
 Technology peripherals
AI
Detailed explanation of rotational position encoding RoPE commonly used in large language models: why is it better than absolute or relative position encoding?
Technology peripherals
AI
Detailed explanation of rotational position encoding RoPE commonly used in large language models: why is it better than absolute or relative position encoding?
Detailed explanation of rotational position encoding RoPE commonly used in large language models: why is it better than absolute or relative position encoding?

Since the "Attention Is All You Need" paper published in 2017, the Transformer architecture has been the cornerstone of the natural language processing (NLP) field. Its design has remained largely unchanged for years, with 2022 marking a major development in the field with the introduction of Rotary Position Encoding (RoPE).
Rotated position embedding is the most advanced NLP position embedding technology. Most popular large-scale language models such as Llama, Llama2, PaLM, and CodeGen already use it. In this article, we’ll take a deep dive into what rotational positional encodings are, and how they neatly blend the advantages of absolute and relative positional embeddings.
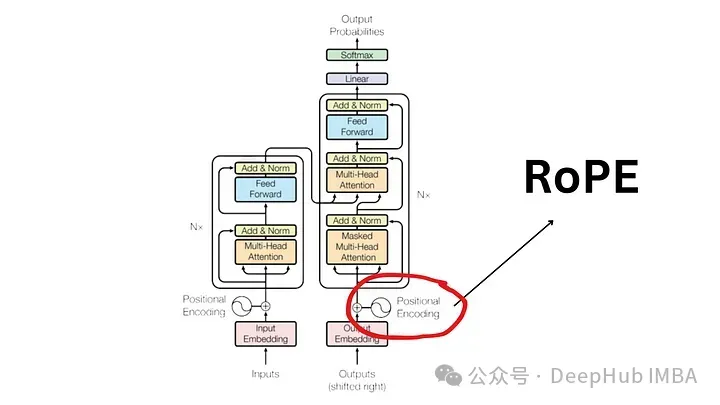
The need for positional encoding
In order to understand the importance of RoPE, let’s first review why positional encoding Encoding is crucial. Transformer models, by their inherent design, do not take into account the order of input tokens.
For example, phrases like "the dog chases the pig" and "the pig chases the dogs", although they have different meanings, are considered indistinguishable because they are treated as an unordered set of tokens. . In order to maintainsequence information and its meaning, a representation is needed to integrate positional information into the model.
Absolute position encoding
In order to encode the position in the sentence, another tool is required using a vector with the same dimensions, where each A vector represents a position in a sentence. For example, specify a specific vector for the second word in a sentence. Therefore, each sentence position has its unique vector. The input to the Transformer layer is then formed by combining the word embeddings with the embeddings of their corresponding positions.
There are two main ways to generate these embeddings:
- Learning from data: here , the position vector is learned during training, just like other model parameters. We learn a unique vector for each position (e.g. from 1 to 512). This introduces a limitation - the maximum sequence length is limited. If the model only learns position 512, it cannot represent sequences longer than that position.
- Sine Function: This method involves using a sine function to build a unique embedding for each position. Although the details of this construction are complex, it essentially provides a unique positional embedding for each position in the sequence. Empirical studies show that learning and using sine functions from data can provide comparable performance in real-world models.
Limitations of absolute positional encoding
Although widely used, absolute positional embedding is not without its disadvantages:
- Limited sequence length: As mentioned above, if the model learns a position vector for a certain point, it inherently cannot represent positions beyond that limit.
- Independence of positional embeddings: Each positional embedding is independent of other positional embeddings. This means that from the model's perspective, the difference between positions 1 and 2 is the same as the difference between positions 2 and 500. But in fact, positions 1 and 2 should be more closely related than position 500, which is significantly farther away. This lack of relative positioning may hinder the model's ability to understand the nuances of language structure.
Relative position encoding
The relative position does not focus on the absolute position of the note in the sentence, but on the relationship between the note pairs. distance. This method does not add position vectors directly to the word vectors. Instead, the attention mechanism is changed to incorporate relative position information.
T5 (Text-to-Text Transfer Transformer) is a well-known model that utilizes relative position embedding. T5 introduces a subtle way of handling position information:
- Bias of position offset: T5 uses bias (floating point number) to represent each Possible position offset. For example, bias B1 might represent the relative distance between any two tokens that are one position apart, regardless of their absolute position in the sentence.
- Integration in the self-attention layer: This relative position bias matrix is added to the product of the query matrix and the key matrix in the self-attention layer. This ensures that markers at the same relative distance are always represented by the same bias, regardless of their position in the sequence.
- Scalability: A significant advantage of this approach is its scalability. It can be extended to arbitrarily long sequences, which has obvious advantages over absolute position embedding.
Limitations of relative position encoding
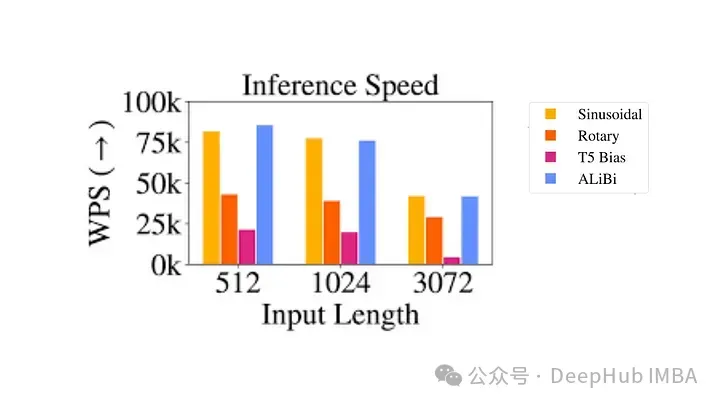
尽管它们在理论上很有吸引力,但相对位置编码得问题很严重
- 计算效率低下:必须创建成对的位置编码矩阵,然后执行大量张量操作以获得每个时间步的相对位置编码。特别是对于较长的序列。这主要是由于自注意力层中的额外计算步骤,其中位置矩阵被添加到查询键矩阵中。
- 键值缓存使用的复杂性:由于每个附加令牌都会改变每个其他令牌的嵌入,这使得 Transformer 中键值缓存的有效使用变得复杂。使用 KV 缓存的一项要求是已经生成的单词的位置编码, 在生成新单词时不改变(绝对位置编码提供)因此相对位置编码不适合推理,因为每个标记的嵌入会随着每个新时间步的变化而变化。
由于这些工程复杂性,位置编码未得到广泛采用,特别是在较大的语言模型中。
旋转位置编码 (RoPE)?
RoPE 代表了一种编码位置信息的新方法。传统方法中无论是绝对方法还是相对方法,都有其局限性。绝对位置编码为每个位置分配一个唯一的向量,虽然简单但不能很好地扩展并且无法有效捕获相对位置;相对位置编码关注标记之间的距离,增强模型对标记关系的理解,但使模型架构复杂化。
RoPE巧妙地结合了两者的优点。允许模型理解标记的绝对位置及其相对距离的方式对位置信息进行编码。这是通过旋转机制实现的,其中序列中的每个位置都由嵌入空间中的旋转表示。RoPE 的优雅之处在于其简单性和高效性,这使得模型能够更好地掌握语言语法和语义的细微差别。
旋转矩阵源自我们在高中学到的正弦和余弦的三角性质,使用二维矩阵应该足以获得旋转矩阵的理论,如下所示!
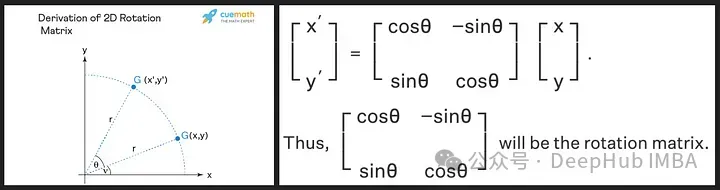
我们看到旋转矩阵保留了原始向量的大小(或长度),如上图中的“r”所示,唯一改变的是与x轴的角度。
RoPE 引入了一个新颖的概念。它不是添加位置向量,而是对词向量应用旋转。旋转角度 (θ) 与单词在句子中的位置成正比。第一个位置的向量旋转 θ,第二个位置的向量旋转 2θ,依此类推。这种方法有几个好处:
- 向量的稳定性:在句子末尾添加标记不会影响开头单词的向量,有利于高效缓存。
- 相对位置的保留:如果两个单词在不同的上下文中保持相同的相对距离,则它们的向量将旋转相同的量。这确保了角度以及这些向量之间的点积保持恒定
RoPE 的矩阵公式
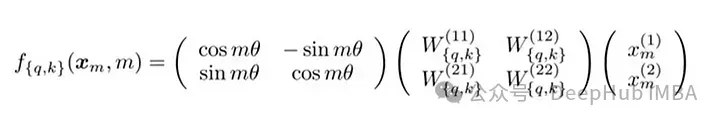
RoPE的技术实现涉及到旋转矩阵。在 2D 情况下,论文中的方程包含一个旋转矩阵,该旋转矩阵将向量旋转 Mθ 角度,其中 M 是句子中的绝对位置。这种旋转应用于 Transformer 自注意力机制中的查询向量和键向量。
对于更高维度,向量被分成 2D 块,并且每对独立旋转。这可以被想象成一个在空间中旋转的 n 维。听着这个方法好好像实现是复杂,其实不然,这在 PyTorch 等库中只需要大约十行代码就可以高效的实现。
import torch import torch.nn as nn class RotaryPositionalEmbedding(nn.Module): def __init__(self, d_model, max_seq_len): super(RotaryPositionalEmbedding, self).__init__() # Create a rotation matrix. self.rotation_matrix = torch.zeros(d_model, d_model, device=torch.device("cuda")) for i in range(d_model): for j in range(d_model): self.rotation_matrix[i, j] = torch.cos(i * j * 0.01) # Create a positional embedding matrix. self.positional_embedding = torch.zeros(max_seq_len, d_model, device=torch.device("cuda")) for i in range(max_seq_len): for j in range(d_model): self.positional_embedding[i, j] = torch.cos(i * j * 0.01) def forward(self, x): """Args:x: A tensor of shape (batch_size, seq_len, d_model). Returns:A tensor of shape (batch_size, seq_len, d_model).""" # Add the positional embedding to the input tensor. x += self.positional_embedding # Apply the rotation matrix to the input tensor. x = torch.matmul(x, self.rotation_matrix) return x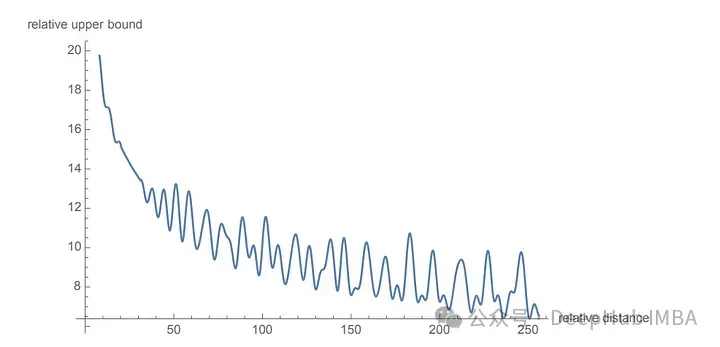
为了旋转是通过简单的向量运算而不是矩阵乘法来执行。距离较近的单词更有可能具有较高的点积,而距离较远的单词则具有较低的点积,这反映了它们在给定上下文中的相对相关性。
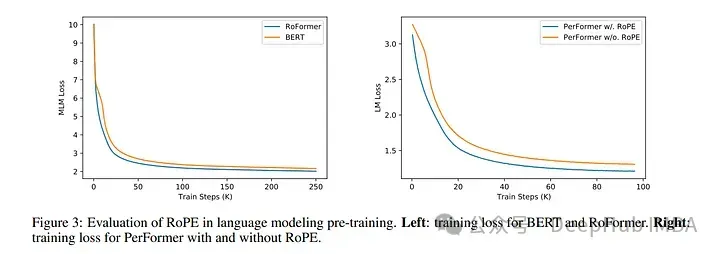
使用 RoPE 对 RoBERTa 和 Performer 等模型进行的实验表明,与正弦嵌入相比,它的训练时间更快。并且该方法在各种架构和训练设置中都很稳健。
最主要的是RoPE是可以外推的,也就是说可以直接处理任意长的问题。在最早的llamacpp项目中就有人通过线性插值RoPE扩张,在推理的时候直接通过线性插值将LLAMA的context由2k拓展到4k,并且性能没有下降,所以这也可以证明RoPE的有效性。
代码如下:
import transformers old_init = transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ def ntk_scaled_init(self, dim, max_position_embeddings=2048, base=10000, device=None): #The method is just these three linesmax_position_embeddings = 16384a = 8 #Alpha valuebase = base * a ** (dim / (dim-2)) #Base change formula old_init(self, dim, max_position_embeddings, base, device) transformers.models.llama.modeling_llama.LlamaRotaryEmbedding.__init__ = ntk_scaled_init
总结
旋转位置嵌入代表了 Transformer 架构的范式转变,提供了一种更稳健、直观和可扩展的位置信息编码方式。
RoPE不仅解决了LLM context过长之后引起的上下文无法关联问题,并且还提高了训练和推理的速度。这一进步不仅增强了当前的语言模型,还为 NLP 的未来创新奠定了基础。随着我们不断解开语言和人工智能的复杂性,像 RoPE 这样的方法将有助于构建更先进、更准确、更类人的语言处理系统。
The above is the detailed content of Detailed explanation of rotational position encoding RoPE commonly used in large language models: why is it better than absolute or relative position encoding?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Translator | Bugatti Review | Chonglou This article describes how to use the GroqLPU inference engine to generate ultra-fast responses in JanAI and VSCode. Everyone is working on building better large language models (LLMs), such as Groq focusing on the infrastructure side of AI. Rapid response from these large models is key to ensuring that these large models respond more quickly. This tutorial will introduce the GroqLPU parsing engine and how to access it locally on your laptop using the API and JanAI. This article will also integrate it into VSCode to help us generate code, refactor code, enter documentation and generate test units. This article will create our own artificial intelligence programming assistant for free. Introduction to GroqLPU inference engine Groq
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Apr 11, 2024 am 09:43 AM
Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Apr 11, 2024 am 09:43 AM
The potential of large language models is stimulated - high-precision time series prediction can be achieved without training large language models, surpassing all traditional time series models. Monash University, Ant and IBM Research jointly developed a general framework that successfully promoted the ability of large language models to process sequence data across modalities. The framework has become an important technological innovation. Time series prediction is beneficial to decision-making in typical complex systems such as cities, energy, transportation, and remote sensing. Since then, large models are expected to revolutionize time series/spatiotemporal data mining. The general large language model reprogramming framework research team proposed a general framework to easily use large language models for general time series prediction without any training. Two key technologies are mainly proposed: timing input reprogramming; prompt prefixing. Time-
 Does sticky positioning break away from the document flow?
Feb 20, 2024 pm 05:24 PM
Does sticky positioning break away from the document flow?
Feb 20, 2024 pm 05:24 PM
Does sticky positioning break away from the document flow? Specific code examples are needed. In web development, layout is a very important topic. Among them, positioning is one of the commonly used layout techniques. In CSS, there are three common positioning methods: static positioning, relative positioning and absolute positioning. In addition to these three positioning methods, there is also a more special positioning method, namely sticky positioning. So, does sticky positioning break away from the document flow? Let’s discuss it in detail below and provide some code examples to help understand. First, we need to understand what document flow is
 Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
This article will open source the results of "Local Deployment of Large Language Models in OpenHarmony" demonstrated at the 2nd OpenHarmony Technology Conference. Open source address: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/InferLLM/docs/ hap_integrate.md. The implementation ideas and steps are to transplant the lightweight LLM model inference framework InferLLM to the OpenHarmony standard system, and compile a binary product that can run on OpenHarmony. InferLLM is a simple and efficient L
 Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 and full-scenario new product launch conference, a number of blockbuster new products were released together
Aug 08, 2024 am 07:02 AM
This afternoon, Hongmeng Zhixing officially welcomed new brands and new cars. On August 6, Huawei held the Hongmeng Smart Xingxing S9 and Huawei full-scenario new product launch conference, bringing the panoramic smart flagship sedan Xiangjie S9, the new M7Pro and Huawei novaFlip, MatePad Pro 12.2 inches, the new MatePad Air, Huawei Bisheng With many new all-scenario smart products including the laser printer X1 series, FreeBuds6i, WATCHFIT3 and smart screen S5Pro, from smart travel, smart office to smart wear, Huawei continues to build a full-scenario smart ecosystem to bring consumers a smart experience of the Internet of Everything. Hongmeng Zhixing: In-depth empowerment to promote the upgrading of the smart car industry Huawei joins hands with Chinese automotive industry partners to provide
 Natural language processing: enabling computers to understand and process human language
Sep 21, 2023 pm 03:53 PM
Natural language processing: enabling computers to understand and process human language
Sep 21, 2023 pm 03:53 PM
Natural Language Processing (NLP) is an important and exciting technology in the field of artificial intelligence. Its goal is to enable computers to understand, parse and generate human language. The development of NLP has made tremendous progress, enabling computers to better interact with humans and achieve a wider range of applications. This article will explore the concepts, technologies, applications and future prospects of natural language processing. The concept of natural language processing. Natural language processing is a discipline that studies how to enable computers to understand and process human language. The complexity and ambiguity of human language make computers face huge challenges in understanding and processing. The goal of NLP is to develop algorithms and models that enable computers to extract information from text
 Stimulate the spatial reasoning ability of large language models: thinking visualization tips
Apr 11, 2024 pm 03:10 PM
Stimulate the spatial reasoning ability of large language models: thinking visualization tips
Apr 11, 2024 pm 03:10 PM
Large language models (LLMs) demonstrate impressive performance in language understanding and various reasoning tasks. However, their role in spatial reasoning, a key aspect of human cognition, remains understudied. Humans have the ability to create mental images of unseen objects and actions through a process known as the mind's eye, making it possible to imagine the unseen world. Inspired by this cognitive ability, researchers proposed "Visualization of Thought" (VoT). VoT aims to guide the spatial reasoning of LLMs by visualizing their reasoning signs, thereby guiding subsequent reasoning steps. Researchers apply VoT to multi-hop spatial reasoning tasks, including natural language navigation, vision
