
 Technology peripherals
AI
Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article
Technology peripherals
AI
Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article
Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article

作為點集合的點雲有望透過3D重建、工業檢測和機器人操作中,在獲取和生成物體的三維(3D)表面資訊方面帶來一場改變。最具挑戰性但必不可少的過程是點雲配準,即獲得一個空間變換,該變換將在兩個不同座標中獲得的兩個點雲對齊並匹配。這篇綜述介紹了點雲配準的概述和基本原理,對各種方法進行了系統的分類和比較,並解決了點雲配準中存在的技術問題,試圖為該領域以外的學術研究人員和工程師提供指導,並促進點雲配準統一願景的討論。
點雲獲取的一般方式
分為主動和被動方式,由感測器主動獲取的點雲為主動方式,後期通過重建的方式為被動。
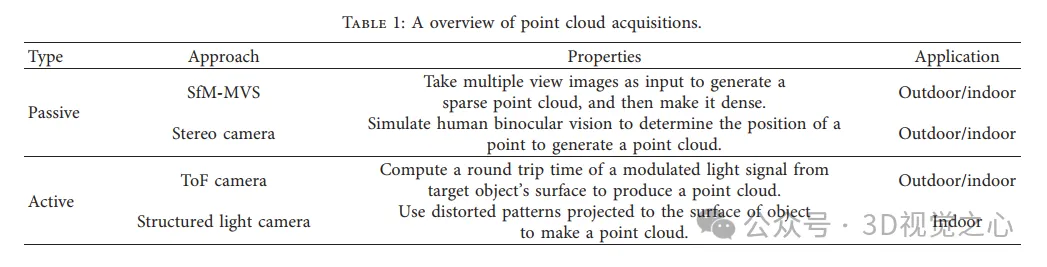
從SFM到MVS的密集重建。 (a)SFM。 (b)SfM產生的點雲範例。 (c)PMVS演算法流程圖,一種基於patch的多視角立體演算法。 (d)PMVS產生的密集點雲範例。
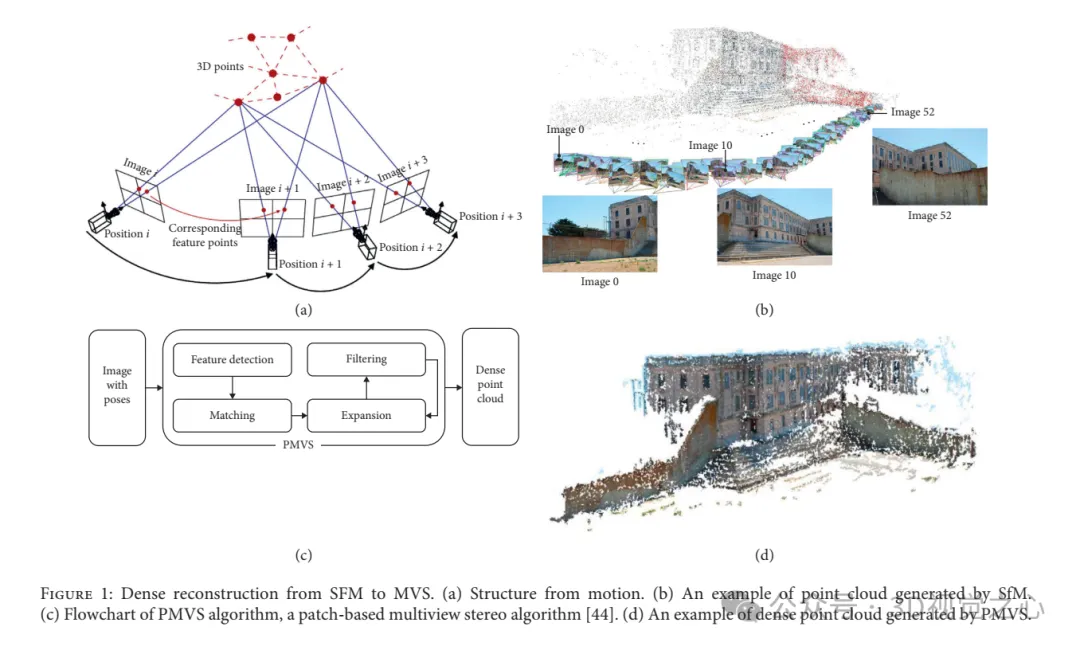
結構光重建方法:
#剛性配準與非剛性配準
在一個環境中,變換可以分解為旋轉和平移,在適當的剛性變換後,一個點雲被映射到另一點雲,同時保持相同的形狀和大小。
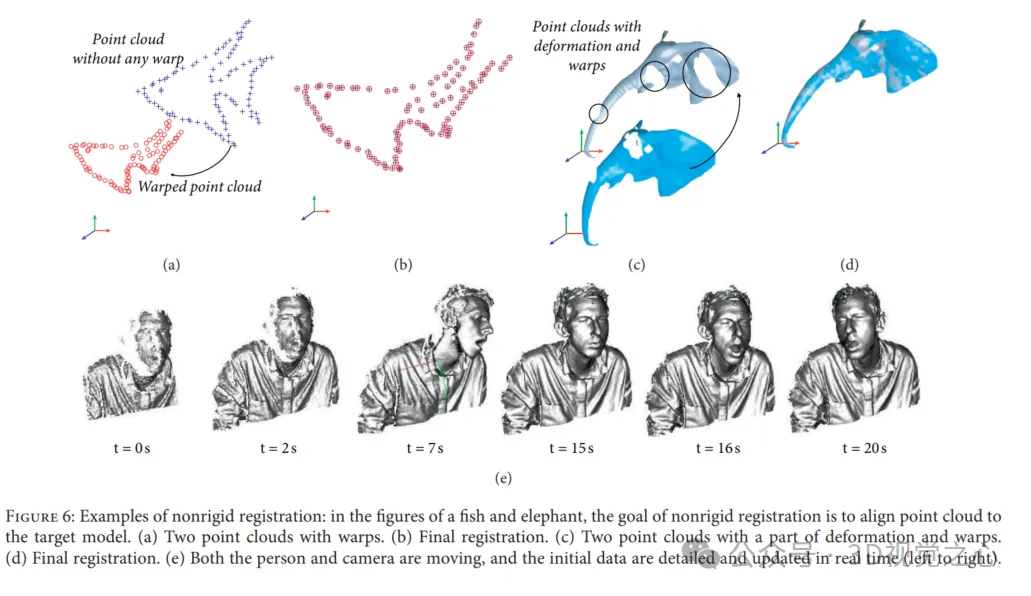
在非剛性配準中,建立非剛性變換以將掃描資料wrap到目標點雲。非剛性變換包含反射、旋轉、縮放和平移,而不是剛性配準僅包含平移和旋轉。非剛性配準的使用主要有兩個原因:(1) 資料收集的非線性和校準誤差會導致剛性物體掃描的低頻扭曲;(2) 對隨著時間改變其形狀和移動場景或目標執行配準。
剛性配準的範例:(a)兩個點雲:讀取點雲(綠色)和參考點雲(紅色);不使用(b)和使用(c)剛性配準演算法的情況下,點雲融合到公共座標系中。
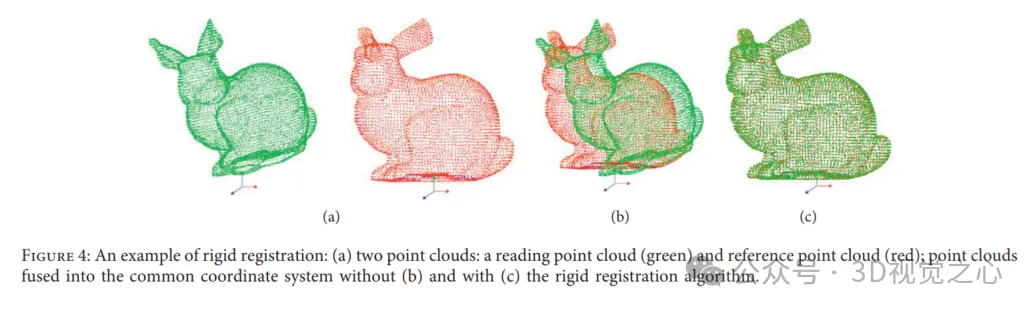

然而,點雲配準的效能被Variant Overlap、雜訊和異常值、高運算成本、配準成功的各種指標受限。
配準的方法有哪些?
在過去的幾十年裡,人們提出了越來越多的點雲配準方法,從經典的ICP演算法到與深度學習技術相結合的解決方案。
1)ICP方案
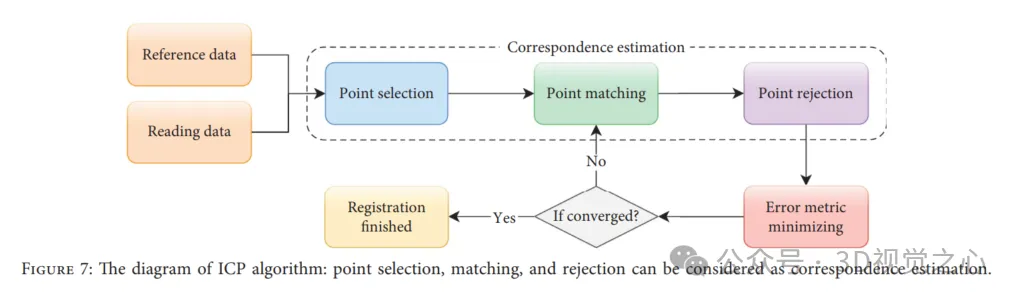
ICP演算法是一種迭代演算法,可在理想條件下確保配準的準確性、收斂速度和穩定性。從某種意義上說,ICP可以被視為期望最大化(EM)問題,因此它基於對應關係計算和更新新的變換,然後應用於讀取數據,直到誤差度量收斂。然而,這並不能保證ICP達到全域最優,ICP演算法可以大致分為四個步驟:如下圖所示,點選擇、點匹配、點拒絕和誤差度量最小化。

2)基於特徵的方法
正如我們在基於ICP的演算法中所看到的,在變換估計之前,建立對應關係是至關重要的。如果我們獲得描述兩個點雲之間正確關係的適當對應關係,則可以保證最終結果。因此,我們可以在掃描目標上貼上地標,或者在後處理中手動拾取等效點對,以計算感興趣點(拾取點)的變換,這種變換最終可以應用於讀取點雲。如圖12(c)所示,點雲載入在同一座標系中,並繪製成不同的顏色。圖12(a)和12(b)顯示了在不同視點捕獲的兩個點雲,分別從參考資料和讀取資料中選擇點對,配準結果如圖12(d)所示。然而,這些方法對不能附著地標的測量對象既不友好,也不能應用於需要自動配準的應用。同時,為了最小化對應關係的搜尋空間,並避免在基於ICP的演算法中假設初始變換,引入了基於特徵的配準,其中提取了研究人員設計的關鍵點。通常,關鍵點檢測和對應關係建立是此方法的主要步驟。

關鍵點擷取的常用方法包括PFH、SHOT等,設計一種演算法來移除異常值和有效地基於inliers的估計變換同樣很重要。
3)基於學習的方法
在使用點雲作為輸入的應用程式中,估計特徵描述符的傳統策略在很大程度上依賴點雲中目標的獨特幾何特性。然而,現實世界的數據往往因目標而異,可能包含平面、異常值和雜訊。此外,去除的失配通常包含有用的信息,可以用於學習。基於學習的技術可以適用於對語義資訊進行編碼,並且可以在特定任務中推廣。大多數與機器學習技術整合的配準策略比經典方法更快、更穩健,並靈活地擴展到其他任務,如物體姿勢估計和物體分類。同樣,基於學習的點雲配準的一個關鍵挑戰是如何提取對點雲的空間變化不變、對噪音和異常值更具穩健性的特徵。
以學習為基礎的方法代表作為:PointNet 、PointNet 、PCRNet 、Deep Global Registration 、Deep Closest Point、Partial Registration Network 、Robust Point Matching 、PointNetLK 、3DRegNet。
4)具有機率密度函數的方法
基於機率密度函數(PDF)的點雲配準,使得使用統計模型進行配準是一個研究得很好的問題,該方法的關鍵思想是用特定的機率密度函數表示數據,如高斯混合模型(GMM)和常態分佈(ND)。配準任務被重新表述為對齊兩個相應分佈的問題,然後是測量和最小化它們之間的統計差異的目標函數。同時,由於PDF的表示,點雲可以被視為一個分佈,而不是許多單獨的點,因此它避免了對應關係的估計,並且具有良好的抗噪聲性能,但通常比基於ICP的方法慢。
5)其它方法
Fast Global Registration 。快速全域配準(FGR)為點雲配準提供了一種無需初始化的快速策略。具體來說,FGR對覆蓋的表面的候選匹配進行操作並且不執行對應關係更新或最近點查詢,該方法的特殊之處在於,可以直接透過在表面上密集定義的穩健目標的單一最佳化來產生聯合配準。然而,現有的解決點雲配準的方法通常在兩個點雲之間產生候選或多個對應關係,然後計算和更新全域結果。此外,在快速全域配準中,在最佳化中會立即建立對應關係,並且不會在以下步驟中再次進行估計。因此,避免了昂貴的最近鄰查找,以保持低的計算成本。結果,迭代步驟中用於每個對應關係的線性處理和用於姿態估計的線性系統是有效的。 FGR在多個資料集上進行評估,如UWA基準和Stanford Bunny,與點對點和點頂線的ICP以及Go ICP等ICP變體進行比較。實驗顯示FGR在存在噪音的情況下表現出色!
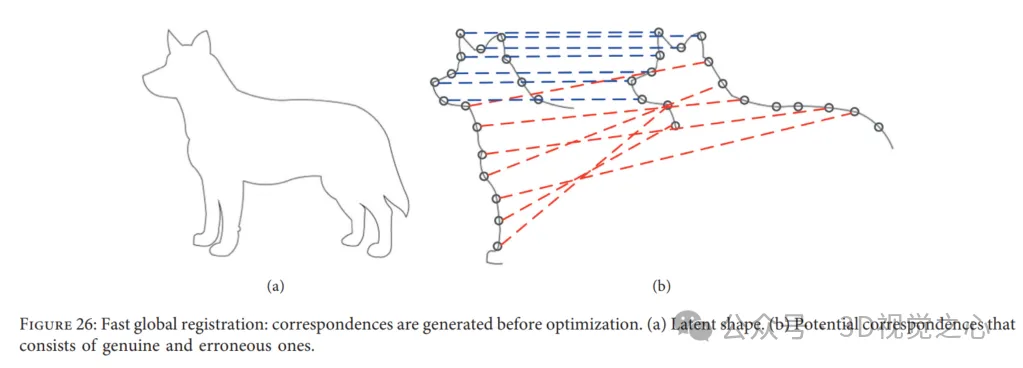
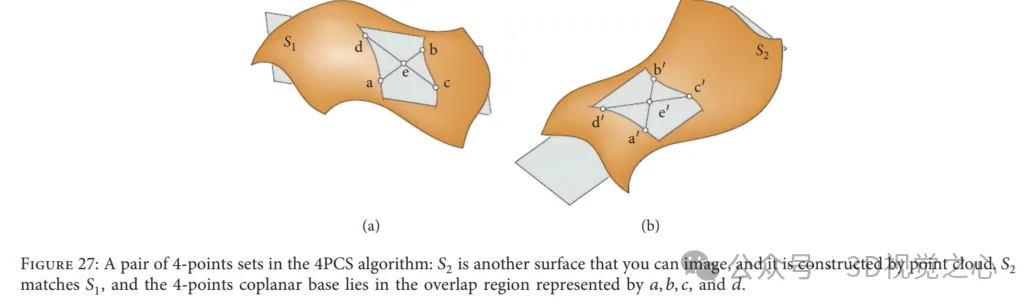
Four-point congruent set algorithm: 4-point congruent set (4PCS) provides an initial transformation for reading data without requiring starting position assumptions. Typically, a rigid registration transformation between two point clouds can be uniquely defined by a pair of triples, one from the reference data and the other from the read data. However, in this method, it looks for special 4-points bases by searching in a small potential set, i.e. 4 coplanar congruent points in each point cloud, as shown in Figure 27. Solving the optimal rigid transformation in the largest set of common points (LCP) problem. This algorithm achieves close performance when the overlap of paired point clouds is low and outliers are present. In order to adapt to different applications, many researchers have introduced more important works related to the classic 4PCS solution.
The above is the detailed content of Point cloud registration is inescapable for 3D vision! Understand all mainstream solutions and challenges in one article. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 Learn about 3D Fluent emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
Learn about 3D Fluent emojis in Microsoft Teams
Apr 24, 2023 pm 10:28 PM
You must remember, especially if you are a Teams user, that Microsoft added a new batch of 3DFluent emojis to its work-focused video conferencing app. After Microsoft announced 3D emojis for Teams and Windows last year, the process has actually seen more than 1,800 existing emojis updated for the platform. This big idea and the launch of the 3DFluent emoji update for Teams was first promoted via an official blog post. Latest Teams update brings FluentEmojis to the app Microsoft says the updated 1,800 emojis will be available to us every day
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Explicitly supervise the BEVFormer structure to improve long-tail detection performance
Mar 26, 2024 pm 12:41 PM
Written above & the author’s personal understanding: At present, in the entire autonomous driving system, the perception module plays a vital role. The autonomous vehicle driving on the road can only obtain accurate perception results through the perception module. The downstream regulation and control module in the autonomous driving system makes timely and correct judgments and behavioral decisions. Currently, cars with autonomous driving functions are usually equipped with a variety of data information sensors including surround-view camera sensors, lidar sensors, and millimeter-wave radar sensors to collect information in different modalities to achieve accurate perception tasks. The BEV perception algorithm based on pure vision is favored by the industry because of its low hardware cost and easy deployment, and its output results can be easily applied to various downstream tasks.
 What is NeRF? Is NeRF-based 3D reconstruction voxel-based?
Oct 16, 2023 am 11:33 AM
What is NeRF? Is NeRF-based 3D reconstruction voxel-based?
Oct 16, 2023 am 11:33 AM
1 Introduction Neural Radiation Fields (NeRF) are a fairly new paradigm in the field of deep learning and computer vision. This technology was introduced in the ECCV2020 paper "NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis" (which won the Best Paper Award) and has since become extremely popular, with nearly 800 citations to date [1 ]. The approach marks a sea change in the traditional way machine learning processes 3D data. Neural radiation field scene representation and differentiable rendering process: composite images by sampling 5D coordinates (position and viewing direction) along camera rays; feed these positions into an MLP to produce color and volumetric densities; and composite these values using volumetric rendering techniques image; the rendering function is differentiable, so it can be passed
 Get a virtual 3D wife in 30 seconds with a single card! Text to 3D generates a high-precision digital human with clear pore details, seamlessly connecting with Maya, Unity and other production tools
May 23, 2023 pm 02:34 PM
Get a virtual 3D wife in 30 seconds with a single card! Text to 3D generates a high-precision digital human with clear pore details, seamlessly connecting with Maya, Unity and other production tools
May 23, 2023 pm 02:34 PM
ChatGPT has injected a dose of chicken blood into the AI industry, and everything that was once unthinkable has become basic practice today. Text-to-3D, which continues to advance, is regarded as the next hotspot in the AIGC field after Diffusion (images) and GPT (text), and has received unprecedented attention. No, a product called ChatAvatar has been put into low-key public beta, quickly garnering over 700,000 views and attention, and was featured on Spacesoftheweek. △ChatAvatar will also support Imageto3D technology that generates 3D stylized characters from AI-generated single-perspective/multi-perspective original paintings. The 3D model generated by the current beta version has received widespread attention.
 Paint 3D in Windows 11: Download, Installation, and Usage Guide
Apr 26, 2023 am 11:28 AM
Paint 3D in Windows 11: Download, Installation, and Usage Guide
Apr 26, 2023 am 11:28 AM
When the gossip started spreading that the new Windows 11 was in development, every Microsoft user was curious about how the new operating system would look like and what it would bring. After speculation, Windows 11 is here. The operating system comes with new design and functional changes. In addition to some additions, it comes with feature deprecations and removals. One of the features that doesn't exist in Windows 11 is Paint3D. While it still offers classic Paint, which is good for drawers, doodlers, and doodlers, it abandons Paint3D, which offers extra features ideal for 3D creators. If you are looking for some extra features, we recommend Autodesk Maya as the best 3D design software. like
