
 Technology peripherals
AI
The open source model wins GPT-4 for the first time! Arena's latest battle report has sparked heated debate, Karpathy: This is the only list I trust
Technology peripherals
AI
The open source model wins GPT-4 for the first time! Arena's latest battle report has sparked heated debate, Karpathy: This is the only list I trust
The open source model wins GPT-4 for the first time! Arena's latest battle report has sparked heated debate, Karpathy: This is the only list I trust

An open source model that can beat GPT-4 has appeared!
The latest battle report of the large model arena:
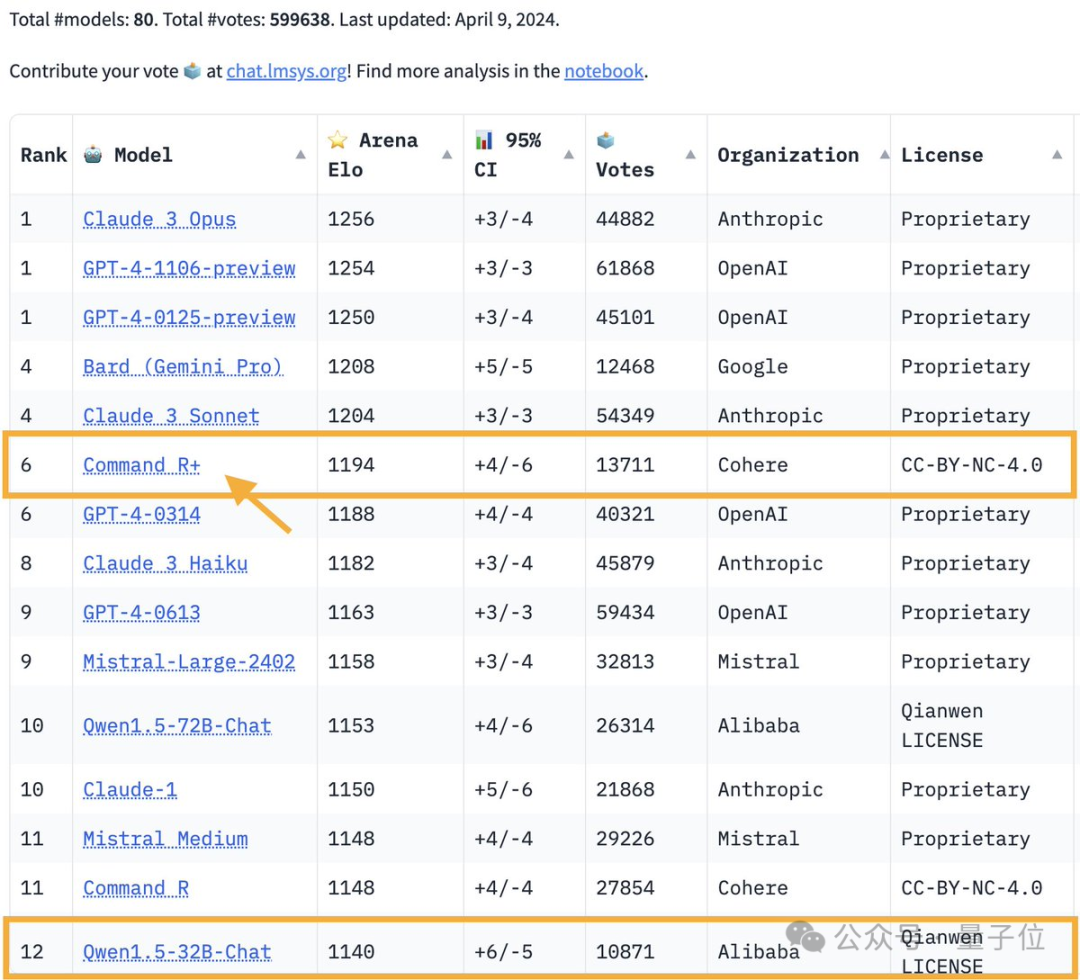
The 104 billion parameter open source model Command R climbed to 6th place, tying with GPT-4-0314 and surpassing GPT-4-0613.
 Picture
Picture
This is also the first open-weight model to beat GPT-4 in the large model arena.
The large model arena is one of the only test benchmarks that the master Karpathy trusts.
 Picture
Picture
Command R from AI unicorn Cohere. The co-founder and CEO of this large model startup is none other than Aidan Gomez, the youngest author of Transformer (referred to as the wheat reaper).
 Picture
Picture
As soon as this battle report came out, it set off another wave of heated discussions in the large model community.
The reason why everyone is excited is simple: the basic large model has been rolled out for a whole year. Unexpectedly, the pattern will continue to develop and change in 2024.
HuggingFace co-founder Thomas Wolf said:
The situation in the large model arena has changed dramatically recently:
Anthropic’s Claude 3 opus is in the closed source model Take the lead among them.
Cohere's Command R has become the strongest among the open source models.
Unexpectedly, in 2024, the artificial intelligence team will develop so fast on both open source and closed source routes.
 Picture
Picture
In addition, Cohere Machine Learning Director Nils Reimers also pointed out something worthy of attention:
The biggest feature of Command R is The built-in RAG (Retrieval Enhanced Generation) has been fully optimized, but in the large model arena, plug-in capabilities such as RAG were not included in the test.
 Picture
Picture
RAG optimization model ascends to the throne of open source
In Cohere’s official positioning, Command R is a “RAG optimization model” .
That is to say, this large model with 104 billion parameters has been deeply optimized for retrieval enhancement generation technology to reduce the generation of hallucinations and is more suitable for enterprise-level workloads.
Like the previously launched Command R, the context window length of Command R is 128k.
In addition, Command R also has the following features:
- Covers 10 languages, including English, Chinese, French, German, etc.;
- Can use tools to complete complex tasks Automation of business processes
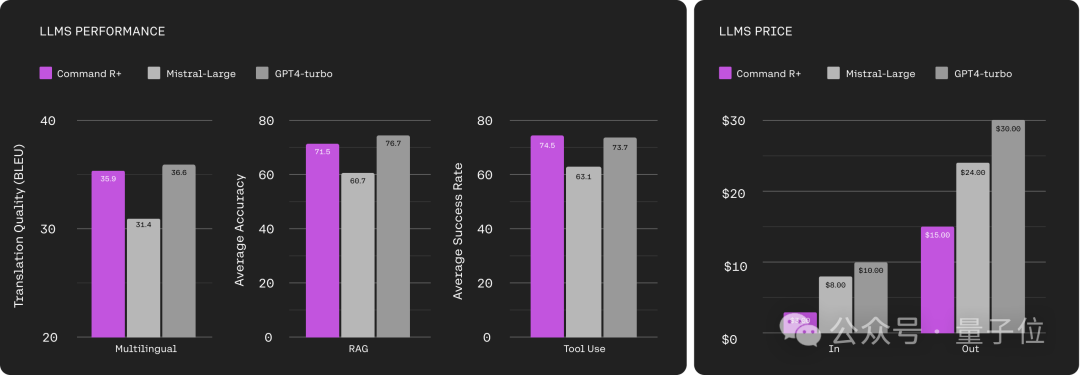
Judging from the test results, Command R has reached the level of GPT-4 turbo in the three dimensions of multi-language, RAG and tool usage.
But in terms of input cost, the price of Command R is only 1/3 of GPT-4 turbo.
In terms of output cost, Command R is 1/2 of GPT-4 turbo.
 Picture
Picture
It is this that has attracted the attention of many netizens:
 Picture
Picture
However, despite its eye-catching performance in human subjective evaluations such as the large model arena, some netizens still expressed some different opinions.
On HumanEval, Command R’s coding ability has not even surpassed GPT-3.5, ranking 32nd and 33rd respectively in the two sets of tests.
The latest version of GPT-4 turbo won the first place without any suspense.
 Picture
Picture
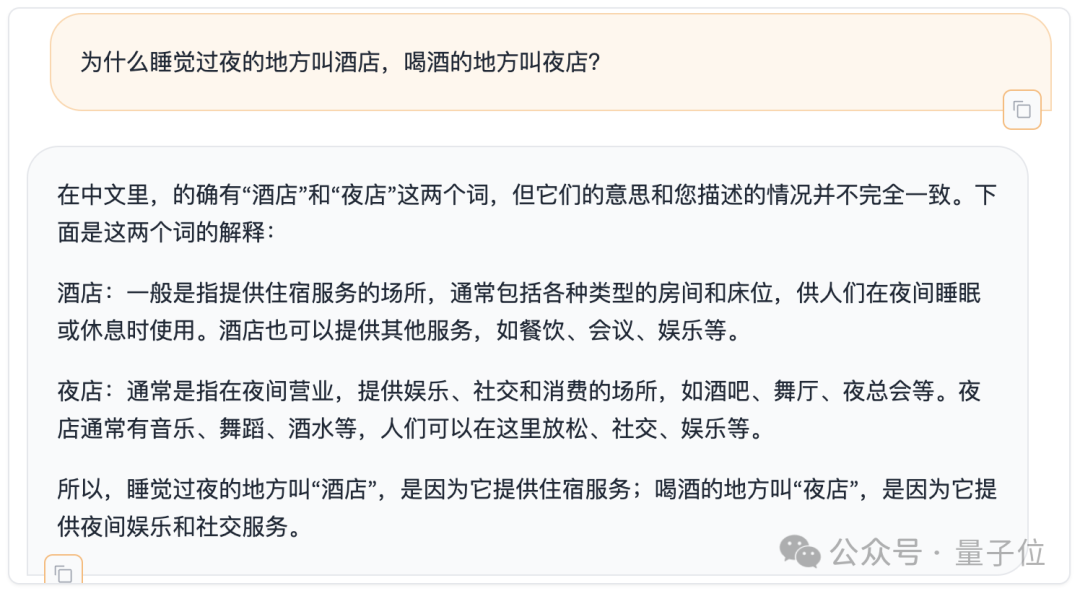
In addition, we also briefly tested the Chinese ability of Command R on the Mentally Retarded Benchmark, which has recently been listed in serious papers.
 Picture
Picture
How would you rate it?
It should be noted that the open source of Command R is only for academic research and is not free for commercial use.
One More Thing
Finally, let’s talk more about the wheat-cutting guy.
Aidan Gomez, the youngest of the Transformer Knights of the Round Table, was just an undergraduate when he joined the research team——
However, he joined the Hinton experiment when he was a junior at the University of Toronto. The kind of room.
In 2018, Kaomaizi was admitted to Oxford University and began studying for a PhD in CS like his thesis partners.
But in 2019, with the founding of Cohere, he finally chose to drop out of school and join the wave of AI entrepreneurship.
Cohere mainly provides large model solutions for enterprises, and its current valuation has reached US$2.2 billion.
Reference link:
[1]https://www.php.cn/link/3be14122a3c78d9070cae09a16adcbb1[2]https://www.php.cn/ link/93fc5aed8c051ce4538e052cfe9f8692
The above is the detailed content of The open source model wins GPT-4 for the first time! Arena's latest battle report has sparked heated debate, Karpathy: This is the only list I trust. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
Regarding Llama3, new test results have been released - the large model evaluation community LMSYS released a large model ranking list. Llama3 ranked fifth, and tied for first place with GPT-4 in the English category. The picture is different from other benchmarks. This list is based on one-on-one battles between models, and the evaluators from all over the network make their own propositions and scores. In the end, Llama3 ranked fifth on the list, followed by three different versions of GPT-4 and Claude3 Super Cup Opus. In the English single list, Llama3 overtook Claude and tied with GPT-4. Regarding this result, Meta’s chief scientist LeCun was very happy and forwarded the tweet and
 New feature in PHP version 5.4: How to use callable type hint parameters to accept callable functions or methods
Jul 29, 2023 pm 09:19 PM
New feature in PHP version 5.4: How to use callable type hint parameters to accept callable functions or methods
Jul 29, 2023 pm 09:19 PM
New feature of PHP5.4 version: How to use callable type hint parameters to accept callable functions or methods Introduction: PHP5.4 version introduces a very convenient new feature - you can use callable type hint parameters to accept callable functions or methods . This new feature allows functions and methods to directly specify the corresponding callable parameters without additional checks and conversions. In this article, we will introduce the use of callable type hints and provide some code examples,
 What do product parameters mean?
Jul 05, 2023 am 11:13 AM
What do product parameters mean?
Jul 05, 2023 am 11:13 AM
Product parameters refer to the meaning of product attributes. For example, clothing parameters include brand, material, model, size, style, fabric, applicable group, color, etc.; food parameters include brand, weight, material, health license number, applicable group, color, etc.; home appliance parameters include brand, size, color , place of origin, applicable voltage, signal, interface and power, etc.
 The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The volume is crazy, the volume is crazy, and the big model has changed again. Just now, the world's most powerful AI model changed hands overnight, and GPT-4 was pulled from the altar. Anthropic released the latest Claude3 series of models. One sentence evaluation: It really crushes GPT-4! In terms of multi-modal and language ability indicators, Claude3 wins. In Anthropic’s words, the Claude3 series models have set new industry benchmarks in reasoning, mathematics, coding, multi-language understanding and vision! Anthropic is a startup company formed by employees who "defected" from OpenAI due to different security concepts. Their products have repeatedly hit OpenAI hard. This time, Claude3 even had a big surgery.
 PHP Warning: Solution to in_array() expects parameter
Jun 22, 2023 pm 11:52 PM
PHP Warning: Solution to in_array() expects parameter
Jun 22, 2023 pm 11:52 PM
During the development process, we may encounter such an error message: PHPWarning: in_array()expectsparameter. This error message will appear when using the in_array() function. It may be caused by incorrect parameter passing of the function. Let’s take a look at the solution to this error message. First, you need to clarify the role of the in_array() function: check whether a value exists in the array. The prototype of this function is: in_a
 i9-12900H parameter evaluation list
Feb 23, 2024 am 09:25 AM
i9-12900H parameter evaluation list
Feb 23, 2024 am 09:25 AM
i9-12900H is a 14-core processor. The architecture and technology used are all new, and the threads are also very high. The overall work is excellent, and some parameters have been improved. It is particularly comprehensive and can bring users Excellent experience. i9-12900H parameter evaluation review: 1. i9-12900H is a 14-core processor, which adopts the q1 architecture and 24576kb process technology, and has been upgraded to 20 threads. 2. The maximum CPU frequency is 1.80! 5.00ghz, which mainly depends on the workload. 3. Compared with the price, it is very suitable. The price-performance ratio is very good, and it is very suitable for some partners who need normal use. i9-12900H parameter evaluation and performance running scores
