
 Technology peripherals
AI
New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~
Technology peripherals
AI
New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~
New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~

Original title: LidarDM: Generative LiDAR Simulation in a Generated World
Paper link: https://arxiv.org/pdf/2404.02903.pdf
Code link: https ://github.com/vzyrianov/lidardm
Author affiliation: University of Illinois, Massachusetts Institute of Technology

Thesis idea:
This article introduces LidarDM, a novel lidar generation model capable of producing realistic, layout-aware, physically believable, and temporally coherent lidar videos. LidarDM has two unprecedented capabilities in lidar generation modeling: (1) lidar generation guided by driving scenarios, providing significant incentives for autonomous driving simulations; (2) 4D lidar point cloud generation, enabling the creation of realistic and Temporally coherent lidar sequences are possible. The core of our model is a novel comprehensive 4D world generation framework. Specifically, this paper uses latent diffusion models to generate 3D scenes, combines them with dynamic actors to form the underlying 4D world, and then generates realistic laser perception data in this virtual environment. . Our experiments show that our method outperforms competing algorithms in terms of fidelity, temporal coherence, and layout consistency. This paper also demonstrates that LidarDM can be used as a generative world simulator for training and testing perception models.
Network Design:
The developed generative models have attracted increasing attention in handling data distribution and content creation, such as image and video generation [ 10, 33, 52-55], 3D object generation [10, 19, 38, 52], compression [5, 29, 68] and editing [37, 47] and other fields. Generative models also show excellent potential for simulation [6, 11, 18, 34, 46, 60, 64, 66, 76, 82], enabling the creation of realistic scenarios and their associated sensory data for training and evaluation of safety Critical intelligence capabilities, such as robots and self-driving vehicles, eliminate the need for costly manual modeling of the real world. These capabilities are critical for applications that rely on extensive environmental training or scenario testing.
Progress in conditional image and video generation has been remarkable, but the specific task of generating realistic lidar point cloud sequences for functionally specific scenarios for autonomous driving applications remains underexplored. Current lidar generation methods fall into two main categories, each of which faces specific challenges.
- Current lidar generation modeling methods [8, 72, 79, 83] are limited to single-frame generation and do not provide means for semantic controllability and temporal consistency.
- LiDAR resimulation [14, 17, 46, 65, 67, 74] relies heavily on user-created or real-world collected assets. This adds high operating costs, limits diversity, and limits wider applicability.
To address these challenges, this paper proposes LidarDM (Lidar Diffusion Model), which can create realistic, layout-aware, physically believable, and temporally coherent lidar videos. . This paper explores two novel capabilities that have not been addressed before: (i) lidar synthesis guided by driving scenarios, which has great potential for autonomous driving simulation, and (ii) aiming to produce realistic, annotated lidar point clouds Sequential 4D lidar point cloud synthesis. The key insight in achieving these goals in this paper lies in first generating and combining the underlying 4D world and then creating realistic perceptual observations within this virtual environment. To achieve this, this paper integrates existing 3D object generation methods to create dynamic actors and develops a new method for large-scale 3D scene generation based on latent diffusion models. This approach is capable of producing realistically diverse 3D driving scenes from the semantic layout of particles, and to the best of the knowledge of this paper, it is the first attempt. This article applies trajectories to generate a 3D world and performs stochastic raycasting simulation to generate the final 4D lidar sequence. As shown in Figure 1, the results generated in this paper are diverse, aligned with the layout conditions, and are both realistic and temporally coherent.
The experimental results of this paper show that single-frame images generated by LidarDM exhibit realism and diversity, and their performance is comparable to the state-of-the-art stripe-free single-frame laser point cloud generation technology. Furthermore, this paper demonstrates that LidarDM is capable of producing temporally coherent laser point cloud videos, beyond the robust diffusion sensor generation baseline. To the best of our knowledge, this is the first laser point cloud generation method with this capability. This paper further demonstrates the item generation capabilities of LidarDM by demonstrating good agreement between the generated laser point cloud and the real laser point cloud under matching map items. Finally, this paper demonstrates that data generated using LidarDM exhibit minimal domain gaps when tested with perception modules trained on real data, and can also be used to extend the training data, significantly improving the performance of 3D detectors. This provides a prerequisite for using the generated laser point cloud model to create a realistic and controllable simulation environment for training and testing driving models.
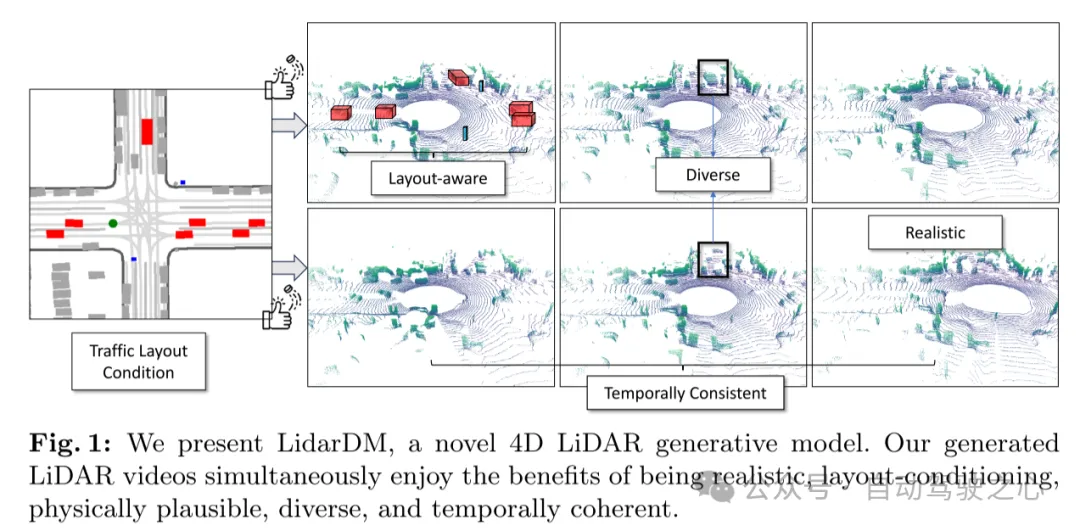
Figure 1: This paper demonstrates LidarDM, a novel 4D lidar generative model. The lidar video generated in this article has the advantages of realism, layout conditionality, physical credibility, diversity and temporal coherence at the same time.
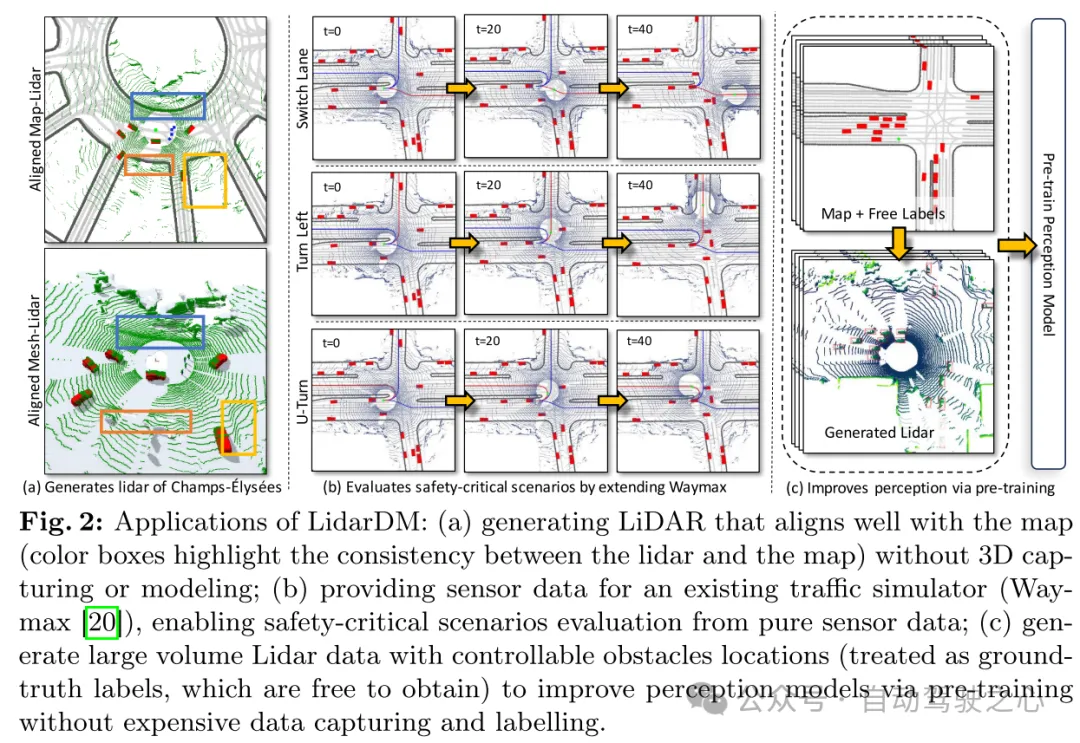
Figure 2: Application of LidarDM: (a) Generating lidar closely aligned with the map without 3D capture or modeling (colored box highlights lidar consistency with maps); (b) provide sensor data to an existing traffic simulator (Waymax [20]), enabling it to evaluate safety-critical scenarios from pure sensor data only; (c) generate traffic with controllable obstacles Large amounts of lidar data of object locations (considered as freely available ground truth labels) to improve perception models through pre-training without expensive data capture and annotation.
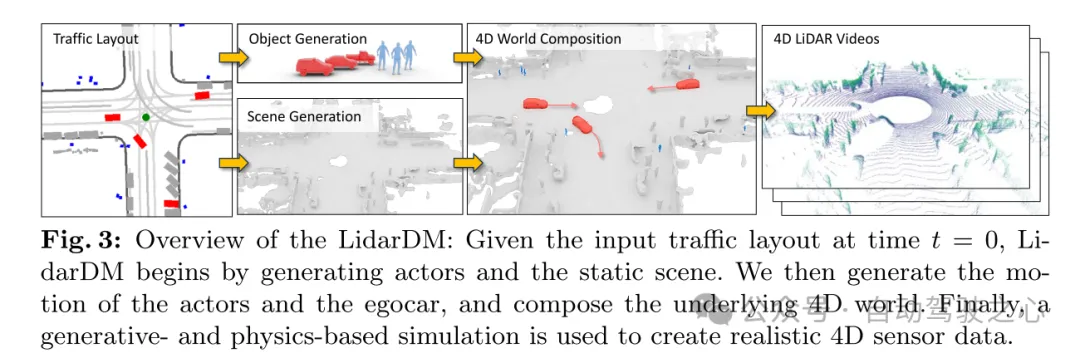
Figure 3: LidarDM Overview: Given the traffic layout input at time t = 0, LidarDM first generates traffic participants (actors) and static scenes. Then, this article generates the movements of traffic participants (actors) and self-vehicles, and builds the underlying 4D world. Finally, use generative and physics-based simulation to create realistic 4D sensor data.
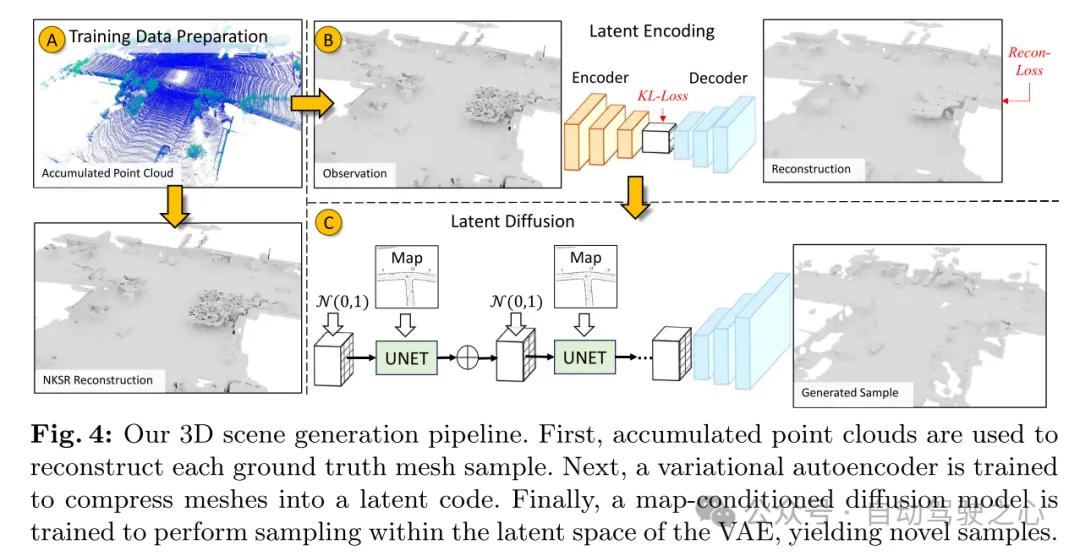
Figure 4: The 3D scene generation process of this article. First, the accumulated point cloud is used to reconstruct each real mesh sample. Next, a variational autoencoder (VAE) is trained to compress the grid into an implicit encoding. Finally, a diffusion model conditioned on the map is trained to sample within the latent space of the VAE to generate new samples.
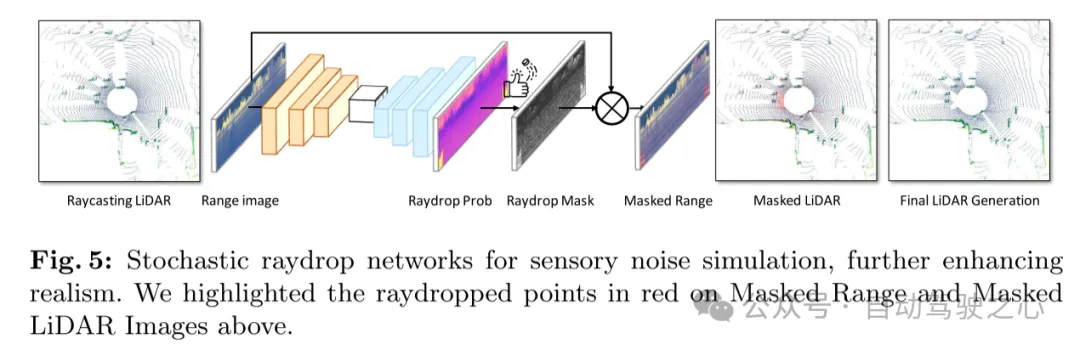
Figure 5: Random raydrop network for perceptual noise simulation, further enhancing realism. This article highlights raydropped points in red in the masked distance map and masked lidar image above.
Experimental results:

Figure 6: Real KITTI-360 samples compared to unconditioned samples from competing methods. UltraLiDAR sample visualizations are taken directly from their paper. Compared to previous methods, LidarDM generates samples with a greater number of more detailed salient objects (e.g., cars, pedestrians), clearer 3D structures (e.g., straight walls), and a more realistic road layout.
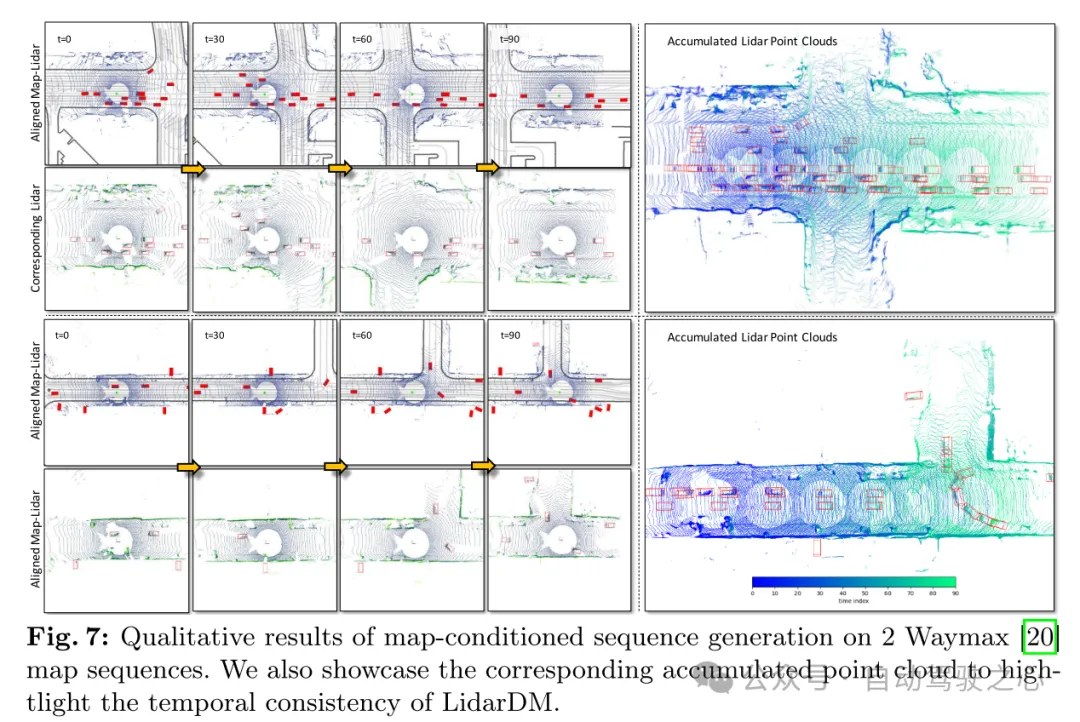
Figure 7: Qualitative results of map-conditioned sequence generation on 2 Waymax [20] map sequences. This paper also shows the corresponding cumulative point cloud to highlight the temporal consistency of LidarDM.

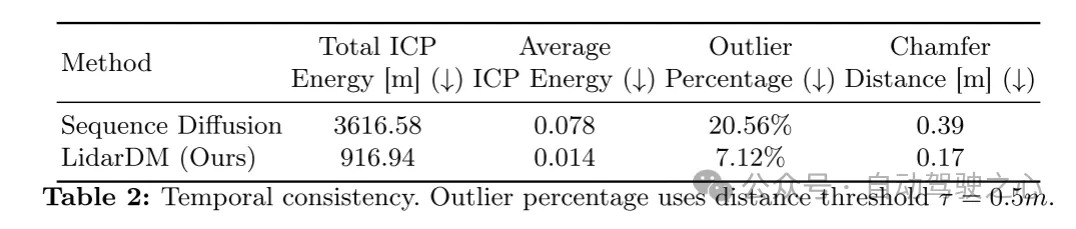


Summary:
This paper proposes LidarDM, which is a novel layout-based Conditional latent diffusion models for generating realistic lidar point clouds. Our approach frames the problem as a joint 4D world creation and perception data generation task, and develops a novel latent diffusion model to create 3D scenes. The resulting point cloud video is realistic, coherent, and layout-aware.
The above is the detailed content of New ideas for LiDAR simulation | LidarDM: Helps generate 4D world, simulation killer~. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to install deepseek
Feb 19, 2025 pm 05:48 PM
How to install deepseek
Feb 19, 2025 pm 05:48 PM
There are many ways to install DeepSeek, including: compile from source (for experienced developers) using precompiled packages (for Windows users) using Docker containers (for most convenient, no need to worry about compatibility) No matter which method you choose, Please read the official documents carefully and prepare them fully to avoid unnecessary trouble.
 Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
Summary of FAQs for DeepSeek usage
Feb 19, 2025 pm 03:45 PM
DeepSeekAI Tool User Guide and FAQ DeepSeek is a powerful AI intelligent tool. This article will answer some common usage questions to help you get started quickly. FAQ: The difference between different access methods: There is no difference in function between web version, App version and API calls, and App is just a wrapper for web version. The local deployment uses a distillation model, which is slightly inferior to the full version of DeepSeek-R1, but the 32-bit model theoretically has 90% full version capability. What is a tavern? SillyTavern is a front-end interface that requires calling the AI model through API or Ollama. What is breaking limit
 What are the AI tools?
Nov 29, 2024 am 11:11 AM
What are the AI tools?
Nov 29, 2024 am 11:11 AM
AI tools include: Doubao, ChatGPT, Gemini, BlenderBot, etc.
 gateio official download address gateio official download Android version
Feb 21, 2025 pm 03:00 PM
gateio official download address gateio official download Android version
Feb 21, 2025 pm 03:00 PM
Gate.io provides an official mobile application that allows users to download the Android version through the following steps: visit the official website, click the "Download" button, select the "Android" option, scan the QR code or click the "Google Play" link. Currently, Gate.io does not provide an official iOS mobile app. Users can access the website through a mobile web browser or install the Android version on iOS devices through an Android emulator or third-party services.
 What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
What are the Grayscale Encryption Trust Funds? Common Grayscale Encryption Trust Funds Inventory
Mar 05, 2025 pm 12:33 PM
Grayscale Investment: The channel for institutional investors to enter the cryptocurrency market. Grayscale Investment Company provides digital currency investment services to institutions and investors. It allows investors to indirectly participate in cryptocurrency investment through the form of trust funds. The company has launched several crypto trusts, which has attracted widespread market attention, but the impact of these funds on token prices varies significantly. This article will introduce in detail some of Grayscale's major crypto trust funds. Grayscale Major Crypto Trust Funds Available at a glance Grayscale Investment (founded by DigitalCurrencyGroup in 2013) manages a variety of crypto asset trust funds, providing institutional investors and high-net-worth individuals with compliant investment channels. Its main funds include: Zcash (ZEC), SOL,
 As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
As top market makers enter the crypto market, what impact will Castle Securities have on the industry?
Mar 04, 2025 pm 08:03 PM
The entry of top market maker Castle Securities into Bitcoin market maker is a symbol of the maturity of the Bitcoin market and a key step for traditional financial forces to compete for future asset pricing power. At the same time, for retail investors, it may mean the gradual weakening of their voice. On February 25, according to Bloomberg, Citadel Securities is seeking to become a liquidity provider for cryptocurrencies. The company aims to join the list of market makers on various exchanges, including exchanges operated by CoinbaseGlobal, BinanceHoldings and Crypto.com, people familiar with the matter said. Once approved by the exchange, the company initially planned to set up a market maker team outside the United States. This move is not only a sign
 Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: How to change the new AI economy by parsing the new ElizaOS v2 architecture?
Mar 04, 2025 pm 07:00 PM
ElizaOSv2: Empowering AI and leading the new economy of Web3. AI is evolving from auxiliary tools to independent entities. ElizaOSv2 plays a key role in it, which gives AI the ability to manage funds and operate Web3 businesses. This article will dive into the key innovations of ElizaOSv2 and how it shapes an AI-driven future economy. AI Automation: Going to independently operate ElizaOS was originally an AI framework focusing on Web3 automation. v1 version allows AI to interact with smart contracts and blockchain data, while v2 version achieves significant performance improvements. Instead of just executing simple instructions, AI can independently manage workflows, operate business and develop financial strategies. Architecture upgrade: Enhanced A
 Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Researchers from Shanghai Jiaotong University, Shanghai AILab and the Chinese University of Hong Kong have launched the Visual-RFT (Visual Enhancement Fine Tuning) open source project, which requires only a small amount of data to significantly improve the performance of visual language big model (LVLM). Visual-RFT cleverly combines DeepSeek-R1's rule-based reinforcement learning approach with OpenAI's reinforcement fine-tuning (RFT) paradigm, successfully extending this approach from the text field to the visual field. By designing corresponding rule rewards for tasks such as visual subcategorization and object detection, Visual-RFT overcomes the limitations of the DeepSeek-R1 method being limited to text, mathematical reasoning and other fields, providing a new way for LVLM training. Vis
