

Why do large language models use SwiGLU as activation function?

If you have been paying attention to the architecture of large language models, you may have seen the term "SwiGLU" in the latest models and research papers. SwiGLU can be said to be the most commonly used activation function in large language models. We will introduce it in detail in this article. SwiGLU is actually an activation function proposed by Google in 2020, which combines the characteristics of SWISH and GLU. The full Chinese name of SwiGLU is "bidirectional gated linear unit". It optimizes and combines two activation functions, SWISH and GLU, to improve the nonlinear expression ability of the model. SWISH is a very common activation function that is widely used in large language models, while GLU performs well in natural language processing tasks. The advantage of SwiGLU is that it can obtain the smoothing characteristics of SWISH and the gating characteristics of GLU at the same time, thereby making the nonlinear expression of the model more

us Let’s introduce them one by one:
Swish
Swish is a nonlinear activation function, defined as follows:
Swish(x) = x*sigmoid(ßx)
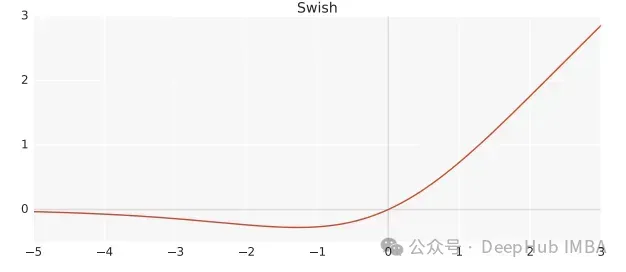
Among them, ß is a learnable parameter. Swish can be better than ReLU activation function as it gives smoother transitions which can lead to better optimization.
Gated Linear Unit
GLU (Gated Linear Unit) is defined as the component product of two linear transformations, one of which is activated by sigmoid .
GLU(x) = sigmoid(W1x+b)⊗(Vx+c)
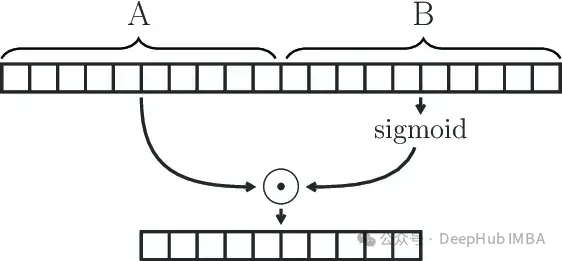
#The GLU module can effectively capture long-range dependencies in sequences while avoiding other gates such as LSTM and GRU There are some vanishing gradient problems related to the control mechanism.
SwiGLU
We have already said that SwiGLU is a combination of the two. It's a GLU, but instead of using sigmoid as the activation function, it uses swish with ß=1, so we end up with the following formula:
SwiGLU(x) = Swish(W1x+b)⊗(Vx+c)
We use The SwiGLU function constructs a feedforward network
FFNSwiGLU(x) = (Swish1(xW)⊗xV)W2
Simple implementation of Pytorch
If you look at the above mathematical principles for comparison It's boring and difficult to understand, so we'll explain it directly using the code below.
class SwiGLU(nn.Module): def __init__(self, w1, w2, w3) -> None:super().__init__()self.w1 = w1self.w2 = w2self.w3 = w3 def forward(self, x):x1 = F.linear(x, self.w1.weight)x2 = F.linear(x, self.w2.weight)hidden = F.silu(x1) * x2return F.linear(hidden, self.w3.weight)
The F.silu function used in our code is the same as swish when ß=1, so we use it directly.
As you can see from the code, there are 3 weights in our activation function that can be trained, which are the parameters from the GLU formula.
Comparison of the effect of SwiGLU
Comparing SwiGLU with other GLU variants, we can see that SwiGLU performs well during both pre-training periods Better.
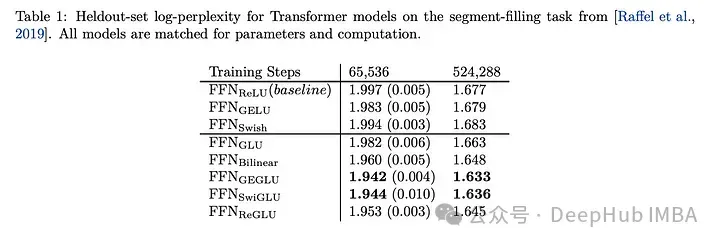
Downstream tasks
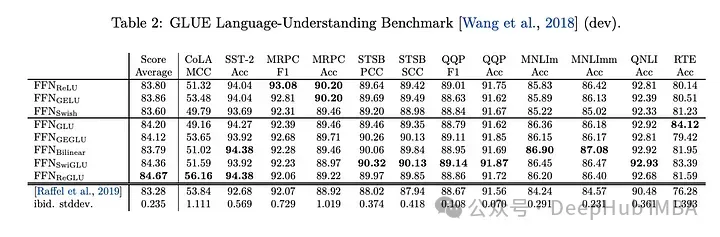
The effect is the best, So now llm, such as LLAMA, OLMO and PALM all use SwiGLU in their implementation. But why is SwiGLU better than the others?
The paper only gave the test results and did not explain the reasons. Instead, it said:
We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.
The author said that the alchemy was successful.
But now it is 2024 and we can forcefully explain it:
#1. Swish’s response to negative values is relatively small It overcomes the shortcoming of ReLU that the output on some neurons is always zero
2. The gating characteristics of GLU, which means that it can decide which information should pass and which information should pass through based on the input situation. Information should be filtered. This mechanism allows the network to learn useful representations more effectively and helps improve the generalization ability of the model. In large language models, this is particularly useful for processing long sequences of text with long-distance dependencies.
3. The parameters W1, W2, W3, b1, b2, b3 W1, W2, W3, b1, b2, b3 in SwiGLU can be learned through training, so that the model can be adapted to different tasks Dynamically adjusting these parameters with the data set enhances the flexibility and adaptability of the model.
4. The calculation efficiency is higher than some more complex activation functions (such as GELU), while still maintaining good performance. This is an important consideration for the training and inference of large-scale language models.
Choose SwiGLU as the activation function of the large language model, mainly because it combines the advantages of nonlinear capabilities, gating characteristics, gradient stability and learnable parameters. SwiGLU is widely adopted due to its excellent performance in handling complex semantic relationships and long dependency problems in language models, as well as maintaining training stability and computational efficiency.
Paper address
The above is the detailed content of Why do large language models use SwiGLU as activation function?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Why do large language models use SwiGLU as activation function?
Apr 08, 2024 pm 09:31 PM
Why do large language models use SwiGLU as activation function?
Apr 08, 2024 pm 09:31 PM
If you have been paying attention to the architecture of large language models, you may have seen the term "SwiGLU" in the latest models and research papers. SwiGLU can be said to be the most commonly used activation function in large language models. We will introduce it in detail in this article. SwiGLU is actually an activation function proposed by Google in 2020, which combines the characteristics of SWISH and GLU. The full Chinese name of SwiGLU is "bidirectional gated linear unit". It optimizes and combines two activation functions, SWISH and GLU, to improve the nonlinear expression ability of the model. SWISH is a very common activation function that is widely used in large language models, while GLU has shown good performance in natural language processing tasks.
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Visualize FAISS vector space and adjust RAG parameters to improve result accuracy
Mar 01, 2024 pm 09:16 PM
Visualize FAISS vector space and adjust RAG parameters to improve result accuracy
Mar 01, 2024 pm 09:16 PM
As the performance of open source large-scale language models continues to improve, performance in writing and analyzing code, recommendations, text summarization, and question-answering (QA) pairs has all improved. But when it comes to QA, LLM often falls short on issues related to untrained data, and many internal documents are kept within the company to ensure compliance, trade secrets, or privacy. When these documents are queried, LLM can hallucinate and produce irrelevant, fabricated, or inconsistent content. One possible technique to handle this challenge is Retrieval Augmented Generation (RAG). It involves the process of enhancing responses by referencing authoritative knowledge bases beyond the training data source to improve the quality and accuracy of the generation. The RAG system includes a retrieval system for retrieving relevant document fragments from the corpus
 Optimization of LLM using SPIN technology for self-game fine-tuning training
Jan 25, 2024 pm 12:21 PM
Optimization of LLM using SPIN technology for self-game fine-tuning training
Jan 25, 2024 pm 12:21 PM
2024 is a year of rapid development for large language models (LLM). In the training of LLM, alignment methods are an important technical means, including supervised fine-tuning (SFT) and reinforcement learning with human feedback that relies on human preferences (RLHF). These methods have played a crucial role in the development of LLM, but alignment methods require a large amount of manually annotated data. Faced with this challenge, fine-tuning has become a vibrant area of research, with researchers actively working to develop methods that can effectively exploit human data. Therefore, the development of alignment methods will promote further breakthroughs in LLM technology. The University of California recently conducted a study introducing a new technology called SPIN (SelfPlayfInetuNing). S
 Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models
Jan 14, 2024 pm 06:30 PM
Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models
Jan 14, 2024 pm 06:30 PM
Hallucinations are a common problem when working with large language models (LLMs). Although LLM can generate smooth and coherent text, the information it generates is often inaccurate or inconsistent. In order to prevent LLM from hallucinations, external knowledge sources, such as databases or knowledge graphs, can be used to provide factual information. In this way, LLM can rely on these reliable data sources, resulting in more accurate and reliable text content. Vector Database and Knowledge Graph Vector Database A vector database is a set of high-dimensional vectors that represent entities or concepts. They can be used to measure the similarity or correlation between different entities or concepts, calculated through their vector representations. A vector database can tell you, based on vector distance, that "Paris" and "France" are closer than "Paris" and
 Detailed explanation of GQA, the attention mechanism commonly used in large models, and Pytorch code implementation
Apr 03, 2024 pm 05:40 PM
Detailed explanation of GQA, the attention mechanism commonly used in large models, and Pytorch code implementation
Apr 03, 2024 pm 05:40 PM
GroupedQueryAttention is a multi-query attention method in large language models. Its goal is to achieve the quality of MHA while maintaining the speed of MQA. GroupedQueryAttention groups queries, and queries within each group share the same attention weight, which helps reduce computational complexity and increase inference speed. In this article, we will explain the idea of GQA and how to translate it into code. GQA is in the paper GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 RoSA: A new method for efficient fine-tuning of large model parameters
Jan 18, 2024 pm 05:27 PM
RoSA: A new method for efficient fine-tuning of large model parameters
Jan 18, 2024 pm 05:27 PM
As language models scale to unprecedented scale, comprehensive fine-tuning for downstream tasks becomes prohibitively expensive. In order to solve this problem, researchers began to pay attention to and adopt the PEFT method. The main idea of the PEFT method is to limit the scope of fine-tuning to a small set of parameters to reduce computational costs while still achieving state-of-the-art performance on natural language understanding tasks. In this way, researchers can save computing resources while maintaining high performance, bringing new research hotspots to the field of natural language processing. RoSA is a new PEFT technique that, through experiments on a set of benchmarks, is found to outperform previous low-rank adaptive (LoRA) and pure sparse fine-tuning methods using the same parameter budget. This article will go into depth
 LLMLingua: Integrate LlamaIndex, compress hints and provide efficient large language model inference services
Nov 27, 2023 pm 05:13 PM
LLMLingua: Integrate LlamaIndex, compress hints and provide efficient large language model inference services
Nov 27, 2023 pm 05:13 PM
The emergence of large language models (LLMs) has stimulated innovation in multiple fields. However, the increasing complexity of prompts, driven by strategies such as chain-of-thought (CoT) prompts and contextual learning (ICL), poses computational challenges. These lengthy prompts require significant resources for reasoning and therefore require efficient solutions. This article will introduce the integration of LLMLingua with the proprietary LlamaIndex to perform efficient reasoning. LLMLingua is a paper published by Microsoft researchers at EMNLP2023. LongLLMLingua is a method that enhances llm's ability to perceive key information in long context scenarios through fast compression. LLMLingua and llamindex
