

关于对sql2000查询结果进行相关度排序的测试_MySQL

sql2000的查询结果进行相关度排序,听起来好象很吸引人,不过真的是可以实现的。
上午上网看到了一篇利用微软index server来做全文查询的文章(这个以前也看到过,在计算机管理中也自带了这样一个查询功能)
我的IIS默认web服务器在g:/wwwroot下其中有10万多的html文档
测试:strSearch = "SELECT DocTitle, Path, FileName, Characterization, Size,write,RANK" & _
" FROM SCOPE()" & _
" WHERE CONTAINS ('" & Request.Form("txtSearchFor") & "') ORDER BY RANK desc" 还进行了相关度的排序,我没有做时间的具体开销
的计算,不过给人的感觉还可以接受,在翻页的时候就非常快了。不过最大的缺点好象就是只能索引静态页面了。
下午我把以前的一个50多万条记录(主要是歌曲名和歌手名)的数据库在sql2000做了索引,晚上就可以开始测试了。
测试一: "select top 26 * from song1 where contains(songtitle,'爱')",对结果没有进行任何的处理,只是按照ID的升续排列
时间开销基本上维持在0.016s,速度是很让人满意的,至少感觉不到慢。
测试二:利用rank值进行了相关度的排序,"order by rank desc" or "order by rank asc",查询结果在排序的质量上让人满意,都比较
准确的,不管是查询时使用 or 或者and进行多关键字的排序都还可以的,不过时间的开销让我受不了,居然在6s到8s之间,
而且cpu也占用比较高
我看到网上其他的搜索的相关度排序都比较快的,开源的Lucene我没有研究过,因为我不懂java。
不过我想如果在索引的时候对每个关键字进行相关度的运算查询起来应该不会慢的啊,这个我也感到郁闷。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

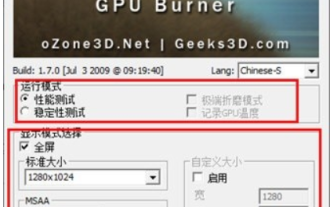 What do you think of furmark? - How is furmark considered qualified?
Mar 19, 2024 am 09:25 AM
What do you think of furmark? - How is furmark considered qualified?
Mar 19, 2024 am 09:25 AM
What do you think of furmark? 1. Set the "Run Mode" and "Display Mode" in the main interface, and also adjust the "Test Mode" and click the "Start" button. 2. After waiting for a while, you will see the test results, including various parameters of the graphics card. How is furmark qualified? 1. Use a furmark baking machine and check the results for about half an hour. It basically hovers around 85 degrees, with a peak value of 87 degrees and room temperature of 19 degrees. Large chassis, 5 chassis fan ports, two on the front, two on the top, and one on the rear, but only one fan is installed. All accessories are not overclocked. 2. Under normal circumstances, the normal temperature of the graphics card should be between "30-85℃". 3. Even in summer when the ambient temperature is too high, the normal temperature is "50-85℃
 12306 How to check historical ticket purchase records How to check historical ticket purchase records
Mar 28, 2024 pm 03:11 PM
12306 How to check historical ticket purchase records How to check historical ticket purchase records
Mar 28, 2024 pm 03:11 PM
Download the latest version of 12306 ticket booking app. It is a travel ticket purchasing software that everyone is very satisfied with. It is very convenient to go wherever you want. There are many ticket sources provided in the software. You only need to pass real-name authentication to purchase tickets online. All users You can easily buy travel tickets and air tickets and enjoy different discounts. You can also start booking reservations in advance to grab tickets. You can book hotels or special car transfers. With it, you can go where you want to go and buy tickets with one click. Traveling is simpler and more convenient, making everyone's travel experience more comfortable. Now the editor details it online Provides 12306 users with a way to view historical ticket purchase records. 1. Open Railway 12306, click My in the lower right corner, and click My Order 2. Click Paid on the order page. 3. On the paid page
 How to check your academic qualifications on Xuexin.com
Mar 28, 2024 pm 04:31 PM
How to check your academic qualifications on Xuexin.com
Mar 28, 2024 pm 04:31 PM
How to check my academic qualifications on Xuexin.com? You can check your academic qualifications on Xuexin.com, but many users don’t know how to check their academic qualifications on Xuexin.com. Next, the editor brings you a graphic tutorial on how to check your academic qualifications on Xuexin.com. Interested users come and take a look! Xuexin.com usage tutorial: How to check your academic qualifications on Xuexin.com 1. Xuexin.com entrance: https://www.chsi.com.cn/ 2. Website query: Step 1: Click on the Xuexin.com address above to enter the homepage Click [Education Query]; Step 2: On the latest webpage, click [Query] as shown by the arrow in the figure below; Step 3: Then click [Login Academic Credit File] on the new page; Step 4: On the login page Enter the information and click [Login];
 Join a new Xianxia adventure! 'Zhu Xian 2' 'Wuwei Test' pre-download is now available
Apr 22, 2024 pm 12:50 PM
Join a new Xianxia adventure! 'Zhu Xian 2' 'Wuwei Test' pre-download is now available
Apr 22, 2024 pm 12:50 PM
The "Inaction Test" of the new fantasy fairy MMORPG "Zhu Xian 2" will be launched on April 23. What kind of new fairy adventure story will happen in Zhu Xian Continent thousands of years after the original work? The Six Realm Immortal World, a full-time immortal academy, a free immortal life, and all kinds of fun in the immortal world are waiting for the immortal friends to explore in person! The "Wuwei Test" pre-download is now open. Fairy friends can go to the official website to download. You cannot log in to the game server before the server is launched. The activation code can be used after the pre-download and installation is completed. "Zhu Xian 2" "Inaction Test" opening hours: April 23 10:00 - May 6 23:59 The new fairy adventure chapter of the orthodox sequel to Zhu Xian "Zhu Xian 2" is based on the "Zhu Xian" novel as a blueprint. Based on the world view of the original work, the game background is set
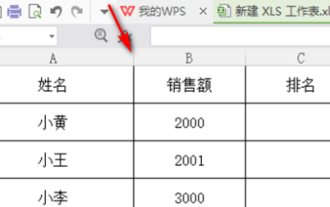 How to sort WPS scores
Mar 20, 2024 am 11:28 AM
How to sort WPS scores
Mar 20, 2024 am 11:28 AM
In our work, we often use wps software. There are many ways to process data in wps software, and the functions are also very powerful. We often use functions to find averages, summaries, etc. It can be said that as long as The methods that can be used for statistical data have been prepared for everyone in the WPS software library. Below we will introduce the steps of how to sort the scores in WPS. After reading this, you can learn from the experience. 1. First open the table that needs to be ranked. As shown below. 2. Then enter the formula =rank(B2, B2: B5, 0), and be sure to enter 0. As shown below. 3. After entering the formula, press the F4 key on the computer keyboard. This step is to change the relative reference into an absolute reference.
 Comparison of similarities and differences between MySQL and PL/SQL
Mar 16, 2024 am 11:15 AM
Comparison of similarities and differences between MySQL and PL/SQL
Mar 16, 2024 am 11:15 AM
MySQL and PL/SQL are two different database management systems, representing the characteristics of relational databases and procedural languages respectively. This article will compare the similarities and differences between MySQL and PL/SQL, with specific code examples to illustrate. MySQL is a popular relational database management system that uses Structured Query Language (SQL) to manage and operate databases. PL/SQL is a procedural language unique to Oracle database and is used to write database objects such as stored procedures, triggers and functions. same
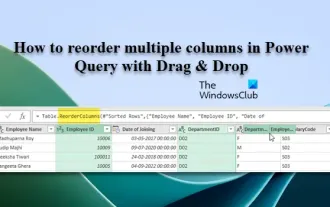 How to reorder multiple columns in Power Query via drag and drop
Mar 14, 2024 am 10:55 AM
How to reorder multiple columns in Power Query via drag and drop
Mar 14, 2024 am 10:55 AM
In this article, we will show you how to reorder multiple columns in PowerQuery by dragging and dropping. Often, when importing data from various sources, columns may not be in the desired order. Reordering columns not only allows you to arrange them in a logical order that suits your analysis or reporting needs, it also improves the readability of your data and speeds up tasks such as filtering, sorting, and performing calculations. How to rearrange multiple columns in Excel? There are many ways to rearrange columns in Excel. You can simply select the column header and drag it to the desired location. However, this approach can become cumbersome when dealing with large tables with many columns. To rearrange columns more efficiently, you can use the enhanced query editor. Enhancing the query
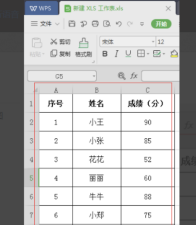 How to sort WPS tables to facilitate data statistics
Mar 20, 2024 pm 04:31 PM
How to sort WPS tables to facilitate data statistics
Mar 20, 2024 pm 04:31 PM
WPS is a very complete office software, including text editing, data tables, PPT presentations, PDF formats, flow charts and other functions. Among them, the ones we use most are text, tables, and demonstrations, and they are also the ones we are most familiar with. In our study work, we sometimes use WPS tables to make some data statistics. For example, the school will count the scores of each student. If we have to manually sort the scores of so many students, it will be really a headache. In fact, we don’t have to worry, because our WPS table has a sorting function to solve this problem for us. Next, let’s learn how to sort WPS together. Method steps: Step 1: First we need to open the WPS table that needs to be sorted
