

This paper discusses the field of 3D target detection, especially 3D target detection for Open-Vocabulary. In traditional 3D object detection tasks, systems need to predict the localization of 3D bounding boxes and semantic category labels for objects in real scenes, which usually relies on point clouds or RGB images. Although 2D object detection technology performs well due to its ubiquity and speed, relevant research shows that the development of 3D universal detection lags behind in comparison. Currently, most 3D object detection methods still rely on fully supervised learning and are limited by fully annotated data under specific input modes, and can only recognize categories that emerge during training, whether in indoor or outdoor scenes.
This paper points out that the challenges facing 3D universal object detection mainly include: existing 3D detectors can only work with closed vocabulary aggregation, and therefore can only detect categories that have already been seen. Open-Vocabulary's 3D object detection is urgently needed to identify and locate new class object instances not acquired during training. Existing 3D detection datasets are limited in size and category compared to 2D datasets, which limits the generalization ability in locating new objects. In addition, the lack of pre-trained image-text models in the 3D domain further exacerbates the challenges of Open-Vocabulary 3D detection. At the same time, there is a lack of a unified architecture for multi-modal 3D detection, and existing 3D detectors are mostly designed for specific input modalities (point clouds, RGB images, or both), which hinders the effective utilization of data from different modalities. and scene (indoor or outdoor), thus limiting the generalization ability to new targets.
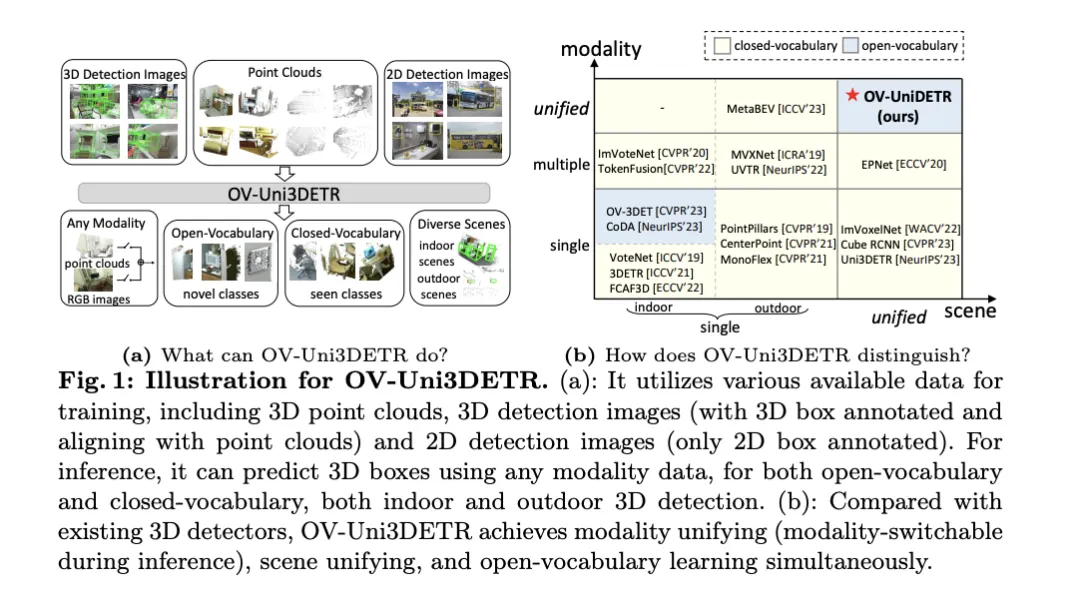
In order to solve the above problems, the paper proposes a unified multi-modal 3D detector called OV-Uni3DETR. The detector is able to utilize multi-modal and multi-source data during training, including point clouds, point clouds with accurate 3D box annotations and point cloud-aligned 3D detection images, and 2D detection images containing only 2D box annotations. Through this multi-modal learning method, OV-Uni3DETR is able to process data of any modality during inference, achieve modal switching during testing, and perform well in detecting basic categories and new categories. The unified structure further enables OV-Uni3DETR to detect in indoor and outdoor scenes, with Open-Vocabulary capabilities, thereby significantly improving the universality of the 3D detector across categories, scenes and modalities.
In addition, aiming at the problem of how to generalize the detector to recognize new categories, and how to learn from a large number of 2D detection images without 3D box annotations, the paper proposes a method called periodic mode propagation approach - With this approach, knowledge is spread between 2D and 3D modalities to address both challenges. In this way, the rich semantic knowledge of the 2D detector can be propagated to the 3D domain to assist in discovering new boxes, and the geometric knowledge of the 3D detector can be used to localize objects in the 2D detection image and match the classification labels through matching .
The main contributions of the paper include proposing a unified Open-Vocabulary 3D detector OV-Uni3DETR that can detect any category of targets in different modalities and diverse scenes; proposing a unified Open-Vocabulary 3D detector for indoor and outdoor scenes. A multi-modal architecture; and the concept of a knowledge propagation cycle between 2D and 3D modalities is proposed. With these innovations, OV-Uni3DETR achieves state-of-the-art performance on multiple 3D detection tasks and significantly outperforms previous methods in the Open-Vocabulary setting. These results show that OV-Uni3DETR has taken an important step for the future development of 3D basic models.
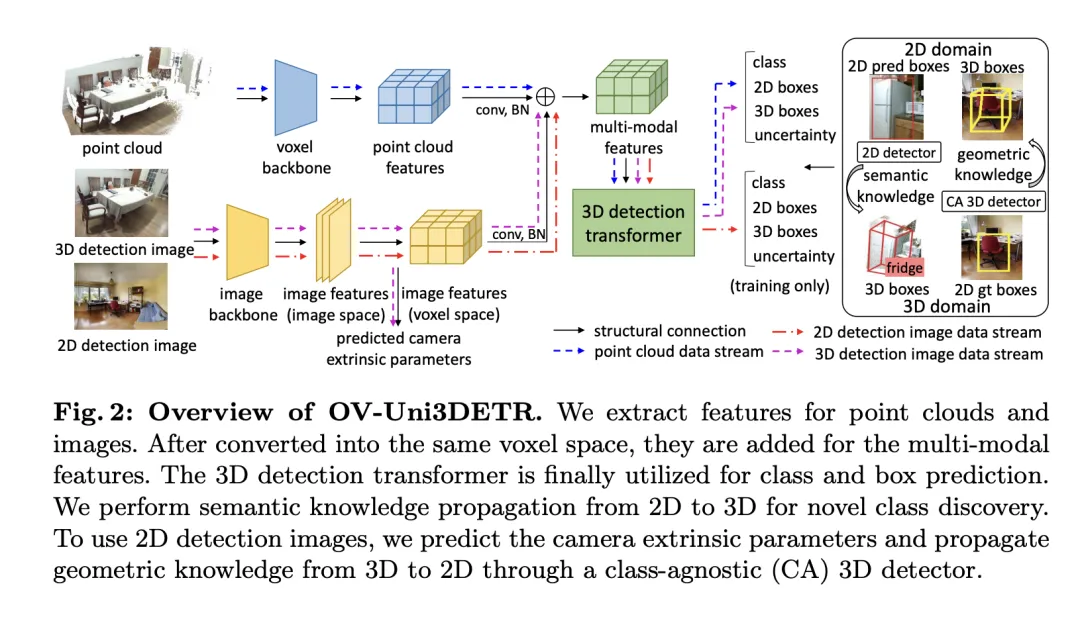
This article introduces a multi-modal learning framework specifically for 3D object detection tasks, which enhances detection performance by integrating cloud data and image data. This framework can handle certain sensor modalities that may be missing during inference, that is, it also has the ability to switch modes during testing. Features from two different modalities, including 3D point cloud features and 2D image features, are extracted and integrated through a specific network structure. After elemental processing and camera parameter mapping, these features are fused for subsequent target detection tasks.
Key technical points include using 3D convolution and batch normalization to normalize and integrate features of different modes to prevent inconsistencies at the feature level from causing a certain mode to be ignored. In addition, the training strategy of randomly switching modes ensures that the model can flexibly process data from only a single mode, thereby improving the robustness and adaptability of the model.
Ultimately, the architecture utilizes a composite loss function that combines losses from class prediction, 2D and 3D bounding box regression, and an uncertainty prediction for a weighted regression loss to optimize the entire detection process. This multi-modal learning method not only improves the detection performance of existing categories, but also enhances the generalization ability to new categories by fusing different types of data. The multi-modal architecture ultimately predicts class labels, 4D 2D boxes and 7D 3D boxes for 2D and 3D object detection. For 3D box regression, L1 loss and decoupled IoU loss are used; for 2D box regression, L1 loss and GIoU loss are used. In the Open-Vocabulary setting, there are new category samples, which increases the difficulty of training samples. Therefore, uncertainty prediction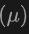 is introduced and used to weight the L1 regression loss. The loss of object detection learning is:
is introduced and used to weight the L1 regression loss. The loss of object detection learning is:
For some 3D scenes, there may be multi-view images instead of a single monocular image. For each of them, image features are extracted and projected into voxel space using the respective projection matrix. Multiple image features in voxel space are summed to obtain multimodal features. This approach improves the model's generalization ability to new categories and enhances adaptability under diverse input conditions by combining information from different modalities.
Based on the multi-modal learning introduced, this article implements a method called "knowledge Propagation" for Open-Vocabulary's 3D detection. Propagation:  " method. The core problem of Open-Vocabulary learning is to identify new categories that have not been manually labeled during the training process. Due to the difficulty of obtaining point cloud data, pre-trained visual-language models have not yet been developed in the point cloud field. The modal differences between point cloud data and RGB images limit the performance of these models in 3D detection.
" method. The core problem of Open-Vocabulary learning is to identify new categories that have not been manually labeled during the training process. Due to the difficulty of obtaining point cloud data, pre-trained visual-language models have not yet been developed in the point cloud field. The modal differences between point cloud data and RGB images limit the performance of these models in 3D detection.

To solve this problem, we propose to utilize the semantic knowledge of pre-trained 2D Open-Vocabulary detectors and generate corresponding 3D bounding boxes for new categories. These generated 3D boxes will complement the limited 3D ground-truth labels available during training.
Specifically, a 2D bounding box or instance mask is first generated using the 2DOpen-Vocabulary detector. Considering that the data and annotations available in the 2D domain are richer, these generated 2D boxes can achieve higher positioning accuracy and cover a wider range of categories. Then, these 2D boxes are projected into 3D space by 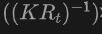 to obtain the corresponding 3D boxes. The specific operation is to use
to obtain the corresponding 3D boxes. The specific operation is to use 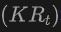
to project 3D points into 2D space, find the points in the 2D box, and then cluster these points in the 2D box to eliminate outliers, thereby obtaining the corresponding 3D frame. Due to the presence of pre-trained 2D detectors, new unlabeled objects can be discovered in the generated 3D box set. In this way, 3DOpen-Vocabulary detection is greatly facilitated by the rich semantic knowledge propagated from the 2D domain to the generated 3D boxes. For multi-view images, 3D boxes are generated separately and integrated together for final use.
During inference, when both point clouds and images are available, 3D boxes can be extracted in a similar manner. These generated 3D boxes can also be regarded as a form of 3DOpen-Vocabulary detection results. These 3D boxes are added to the predictions of the multimodal 3D transformer to supplement possible missing objects and filter overlapping bounding boxes via 3D non-maximum suppression (NMS). The confidence score assigned by the pretrained 2D detector is systematically divided by a predetermined constant and then reinterpreted as the confidence score of the corresponding 3D box.
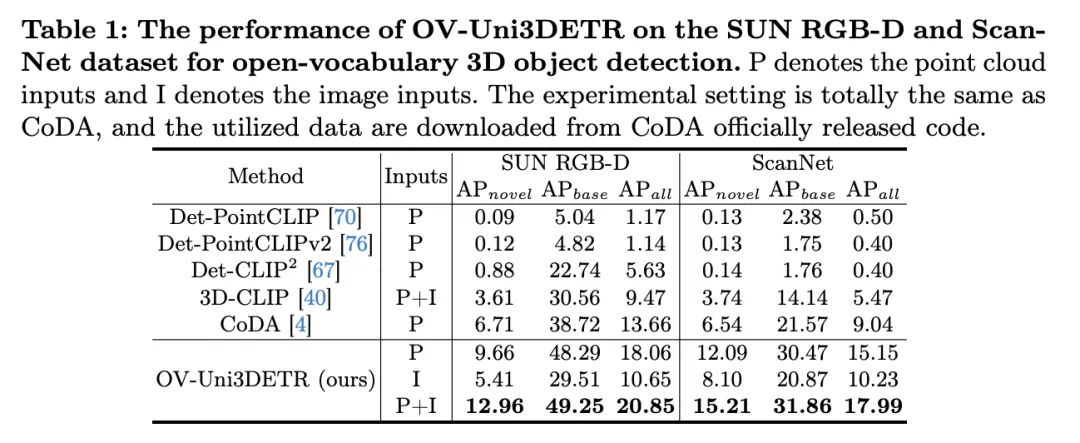
The table shows the performance of OV-Uni3DETR for Open-Vocabulary3D object detection on SUN RGB-D and ScanNet datasets. The experimental settings are exactly the same as CoDA, and the data used comes from the officially released code of CoDA. Performance indicators include new category average accuracy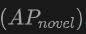 , base class average accuracy
, base class average accuracy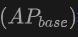 and all classes average accuracy
and all classes average accuracy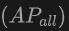 . Input types include point clouds (P), images (I), and their combinations (PI).
. Input types include point clouds (P), images (I), and their combinations (PI).
Analyzing these results, we can observe the following points:
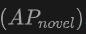 of the new category. This shows that combining point clouds and images can significantly improve the model's ability to detect unseen classes, as well as the overall detection performance.
of the new category. This shows that combining point clouds and images can significantly improve the model's ability to detect unseen classes, as well as the overall detection performance. 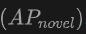 is particularly worthy of attention, which is particularly critical for Open-Vocabulary detection. On the SUN RGB-D dataset, the
is particularly worthy of attention, which is particularly critical for Open-Vocabulary detection. On the SUN RGB-D dataset, the 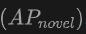 achieved 12.96% when using point cloud and image input, and 15.21% on the ScanNet dataset, which is significantly higher than other methods, showing its improvement in the recognition training process. Powerful capabilities in a category never seen before.
achieved 12.96% when using point cloud and image input, and 15.21% on the ScanNet dataset, which is significantly higher than other methods, showing its improvement in the recognition training process. Powerful capabilities in a category never seen before. Overall, OV-Uni3DETR shows excellent performance on Open-Vocabulary3D object detection tasks through its unified multi-modal learning architecture, especially when combining point cloud and image data At the same time, it can effectively improve the detection ability of new categories, proving the effectiveness and importance of multi-modal input and knowledge dissemination strategies.
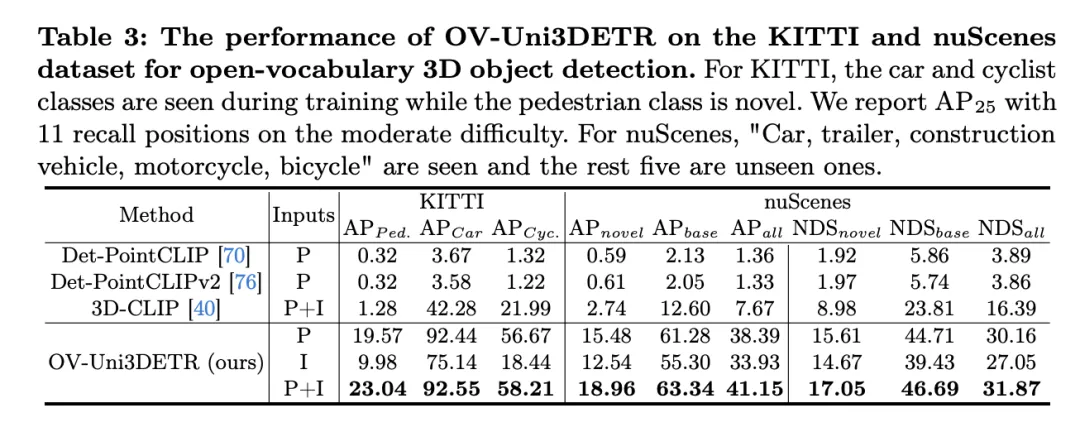
This table shows the performance of OV-Uni3DETR for Open-Vocabulary3D object detection on the KITTI and nuScenes datasets, covering what has been seen during the training process (base) and Novel categories. For the KITTI dataset, the "car" and "cyclist" categories were seen during training, while the "pedestrian" category is novel. Performance is measured using the 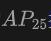
metric at medium difficulty, using 11 recall positions. For the nuScenes data set, "car, trailer, construction vehicle, motorcycle, bicycle" is a seen category, and the remaining five are unseen categories. In addition to AP indicators, NDS (NuScenes Detection Score) is also reported to comprehensively evaluate detection performance.
Analyzing these results, the following conclusions can be drawn:
OV-Uni3DETR在Open-Vocabulary3D目标检测上展示了卓越的性能,特别是在处理未见类别和多模态数据方面。这些结果验证了多模态输入和知识传播策略的有效性,以及OV-Uni3DETR在提升3D目标检测任务泛化能力方面的潜力。

这篇论文通过提出OV-Uni3DETR,一个统一的多模态3D检测器,为Open-Vocabulary的3D目标检测领域带来了显著的进步。该方法利用了多模态数据(点云和图像)来提升检测性能,并通过2D到3D的知识传播策略,有效地扩展了模型对未见类别的识别能力。在多个公开数据集上的实验结果证明了OV-Uni3DETR在新类别和基类上的出色性能,尤其是在结合点云和图像输入时,能够显著提高对新类别的检测能力,同时在整体检测性能上也达到了新的高度。
优点方面,OV-Uni3DETR首先展示了多模态学习在提升3D目标检测性能中的潜力。通过整合点云和图像数据,模型能够从每种模态中学习到互补的特征,从而在丰富的场景和多样的目标类别上实现更精确的检测。其次,通过引入2D到3D的知识传播机制,OV-Uni3DETR能够利用丰富的2D图像数据和预训练的2D检测模型来识别和定位训练过程中未见过的新类别,这大大提高了模型的泛化能力。此外,该方法在处理Open-Vocabulary检测时显示出的强大能力,为3D检测领域带来了新的研究方向和潜在应用。
缺点方面,虽然OV-Uni3DETR在多个方面展现了其优势,但也存在一些潜在的局限性。首先,多模态学习虽然能提高性能,但也增加了数据采集和处理的复杂性,尤其是在实际应用中,不同模态数据的同步和配准可能会带来挑战。其次,尽管知识传播策略能有效利用2D数据来辅助3D检测,但这种方法可能依赖于高质量的2D检测模型和准确的3D-2D对齐技术,这在一些复杂环境中可能难以保证。此外,对于一些极其罕见的类别,即使是Open-Vocabulary检测也可能面临识别准确性的挑战,这需要进一步的研究来解决。
OV-Uni3DETR通过其创新的多模态学习和知识传播策略,在Open-Vocabulary3D目标检测上取得了显著的进展。虽然存在一些潜在的局限性,但其优点表明了这一方法在推动3D检测技术发展和应用拓展方面的巨大潜力。未来的研究可以进一步探索如何克服这些局限性,以及如何将这些策略应用于更广泛的3D感知任务中。
在本文中,我们主要提出了OV-Uni3DETR,一种统一的多模态开放词汇三维检测器。借助于多模态学习和循环模态知识传播,我们的OV-Uni3DETR很好地识别和定位了新类,实现了模态统一和场景统一。实验证明,它在开放词汇和封闭词汇环境中,无论是室内还是室外场景,以及任何模态数据输入中都有很强的能力。针对多模态环境下统一的开放词汇三维检测,我们相信我们的研究将推动后续研究沿着有希望但具有挑战性的通用三维计算机视觉方向发展。
The above is the detailed content of Multiple SOTAs! OV-Uni3DETR: Improving the generalizability of 3D detection across categories, scenes and modalities (Tsinghua & HKU). For more information, please follow other related articles on the PHP Chinese website!
 The difference between Fahrenheit and Celsius
The difference between Fahrenheit and Celsius
 The role of float() function in python
The role of float() function in python
 Configure Java runtime environment
Configure Java runtime environment
 What to do if the documents folder pops up when the computer is turned on
What to do if the documents folder pops up when the computer is turned on
 The role of registering a cloud server
The role of registering a cloud server
 How to buy Ripple in China
How to buy Ripple in China
 NTSD command usage
NTSD command usage
 phpstudy database cannot start solution
phpstudy database cannot start solution
 Usage of background-image
Usage of background-image








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



