
 Technology peripherals
AI
An AI video can be generated from just one picture! Google's new diffusion model makes characters move
Technology peripherals
AI
An AI video can be generated from just one picture! Google's new diffusion model makes characters move
An AI video can be generated from just one picture! Google's new diffusion model makes characters move

With just a photo and a piece of audio, you can directly generate a video of the character talking!
Recently, researchers from Google released the multi-modal diffusion model VLOGGER, taking us one step closer to virtual digital humans.

Paper address: https://enriccorona.github.io/vlogger/paper.pdf
Vlogger can collect a single input image, use text or audio driver, and generate a video of human speech, including mouth shapes, expressions, body movements, etc., which are very natural.
Let’s look at a few examples first:




If you feel that the use of other people’s voices in the video is a bit inconsistent, the editor will help you turn off the sound:

It can be seen that the entire generated effect is very elegant and natural.
VLOGGER builds on recent successes in generating diffusion models, including a model that translates humans into 3D motion, and a new diffusion-based architecture for control through time and space , enhance the effect of text-generated images.

VLOGGER can generate high-quality videos of variable length, and these videos can be easily controlled with high-level representations of faces and bodies.

For example, we can make the people in the generated video shut up:

Or close your eyes:

Compared with previous similar models, VLOGGER does not need to be trained on individuals and does not rely on Face detection and cropping, but also body movements, torso and background, constitute a normal human representation that can communicate.
AI voice, AI expression, AI action, AI scene, the value of human beings at the beginning is to provide data, but may it have no value in the future?


On the data side, the researchers collected a new, diverse dataset, MENTOR, than The previous similar data set was an entire order of magnitude larger. The training set included 2,200 hours and 800,000 different individuals, and the test set included 120 hours and 4,000 people with different identities.

The researchers evaluated VLOGGER on three different benchmarks, showing that the model achieves state-of-the-art performance in image quality, identity preservation, and temporal consistency. of optimal.

VLOGGER
The goal of VLOGGER is to generate a variable-length realistic video depicting the entire process of the target person speaking, Includes head movements and gestures.

As shown above, given a single input image shown in column 1 and a sample audio input, a series of Composite image.
Including generating head movements, gazes, blinks, lip movements, and something that previous models were unable to do, generating upper body and gestures, which is a major advancement in audio-driven synthesis.
VLOGGER adopts a two-stage pipeline based on a random diffusion model to simulate one-to-many mapping from speech to video.
The first network takes audio waveforms as input to generate body motion controls responsible for gaze, facial expressions and gestures over the length of the target video.
The second network is a temporal image-to-image translation model that extends the large image diffusion model to employ predicted body control to generate corresponding frames. To align this process with a specific identity, the network obtains a reference image of the target person.
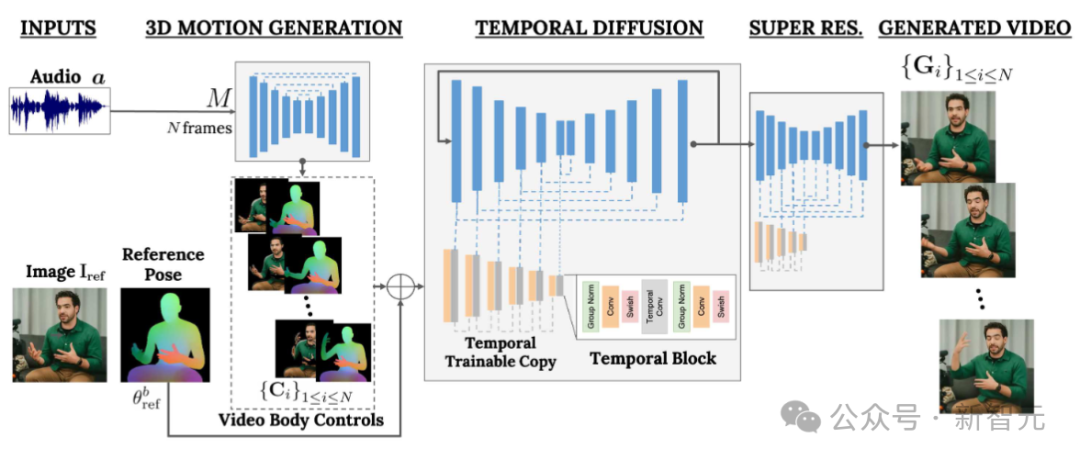
VLOGGER uses a statistically based 3D body model to regulate the video generation process. Given an input image, the predicted shape parameters encode the geometric properties of the target identity.
First, the network M takes the input speech and generates a series of N frames of 3D facial expressions and body poses.
A dense representation of the moving 3D body is then rendered to act as a 2D control during the video generation stage. These images, along with the input images, serve as input to the temporal diffusion model and super-resolution modules.
Audio-driven motion generation
The first network of the pipeline is designed to predict motion based on input speech. In addition, the input text is converted into a waveform through a text-to-speech model, and the generated audio is represented as standard Mel-Spectrograms.
The pipeline is based on the Transformer architecture and has four multi-head attention layers in the time dimension. Includes positional encoding of frame number and diffusion step, as well as embedding MLP for input audio and diffusion step.
In each frame, use a causal mask to make the model only focus on the previous frame. The model is trained using variable length videos (such as the TalkingHead-1KH dataset) to generate very long sequences.
The researchers employ statistically based estimated parameters of a 3D human body model to generate intermediate control representations for synthetic videos.
The model takes into account both facial expressions and body movements to generate better expressive and dynamic gestures.
In addition, previous face generation work usually relies on warped images, but this method has been ignored in diffusion-based architectures.
The authors recommend using distorted images to guide the generation process, which facilitates the network’s task and helps maintain the subject identity of the character.
Generate talking and moving humans
#The next goal is to perform motion processing on the input image of a person , making it follow previously predicted body and facial movements.
Inspired by ControlNet, the researchers froze the initially trained model and used input time controls to make a zero-initialized trainable copy of the encoding layer.
The author interleaves one-dimensional convolutional layers in the time domain. The network is trained by obtaining consecutive N frames and controls, and generates action videos of reference characters based on the input controls.
The model is trained using the MENTOR data set built by the author. Because during the training process, the network will obtain a series of continuous frames and arbitrary reference images, so in theory any video can be Frame specified as reference.
In practice, however, the authors choose to sample references further away from the target clip because closer examples offer less generalization potential.
The network is trained in two stages, first learning a new control layer on a single frame, and then training on the video by adding a temporal component. This allows the use of large batches in the first stage and faster learning of head-replay tasks.
The learning rate adopted by the author is 5e-5, and the image model is trained with a step size of 400k and a batch size of 128 in both stages.
Diversity
The following figure shows the diverse distribution of target videos generated from an input image. The rightmost column shows the pixel diversity obtained from the 80 generated videos.

The person's head and body move significantly while the background remains fixed (red means higher diversity of pixel colors) , and, despite the diversity, all videos look realistic.
Video Editing

One of the applications of the model is to edit existing video. In this case, VLOGGER takes a video and changes the subject's expression by closing their mouth or eyes, for example.
In practice, the author takes advantage of the flexibility of the diffusion model to repair the parts of the image that should be changed, making the video edit consistent with the original unchanged pixels.
Video Translation
One of the main applications of the model is video translation. In this case, VLOGGER takes an existing video in a specific language and edits the lips and facial areas to align with the new audio (e.g. Spanish).
The above is the detailed content of An AI video can be generated from just one picture! Google's new diffusion model makes characters move. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to record screen video with OPPO phone (simple operation)
May 07, 2024 pm 06:22 PM
How to record screen video with OPPO phone (simple operation)
May 07, 2024 pm 06:22 PM
Game skills or teaching demonstrations, in daily life, we often need to use mobile phones to record screen videos to show some operating steps. Its function of recording screen video is also very good, and OPPO mobile phone is a powerful smartphone. Allowing you to complete the recording task easily and quickly, this article will introduce in detail how to use OPPO mobile phones to record screen videos. Preparation - Determine recording goals You need to clarify your recording goals before you start. Do you want to record a step-by-step demonstration video? Or want to record a wonderful moment of a game? Or want to record a teaching video? Only by better arranging the recording process and clear goals. Open the screen recording function of OPPO mobile phone and find it in the shortcut panel. The screen recording function is located in the shortcut panel.
 What is the difference between quad-core and eight-core computer CPUs?
May 06, 2024 am 09:46 AM
What is the difference between quad-core and eight-core computer CPUs?
May 06, 2024 am 09:46 AM
What is the difference between quad-core and eight-core computer CPUs? The difference is processing speed and performance. A quad-core CPU has four processor cores, while an eight-core CPU has eight cores. This means that the former can perform four tasks at the same time, and the latter can perform eight tasks at the same time. Therefore, an octa-core CPU is faster than a quad-core CPU when used to process large amounts of data or run multiple programs. At the same time, eight-core CPUs are also better suited for multimedia work, such as video editing or gaming, as these tasks require higher processing speeds and better graphics processing power. However, the cost of eight-core CPUs is also higher, so it is very important to choose the right CPU based on actual needs and budget. Is a computer CPU better, dual-core or quad-core? Whether dual-core or quad-core is better depends on your usage needs.
 How to switch language in Adobe After Effects cs6 (Ae cs6) Detailed steps for switching between Chinese and English in Ae cs6 - ZOL download
May 09, 2024 pm 02:00 PM
How to switch language in Adobe After Effects cs6 (Ae cs6) Detailed steps for switching between Chinese and English in Ae cs6 - ZOL download
May 09, 2024 pm 02:00 PM
1. First find the AMTLanguages folder. We found some documentation in the AMTLanguages folder. If you install Simplified Chinese, there will be a zh_CN.txt text document (the text content is: zh_CN). If you installed it in English, there will be a text document en_US.txt (the text content is: en_US). 3. Therefore, if we want to switch to Chinese, we need to create a new text document of zh_CN.txt (the text content is: zh_CN) under the AdobeAfterEffectsCCSupportFilesAMTLanguages path. 4. On the contrary, if we want to switch to English,
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
 For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
The familiar open source large language models such as Llama3 launched by Meta, Mistral and Mixtral models launched by MistralAI, and Jamba launched by AI21 Lab have become competitors of OpenAI. In most cases, users need to fine-tune these open source models based on their own data to fully unleash the model's potential. It is not difficult to fine-tune a large language model (such as Mistral) compared to a small one using Q-Learning on a single GPU, but efficient fine-tuning of a large model like Llama370b or Mixtral has remained a challenge until now. Therefore, Philipp Sch, technical director of HuggingFace
 How to shoot videos on Douyin? How to turn on the microphone for video shooting?
May 09, 2024 pm 02:40 PM
How to shoot videos on Douyin? How to turn on the microphone for video shooting?
May 09, 2024 pm 02:40 PM
As one of the most popular short video platforms today, the quality and effect of Douyin’s videos directly affect the user’s viewing experience. So, how to shoot high-quality videos on Douyin? 1. How to shoot videos on Douyin? 1. Open the Douyin APP and click the "+" button in the middle at the bottom to enter the video shooting page. 2. Douyin provides a variety of shooting modes, including normal shooting, slow motion, short video, etc. Choose the appropriate shooting mode according to your needs. 3. On the shooting page, click the "Filter" button at the bottom of the screen to choose different filter effects to make the video more personalized. 4. If you need to adjust parameters such as exposure and contrast, you can click the "Parameters" button in the lower left corner of the screen to set it. 5. During shooting, you can click on the left side of the screen
