

Understand Tokenization in one article!

Language models reason about text. Text is usually in the form of strings, but the input of the model can only be numbers, so the text needs to be converted into numerical form.
Tokenization is a basic task of natural language processing. It can divide a continuous text sequence (such as sentences, paragraphs, etc.) into a character sequence (such as words, phrases, characters, punctuation, etc.) according to specific needs. unit), where the units are called tokens or words.
According to the specific process shown in the figure below, first divide the text sentences into units, then digitize the single elements (map them into vectors), then input these vectors into the model for encoding, and finally output them to Downstream tasks further obtain the final result.
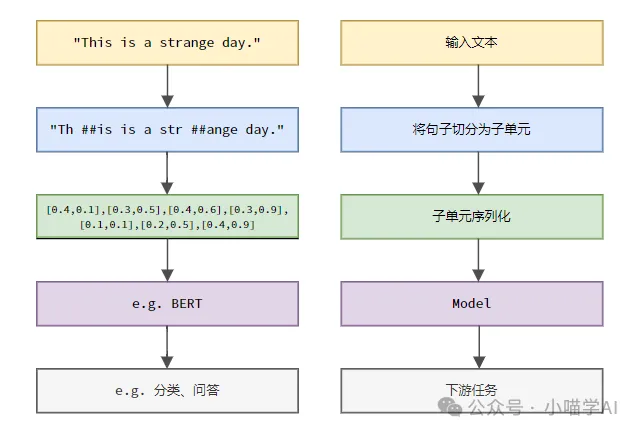
Text Segmentation
According to the granularity of text segmentation, Tokenization can be divided into three categories: word granular Tokenization, character granular Tokenization, and subword granular Tokenization.
1. Word granularity Tokenization
Word granularity Tokenization is the most intuitive word segmentation method, which means to segment the text according to vocabulary words. For example:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
In this example, the text is divided into independent words, each word is used as a token, and the punctuation mark '.' is also regarded as an independent token. .
Chinese text is usually segmented according to the standard vocabulary collection included in the dictionary or the phrases, idioms, proper nouns, etc. recognized through the word segmentation algorithm.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
This Chinese text is divided into five words: "I", "like", "eat", "apple" and period ".", each word serves as a token.
2. Character granularity Tokenization
Character granularity Tokenization divides the text into the smallest character unit, that is, each character is treated as a separate token. For example:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
Character granularity Tokenization in Chinese is to segment the text according to each independent Chinese character.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
3.subword granularity Tokenization
subword granularity Tokenization is between word granularity and character granularity. It divides the text into between words and characters. Subwords serve as tokens. Common subword Tokenization methods include Byte Pair Encoding (BPE), WordPiece, etc. These methods automatically generate a word segmentation dictionary by counting substring frequencies in text data, which can effectively deal with the problem of out-of-service words (OOV) while maintaining a certain semantic integrity.
helloworld
Assume that after training with the BPE algorithm, the generated subword dictionary contains the following entries:
h, e, l, o, w, r, d, hel, low, wor, orld
Subword granularity Tokenized results:
['hel', 'low', 'orld']
Here, "helloworld" is divided into three sub-words "hel", "low", and "orld", which are high-frequency substring combinations that have appeared in the dictionary. This segmentation method can not only handle unknown words (for example, "helloworld" is not a standard English word), but also retain certain semantic information (the combination of sub-words can restore the original word).
In Chinese, subword granular Tokenization also divides the text into subwords between Chinese characters and words as tokens. For example:
我喜欢吃苹果
Assume that after training with the BPE algorithm, the generated subword dictionary contains the following entries:
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
Subword granularity Tokenized results:
['我', '喜欢', '吃', '苹果']
In this example, "I like to eat apples" is divided into four sub-words "I", "like", "eat" and "apple". These sub-words All appear in the dictionary. Although Chinese characters are not further combined like English sub-words, the sub-word Tokenization method has considered high-frequency word combinations, such as "I like" and "eat apples" when generating the dictionary. This segmentation method maintains word-level semantic information while processing unknown words.
Indexing
Assume that the corpus or vocabulary has been created as follows.
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}You can find the index of each token in the sequence in the vocabulary.
indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
Output: [0, 1, 2, 3, 4].
The above is the detailed content of Understand Tokenization in one article!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
When converting strings to objects in Vue.js, JSON.parse() is preferred for standard JSON strings. For non-standard JSON strings, the string can be processed by using regular expressions and reduce methods according to the format or decoded URL-encoded. Select the appropriate method according to the string format and pay attention to security and encoding issues to avoid bugs.
 Vue and Element-UI cascade drop-down box v-model binding
Apr 07, 2025 pm 08:06 PM
Vue and Element-UI cascade drop-down box v-model binding
Apr 07, 2025 pm 08:06 PM
Vue and Element-UI cascaded drop-down boxes v-model binding common pit points: v-model binds an array representing the selected values at each level of the cascaded selection box, not a string; the initial value of selectedOptions must be an empty array, not null or undefined; dynamic loading of data requires the use of asynchronous programming skills to handle data updates in asynchronously; for huge data sets, performance optimization techniques such as virtual scrolling and lazy loading should be considered.
 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Summary: There are the following methods to convert Vue.js string arrays into object arrays: Basic method: Use map function to suit regular formatted data. Advanced gameplay: Using regular expressions can handle complex formats, but they need to be carefully written and considered. Performance optimization: Considering the large amount of data, asynchronous operations or efficient data processing libraries can be used. Best practice: Clear code style, use meaningful variable names and comments to keep the code concise.
 How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
In order to set the timeout for Vue Axios, we can create an Axios instance and specify the timeout option: In global settings: Vue.prototype.$axios = axios.create({ timeout: 5000 }); in a single request: this.$axios.get('/api/users', { timeout: 10000 }).
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
MySQL performance optimization needs to start from three aspects: installation configuration, indexing and query optimization, monitoring and tuning. 1. After installation, you need to adjust the my.cnf file according to the server configuration, such as the innodb_buffer_pool_size parameter, and close query_cache_size; 2. Create a suitable index to avoid excessive indexes, and optimize query statements, such as using the EXPLAIN command to analyze the execution plan; 3. Use MySQL's own monitoring tool (SHOWPROCESSLIST, SHOWSTATUS) to monitor the database health, and regularly back up and organize the database. Only by continuously optimizing these steps can the performance of MySQL database be improved.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
