
 Technology peripherals
AI
Long text cannot kill RAG: SQL+ vector drives large models and the new paradigm of big data, MyScale AI database is officially open source
Technology peripherals
AI
Long text cannot kill RAG: SQL+ vector drives large models and the new paradigm of big data, MyScale AI database is officially open source
Long text cannot kill RAG: SQL+ vector drives large models and the new paradigm of big data, MyScale AI database is officially open source

The combination of large models and AI databases has become a magic weapon for cost reduction and efficiency improvement of large models and truly intelligent big data.

Specialized vector databases represented by Pinecone/Weaviate/Milvus were designed and built for vector retrieval from the beginning. The vector retrieval performance is excellent, but it is not universal. The data management function is weak. Keyword and vector retrieval systems represented by Elasticsearch/OpenSearch are widely used in production because of their complete keyword retrieval functions. However, they occupy a lot of system resources, and keywords and vectors The accuracy and performance of the joint query are not satisfactory. SQL vector databases represented by pgvector (vector search plug-in for PostgreSQL) and MyScale AI database are based on SQL and have powerful data management functions. However, due to the disadvantages of PostgreSQL row storage and the limitations of vector algorithms, pgvector has low accuracy in complex vector queries.
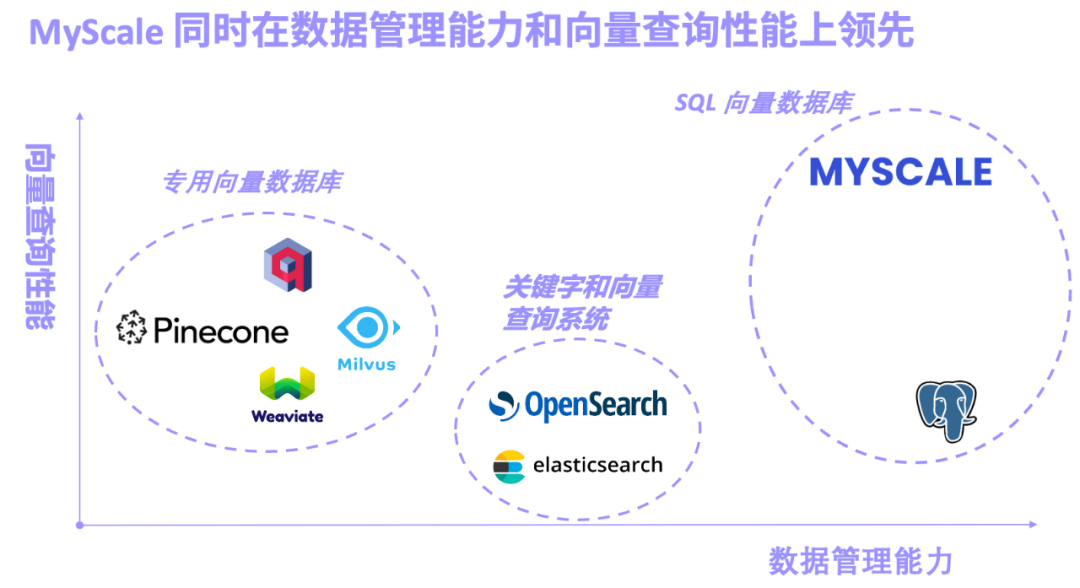
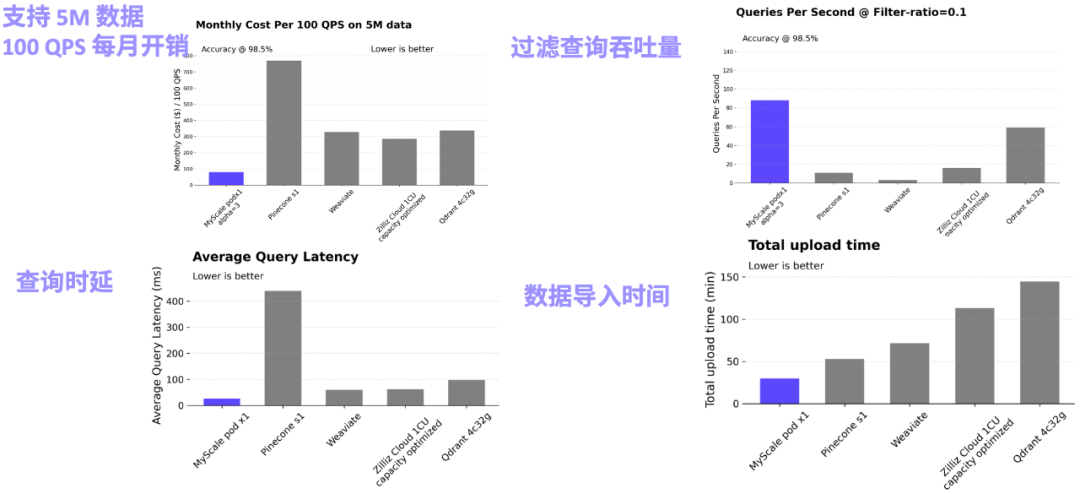
In actual complex AI application scenarios, the combination of SQL and vectors can greatly increase the flexibility of data modeling and simplify the development process. For example, in the Science Navigator project cooperating between the MyScale team and the Beijing Institute of Scientific Intelligence, MyScaleDB is used to retrieve massive scientific literature data and perform intelligent question answering. There are more than 10 main SQL table structures, many of which establish vectors. And inverted table index, and use the primary key and foreign key to make the association. In actual queries, the system will also involve joint queries of structured, vector and keyword data, as well as related queries of several tables. These modeling and correlations are difficult to achieve in a dedicated vector database, which will also lead to slow iteration of the final system, inefficient querying and difficult maintenance.
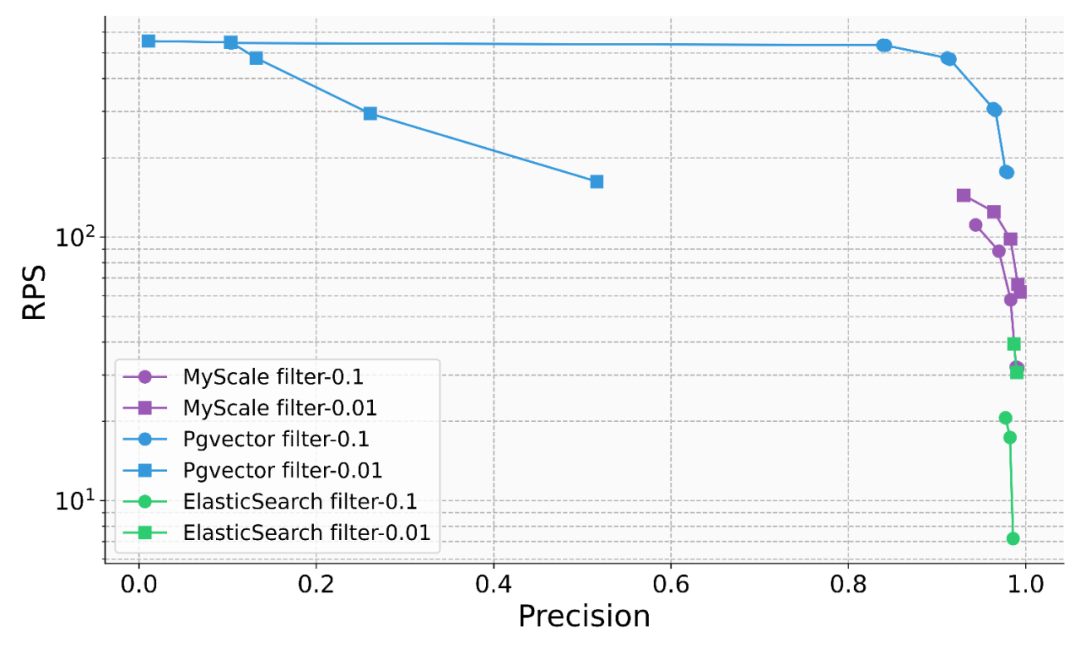
. The MyScale team has already explored the implementation of this solution in scientific research, finance, industry, medical and other fields. 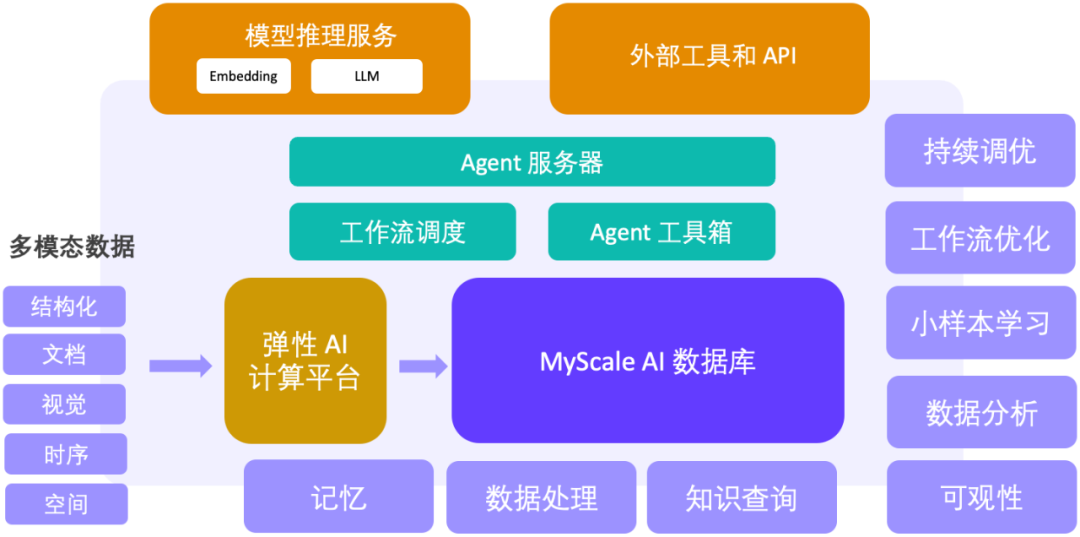
The above is the detailed content of Long text cannot kill RAG: SQL+ vector drives large models and the new paradigm of big data, MyScale AI database is officially open source. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
The library used for floating-point number operation in Go language introduces how to ensure the accuracy is...
 How to run the h5 project
Apr 06, 2025 pm 12:21 PM
How to run the h5 project
Apr 06, 2025 pm 12:21 PM
Running the H5 project requires the following steps: installing necessary tools such as web server, Node.js, development tools, etc. Build a development environment, create project folders, initialize projects, and write code. Start the development server and run the command using the command line. Preview the project in your browser and enter the development server URL. Publish projects, optimize code, deploy projects, and set up web server configuration.
 Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
GiteePages static website deployment failed: 404 error troubleshooting and resolution when using Gitee...
 How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
Under the BeegoORM framework, how to specify the database associated with the model? Many Beego projects require multiple databases to be operated simultaneously. When using Beego...
 Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or well-known open source projects? When programming in Go, developers often encounter some common needs, ...
 How to solve the user_id type conversion problem when using Redis Stream to implement message queues in Go language?
Apr 02, 2025 pm 04:54 PM
How to solve the user_id type conversion problem when using Redis Stream to implement message queues in Go language?
Apr 02, 2025 pm 04:54 PM
The problem of using RedisStream to implement message queues in Go language is using Go language and Redis...
 Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
The H5 page needs to be maintained continuously, because of factors such as code vulnerabilities, browser compatibility, performance optimization, security updates and user experience improvements. Effective maintenance methods include establishing a complete testing system, using version control tools, regularly monitoring page performance, collecting user feedback and formulating maintenance plans.
 When using sql.Open, why does not report an error when DSN passes empty?
Apr 02, 2025 pm 12:54 PM
When using sql.Open, why does not report an error when DSN passes empty?
Apr 02, 2025 pm 12:54 PM
When using sql.Open, why doesn’t the DSN report an error? In Go language, sql.Open...
