
 Technology peripherals
AI
Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Technology peripherals
AI
Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models

The potential of large language models is stimulated -
High-precision time series prediction can be achieved without training large language models, surpassing all traditional time series models.
Monash University, Ant and IBM Research jointly developed a general framework that successfully promoted the ability of large language models to process sequence data across modalities. The framework has become an important technological innovation.

Time series prediction is beneficial to decision-making in typical complex systems such as cities, energy, transportation, and remote sensing.
Since then, large models are expected to completely change the way of time series/spatiotemporal data mining.
General large language model reprogramming framework
The research team proposed a general framework to easily use large language models for general time series prediction without any training.
Mainly proposes two key technologies: timing input reprogramming; prompt prefixing.
Time-LLM first uses text prototypes (Text Prototypes) to reprogram the input time data, uses natural language representation to represent the semantic information of the time data, and then aligns two different data modalities so that A large language model can understand the information behind another data modality without any modification. At the same time, the large language model does not require any specific training data set to understand the information behind different data modalities. This method not only improves the accuracy of the model, but also simplifies the data preprocessing process.
In order to better handle the analysis of input time series data and corresponding tasks, the author proposed the Prompt-as-Prefix (PaP) paradigm. This paradigm fully activates the processing capabilities of LLM on temporal tasks by adding additional contextual information and task instructions before the representation of temporal data. This method can achieve more refined analysis on timing tasks, and fully activate the processing capabilities of LLM on timing tasks by adding additional contextual information and task instructions in front of the timing data table.
Main contributions include:
- Proposed a new concept of reprogramming large language models for timing analysis without any modification to the backbone language model.
- Propose a general language model reprogramming framework Time-LLM, which involves reprogramming input temporal data into a more natural textual prototype representation, and through declarative prompts (such as domain expert knowledge and task instructions ) to enhance the input context to guide LLM for effective cross-domain reasoning.

- The performance in mainstream prediction tasks consistently exceeds the performance of the best existing models, especially in few-sample and zero-sample scenarios. Furthermore, Time-LLM is able to achieve higher performance while maintaining excellent model reprogramming efficiency. Greatly unlock the untapped potential of LLM for time series and other sequential data.
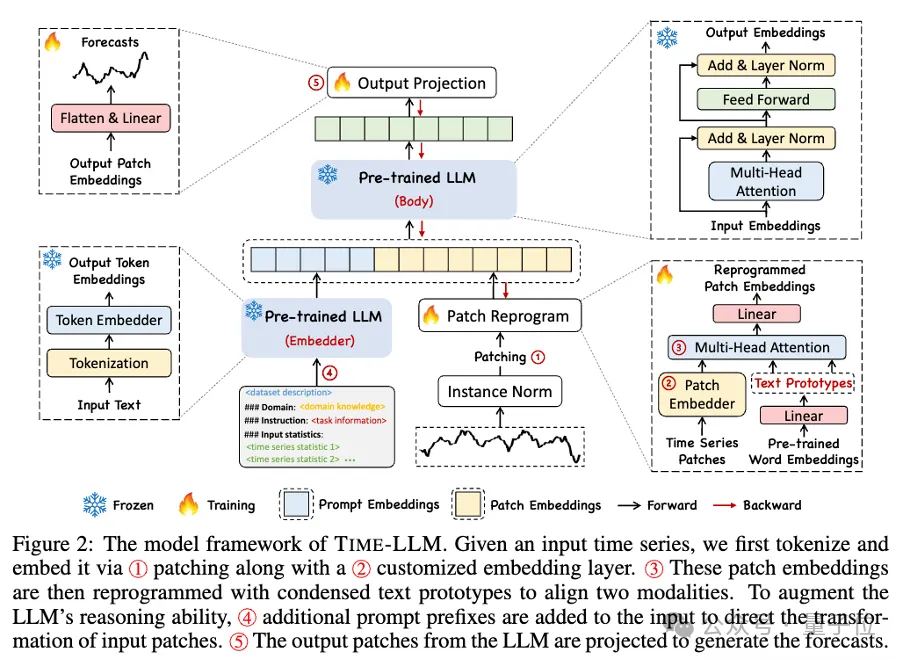
Looking specifically at this framework, first, the input time series data is first normalized by RevIN, and then divided into different patches and mapped to the latent space.
There are significant differences in expression methods between time series data and text data, and they belong to different modalities.
Time series can neither be edited directly nor described losslessly in natural language. Therefore, we need to align temporal input features to the natural language text domain.

A common way to align different modalities is cross-attention, but the inherent vocabulary of LLM is very large, so it is impossible to effectively directly align temporal features to all words. , and not all words have aligned semantic relationships with time series.
In order to solve this problem, this work performs a linear combination of vocabularies to obtain text prototypes. The number of text prototypes is much smaller than the original vocabulary size. The combination can be used to represent the changing characteristics of time series data.
In order to fully activate the ability of LLM in specifying timing tasks, this work proposes a prompt prefix paradigm.
To put it in layman's terms, it means feeding some prior information of the time series data set in a natural language as a prefix prompt, and splicing it with the aligned time series features to LLM. Can it improve the prediction effect?
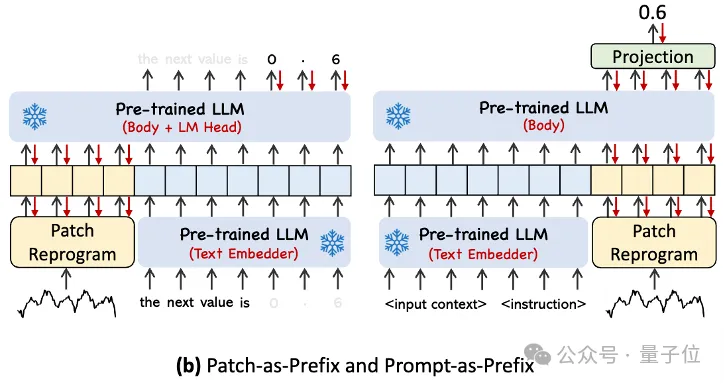
In practice, the authors identified three key components for building effective prompts:
Dataset context; (2) Task instructions to make LLM suitable Equipped with different downstream tasks; (3) Statistical descriptions, such as trends, delays, etc., allow LLM to better understand the characteristics of time series data.

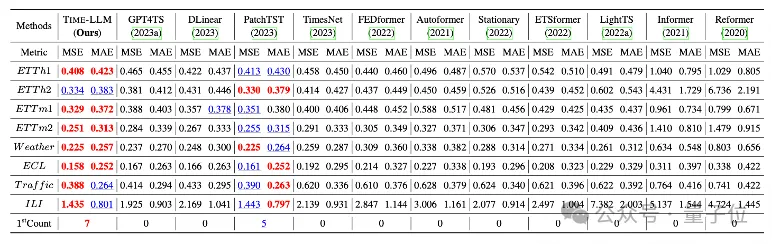
The team conducted comprehensive tests on eight classic public data sets for long-range prediction.
Results Time-LLM significantly exceeded the previous best results in the field in the benchmark comparison. For example, compared with GPT4TS that directly uses GPT-2, Time-LLM has a significant improvement, indicating the effectiveness of this method.
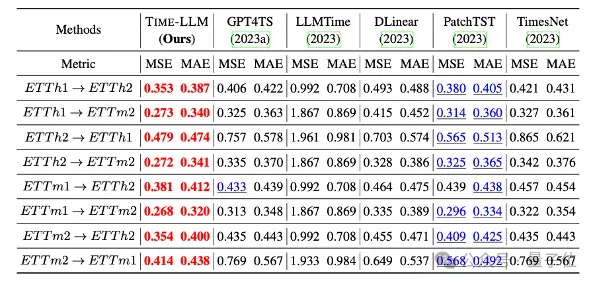
#In addition, it also shows strong prediction ability in zero-shot scenarios.
This project is supported by NextEvo, the AI innovation R&D department of Ant Group’s Intelligent Engine Division.
Interested friends can click on the link below to learn more about the paper~
Paper linkhttps://arxiv.org/abs/2310.01728.
The above is the detailed content of Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
How to configure Debian Apache log format
Apr 12, 2025 pm 11:30 PM
This article describes how to customize Apache's log format on Debian systems. The following steps will guide you through the configuration process: Step 1: Access the Apache configuration file The main Apache configuration file of the Debian system is usually located in /etc/apache2/apache2.conf or /etc/apache2/httpd.conf. Open the configuration file with root permissions using the following command: sudonano/etc/apache2/apache2.conf or sudonano/etc/apache2/httpd.conf Step 2: Define custom log formats to find or
 How Tomcat logs help troubleshoot memory leaks
Apr 12, 2025 pm 11:42 PM
How Tomcat logs help troubleshoot memory leaks
Apr 12, 2025 pm 11:42 PM
Tomcat logs are the key to diagnosing memory leak problems. By analyzing Tomcat logs, you can gain insight into memory usage and garbage collection (GC) behavior, effectively locate and resolve memory leaks. Here is how to troubleshoot memory leaks using Tomcat logs: 1. GC log analysis First, enable detailed GC logging. Add the following JVM options to the Tomcat startup parameters: -XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log These parameters will generate a detailed GC log (gc.log), including information such as GC type, recycling object size and time. Analysis gc.log
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
How to configure firewall rules for Debian syslog
Apr 13, 2025 am 06:51 AM
This article describes how to configure firewall rules using iptables or ufw in Debian systems and use Syslog to record firewall activities. Method 1: Use iptablesiptables is a powerful command line firewall tool in Debian system. View existing rules: Use the following command to view the current iptables rules: sudoiptables-L-n-v allows specific IP access: For example, allow IP address 192.168.1.100 to access port 80: sudoiptables-AINPUT-ptcp--dport80-s192.16
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
How to learn Debian syslog
Apr 13, 2025 am 11:51 AM
This guide will guide you to learn how to use Syslog in Debian systems. Syslog is a key service in Linux systems for logging system and application log messages. It helps administrators monitor and analyze system activity to quickly identify and resolve problems. 1. Basic knowledge of Syslog The core functions of Syslog include: centrally collecting and managing log messages; supporting multiple log output formats and target locations (such as files or networks); providing real-time log viewing and filtering functions. 2. Install and configure Syslog (using Rsyslog) The Debian system uses Rsyslog by default. You can install it with the following command: sudoaptupdatesud
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
