
 Technology peripherals
AI
APISR, a two-dimensional dedicated super-resolution AI model: available online, selected by CVPR
Technology peripherals
AI
APISR, a two-dimensional dedicated super-resolution AI model: available online, selected by CVPR
APISR, a two-dimensional dedicated super-resolution AI model: available online, selected by CVPR

Animation works such as "Dragon Ball", "Pokémon", "Neon Genesis Evangelion" and other animations that were aired in the last century are part of many people's childhood memories. They have brought us full of passion, friendship and dreams. visual journey. At some point, we will suddenly have the urge to revisit these childhood memories, but we may regretfully find that the recognition rate of these childhood memories is very low, and it is impossible to create a good visual experience on a widescreen TV, so that it hinders us. Share these childhood memories with children growing up in a digital world with HD resolution.
For this kind of vicious competition (and potential market), one way is to have animation companies produce remakes. This task will be costly in both human and financial terms, but may be worth more than ignoring the problem and losing market share.
The performance of multi-modal artificial intelligence is becoming increasingly powerful, and using AI-based super-resolution technology to improve animation resolution has become a direction worth exploring. This technology can reconstruct high-resolution images from a small number of low-resolution images, making animation images clearer and more detailed. This method uses depth by training a large number of sample data. Recently, a joint team from the University of Michigan, Yale University and Zhejiang University created a set of tools for animation super-resolution tasks by analyzing the animation production process. A very practical new method. This includes datasets, models, and some improvements. This research has been accepted into the CVPR 2024 conference. The team also open sourced the relevant code and launched a trial model on Huggingface.

- Paper title: APISR: Anime Production Inspired Real-World Anime Super-Resolution
- Paper address :https://arxiv.org/pdf/2403.01598.pdf
- Code address: https://github.com/Kiteretsu77/APISR
- Trial model: https://huggingface.co/spaces/HikariDawn/APISR
- The picture below is the result of this site’s attempt using the screenshot of the first episode of "Dragon Ball". The effect is visible to the naked eye. Visible good.
 In addition, some people have tried to use this technology to improve video resolution, and the results are great:
In addition, some people have tried to use this technology to improve video resolution, and the results are great:
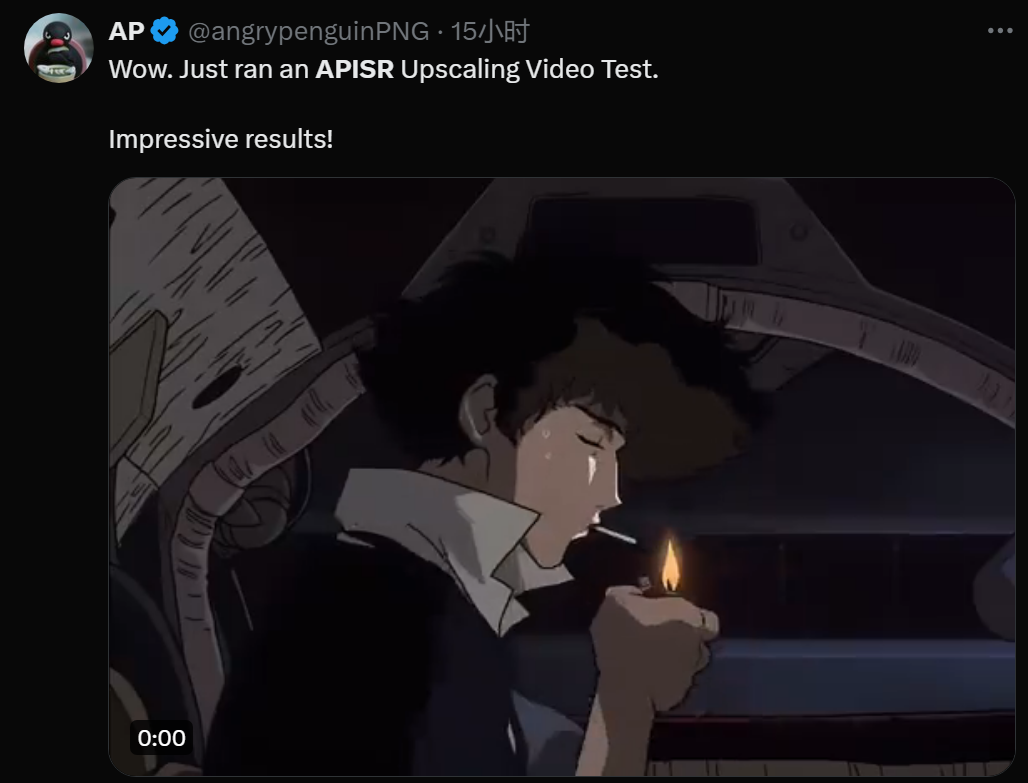
In order to understand the innovation of this new method, let’s first take a look at how animation is generally produced.
First, a human sketches on paper, which is then colored and enhanced through computer generated image (CGI) processing. These processed sketches are then connected to create a video.
However, because the drawing process is very labor-intensive and the human eye is not sensitive to motion, when compositing videos, the industry standard practice is to reuse a single image for multiple consecutive frames.
By analyzing this process, the joint team couldn’t help but wonder whether it was necessary to use video models and video datasets to train animation super-resolution models: it is entirely possible to perform super-resolution on images and then concatenate these images. Get up!
So they decided to use image-based methods and data sets to create a unified super-resolution and restoration framework suitable for images and videos.
New proposed methodImage super-resolution (API SR) data set for animation production
The team The API SR data set is proposed, and its collection and organization method is briefly introduced here. This method takes advantage of the characteristics of animation videos (see Figure 2) and can select the least compressed and most informative frames from the video.
 I-frame based image collection: Video compression involves a trade-off between video quality and data size. There are many video compression standards now, each with its own complex engineering system, but they all have a similar backbone design.
I-frame based image collection: Video compression involves a trade-off between video quality and data size. There are many video compression standards now, each with its own complex engineering system, but they all have a similar backbone design.
These characteristics cause the compression quality of each frame to be different. The video compression process designates a number of key frames (i.e., I-frames) as individual compression units. In practice, the I-frame is the first frame when the scene changes. These I-frames can occupy a large amount of data. Non-I frames (i.e. P frames and B frames) have higher compression rates, and they need to use the I frame as a reference during the compression process to introduce changes over time. As shown in Figure 3a, in the animation videos collected by the team, the data size of I frames is generally higher than that of non-I frames, and the quality of I frames is indeed higher. Therefore, the team used the video processing tool ffmpeg to extract all I-frames from the video source and use them as an initial data pool.
画像の複雑さに基づく選択: チームは、アニメーションにより適した指標である画像複雑性評価 (ICA) に基づいて初期 I フレーム プールをスクリーニングしました (図 4 を参照)。

API データセット: チームは 562 個の高品質のアニメ ビデオを手動で収集しました。上記の 2 つの手順に基づいて、各ビデオから最高スコアの 10 フレームが収集されました。その後、不適切な画像を除去するためにいくつかのフィルタリングが実行され、最終的に 3740 枚の高品質画像を含むデータセットが取得されました。図 5 にいくつかの画像の例を示します。さらに、図 3b からは、画像の複雑さに関する API データ セットの利点もわかります。

元の 720P 解像度に戻る: アニメーション制作プロセスを調査すると、ほとんどのアニメーション制作で 720P 形式が使用されていることがわかります (つまり、画像の高さは 720 ピクセルです) )。しかし、現実のシナリオでは、マルチメディア形式を標準化するために、アニメが誤って 1080P または他の形式にアップスケールされることがよくあります。チームは実験的に、すべてのアニメ画像のサイズをネイティブ 720P に変更すると、クリエイターが思い描いた機能密度が提供され、より緻密なアニメ手描きの線と CGI 情報が得られることを発見しました。
#アニメーション用の実用的な劣化モデル
現実世界の超解像タスクでは、劣化モデルの設計が非常に重要です。研究チームは、高次の劣化モデルと最近の画像ベースのビデオ圧縮回復モデルに基づいて、歪んだ手描きの線やさまざまな圧縮アーティファクトを復元し、劣化モデルの表現を強化できる 2 つの改善を提案しました。図 6a は、この劣化モデルを示しています。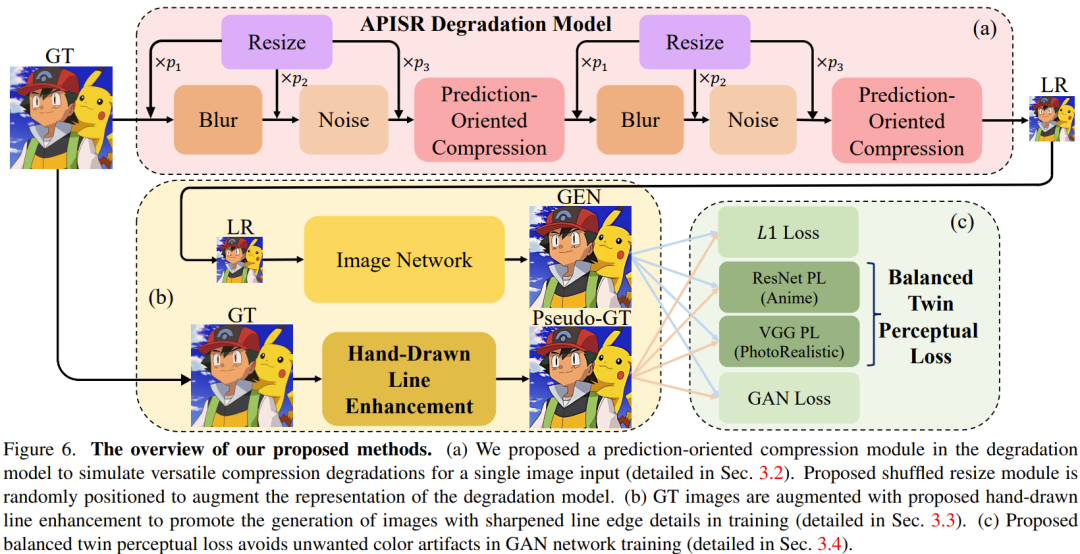

アニメーション用に手描きの線を強化する
チームの選択は、鮮明になった手描きの線情報を直接抽出し、それをグラウンド トゥルース (GT/ground) と比較することです。 -truth ) を融合し、擬似 GT を形成します。この特別にターゲットを絞った強化された擬似 GT を超解像度トレーニング プロセスに導入することで、追加のニューラル ネットワーク モジュールや別個の後処理ネットワークを導入することなく、ネットワークは鮮明な手描きの線を生成できます。 手描きの線をより適切に抽出するために、チームは、GT のシャープなエッジ マップを抽出できる、ピクセル単位のガウス カーネルに基づくスケッチ抽出アルゴリズムである XDoG を使用しました。 ただし、XDoG エッジ マップには、異常値のピクセルや破線表現を含む過度のノイズが発生します。この問題を解決するために、チームは、カスタム設計のパッシブ拡張法と組み合わせた外れ値フィルタリング手法を提案しました。このようにして、手描きの線のより一貫性のある、乱れのない表現が得られます。 チームは、前処理された GT を過度にシャープ化すると、手描きの線のエッジが他の無関係なシャドウ エッジの詳細よりも目立つようになり、外れ値フィルターがそれらを区別しやすくなる可能性があることを実験的に発見しました。これを行うために、チームはまず GT 上で 3 ラウンドのデシャープニング マスキング操作を実行することを提案しました。図 8 は、このプロセスを簡単に示しています。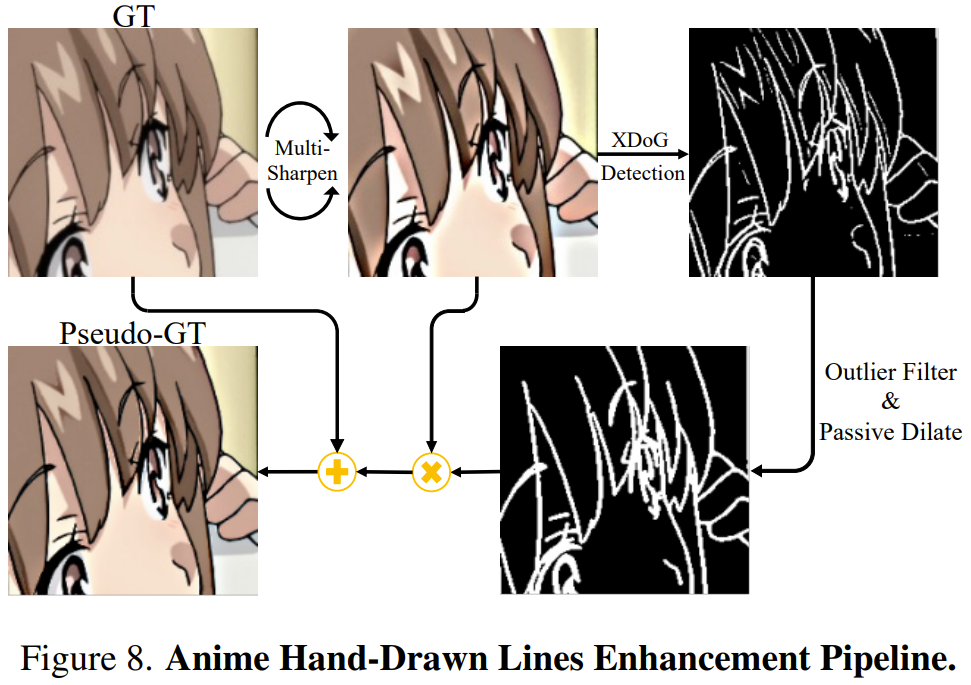
アニメーション向けのバランスのとれたデュアル知覚損失
主にトレーニング内データが原因で、不要なカラー アーティファクトの問題もあります。ジェネレーターと知覚損失の間のドメインの不一致。この問題を解決し、以前の方法の欠点を補うために、チームのアプローチは、Danbooru データ セットのアニメーション ターゲット分類タスクでトレーニングされた事前トレーニング済み ResNet を使用することでした。 Danbooru データセットは、大規模で豊富な注釈を含むアニメ イラスト データベースです。この事前トレーニング済みネットワークは VGG ではなく ResNet50 であるため、チームは同様の中間層の比較も提案しました。
ただし、ResNet ベースの損失のみを使用する場合は、視覚的な結果が不十分になる可能性があります。これは、Danbooru データセットに固有のバイアスが原因で発生します。このデータセット内のほとんどの画像は人間の顔か、比較的単純なものです。 .イラスト。したがって、チームは検討を加え、トレーニング中の ResNet ベースの知覚損失をガイドする補助として現実世界の特徴を使用することを決定しました。この方法により、視覚的に心地よい画像が得られると同時に、不要な色の問題も解決されます。
実験
実装の詳細
実験では、チームは新しく提案された API データ セットを画像ネットワークとして使用しました。トレーニングデータセット。画像ネットワークに関しては、GRL の小型バージョンが最も近い畳み込みアップサンプリング モジュールとともに使用されます。
詳細とパラメータについては、元の論文を参照してください。
現在の最良の方法との比較
チームは、新しく提案された APISR を、Real-ESRGAN、BSRGAN、RealBasicVSR、AnimeSR などの他の高度な方法と定量的および定性的に比較しました。そしてVQD-SR。
定量的比較
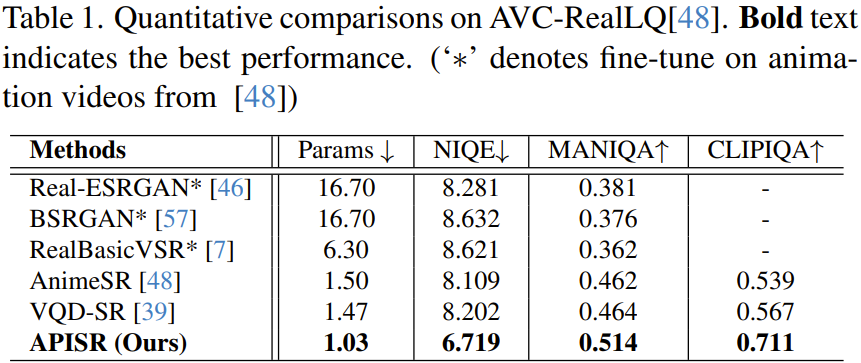
表 1 に示すように、新しいモデルのネットワーク サイズは最小であり、パラメーターは 103 万個のみですが、すべての指標でのパフォーマンスは他のすべてを上回っています。 。 方法。
チームは、予測指向の圧縮モデルの役割を特に強調しました。
さらに、新しい方法では、AnimeSR と VQDSR のトレーニング サンプルの複雑さがそれぞれ 13.3% と 25% の場合にのみこのような結果が得られることを指摘しておく必要があります。これは主に、データセットの並べ替えプロセスに画像の複雑さ評価が導入されたことによるもので、情報が豊富な画像を選択することでアニメーション画像表現の学習効果を向上させることができます。さらに、新たに設計された明示的な劣化モデルにより、劣化モデル側のトレーニングは不要です。
定性的比較
図 10 に示すように、APISR によって得られる視覚的な品質は、他の方法よりもはるかに優れています。

チームはまた、新しいデータセット、劣化モデル、損失設計の有効性を検証するためにアブレーション研究も実施しました。詳細については元の論文を参照してください。
The above is the detailed content of APISR, a two-dimensional dedicated super-resolution AI model: available online, selected by CVPR. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Introduction In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the basic model for many downstream tasks, current MLLM consists of the well-known Transformer network, which
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Show the causal chain to LLM and it learns the axioms. AI is already helping mathematicians and scientists conduct research. For example, the famous mathematician Terence Tao has repeatedly shared his research and exploration experience with the help of AI tools such as GPT. For AI to compete in these fields, strong and reliable causal reasoning capabilities are essential. The research to be introduced in this article found that a Transformer model trained on the demonstration of the causal transitivity axiom on small graphs can generalize to the transitive axiom on large graphs. In other words, if the Transformer learns to perform simple causal reasoning, it may be used for more complex causal reasoning. The axiomatic training framework proposed by the team is a new paradigm for learning causal reasoning based on passive data, with only demonstrations
