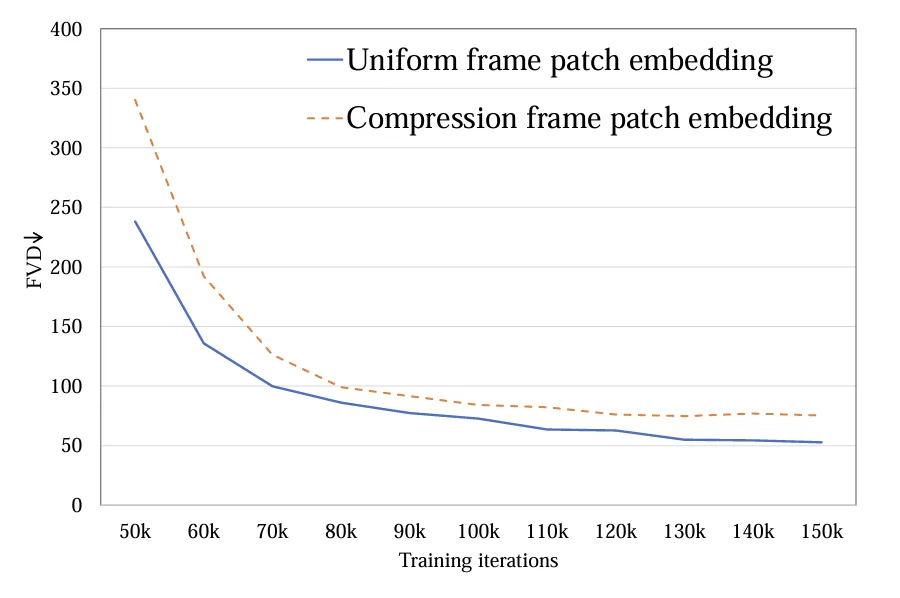
Figure 4. Token extraction FVD
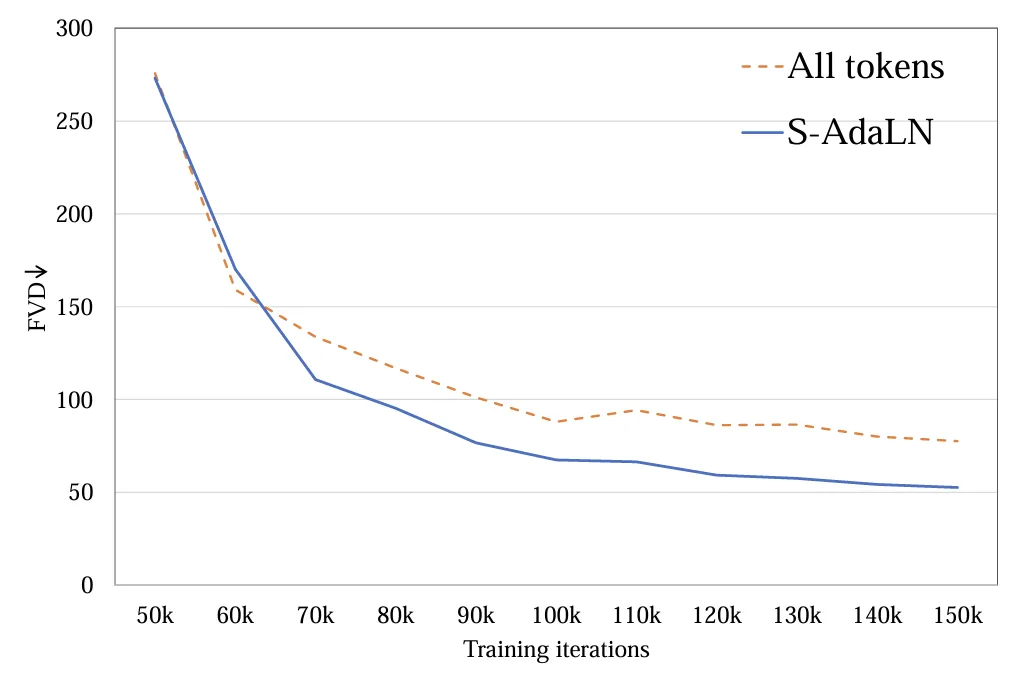
2. Conditional injection mode: Exploring (a) S-AdaLN and (b) all tokens two ways (Figure 5). S-AdaLN converts condition information into variables in normalization and injects it into the model through MLP. The All token form converts all conditions into a unified token as input to the model. Experiments have shown that the S-AdaLN method is more effective in obtaining high-quality results than all tokens (Figure 6). The reason is that S-AdaLN enables information to be injected directly into each module. However, all token needs to pass conditional information from the input to the end layer by layer, and there is a loss in the process of information flow.
3.
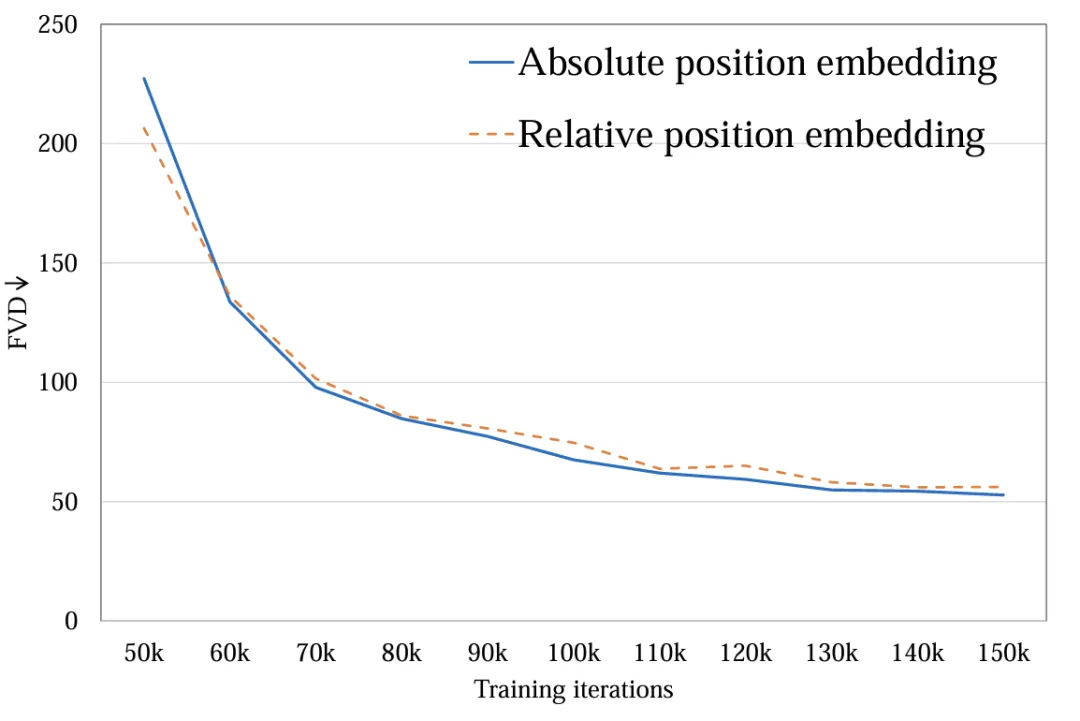
Space-time position encoding: Explore absolute position encoding and relative position encoding. Different position encodings have little impact on the final video quality (Figure 7). Due to the short generation duration, the difference in position encoding is not enough to affect the video quality. For long video generation, this factor needs to be reconsidered.
4.
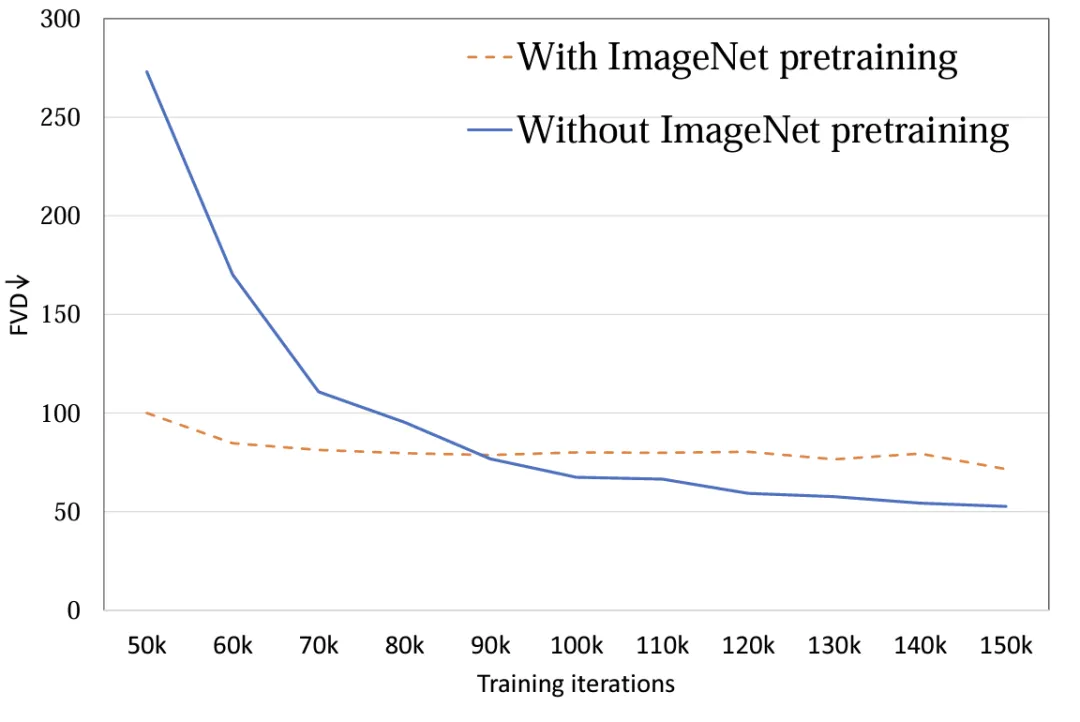
Model initialization : Explore the impact of using ImageNet pre-training parameter initialization on model performance. Experiments show that the model initialized using ImageNet has a faster convergence speed, however, as the training proceeds, the randomly initialized model achieves better results (Figure 8). The possible reason is that there is a relatively large distribution difference between ImageNet and the training set FaceForensics, so it failed to promote the final results of the model. For the Vincent video task, this conclusion needs to be reconsidered. In the distribution of general data sets, the content spatial distribution of images and videos is similar, and the use of pre-trained T2I models can greatly promote T2V.
5.
Image and video joint training: Compress videos and images into a unified token for joint training. The video token is responsible for optimizing all parameters, and the image token is only responsible for optimizing spatial parameters. Joint training has significantly improved the final results (Table 2 and Table 3). Both picture FID and video FVD have been reduced through joint training. This result is consistent with the UNet-based framework [2 ][3] are consistent.
6.Model Sizes: 4 different model sizes were explored, S, B, L and XL (Table 1). Expanding the scale of video DiT will significantly help improve the quality of generated samples (Figure 9). This conclusion also proves the correctness of using the Transformer structure in the video diffusion model for subsequent scaling up.
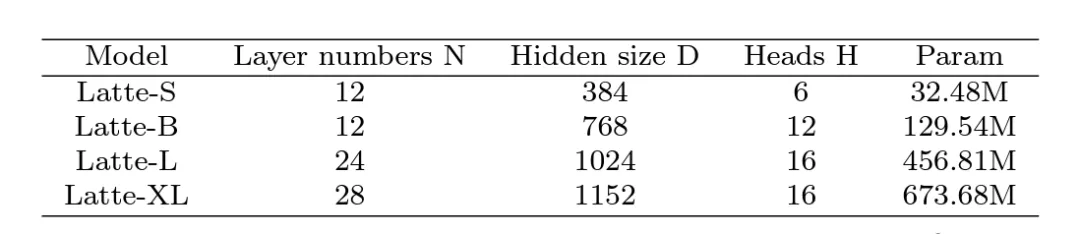
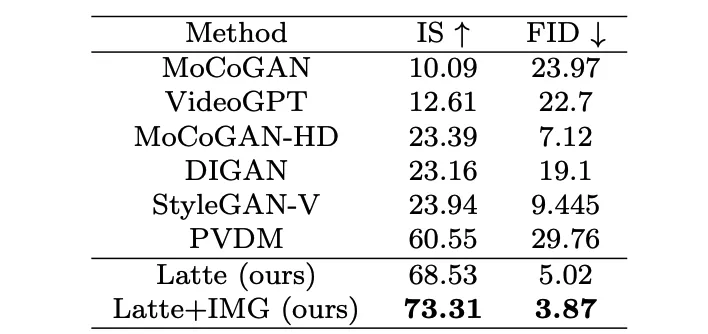
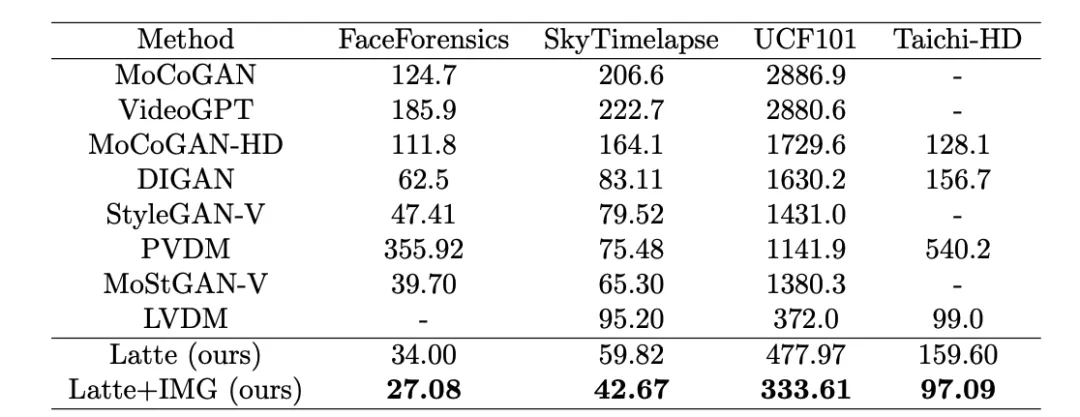
Figure 9. Model size FVD Author Trained on 4 academic data sets (FaceForensics, TaichiHD, SkyTimelapse and UCF101) respectively. The qualitative and quantitative results (Table 2 and Table 3) show that Latte achieved the best performance, which proves that the overall design of the model is excellent. ##Table 2. UCF101 Image Quality Assessment Table 3. Latte and SoTA video quality evaluation ## Vincent Video Extension Discussion and Summary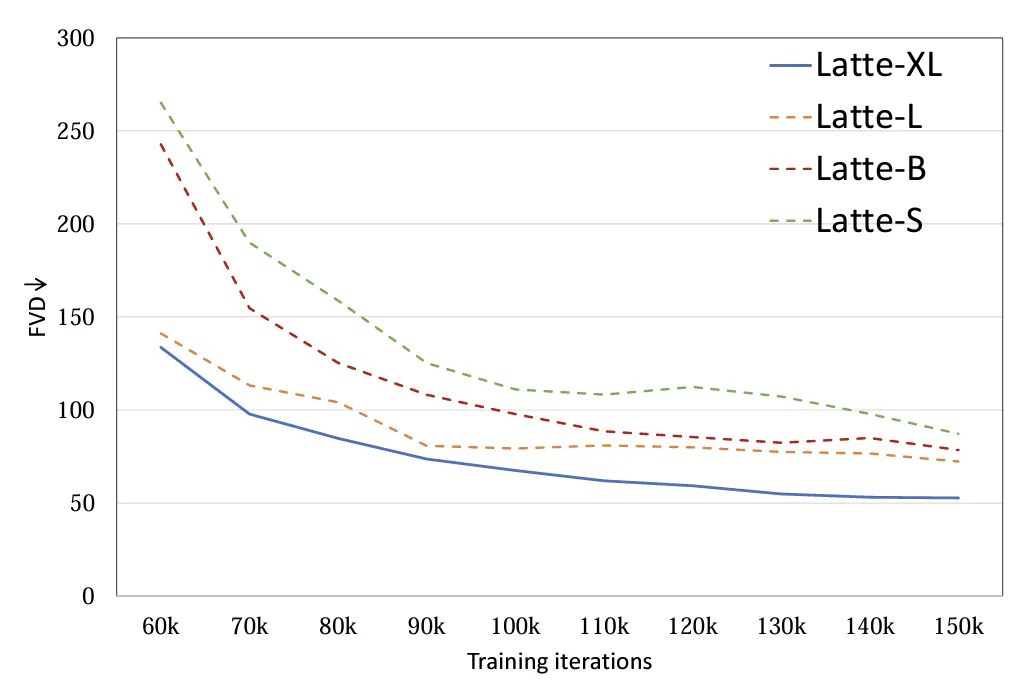
Qualitative and quantitative analysis
Latte, as the world’s first open source Vincent video DiT, has achieved promising results, but due to computational There is a huge difference in resources, and there is still a big gap compared with Sora in terms of generation clarity, fluency and duration. The team welcomes and is actively seeking cooperation of all kinds, hoping to use the power of open source to create a self-developed large-scale universal video generation model with excellent performance.
The above is the detailed content of Detailed explanation of Latte: the world's first open source Vincent video DiT launched at the end of last year. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
