
 Technology peripherals
AI
Directly expands to infinite length, Google Infini-Transformer ends the context length debate
Technology peripherals
AI
Directly expands to infinite length, Google Infini-Transformer ends the context length debate
Directly expands to infinite length, Google Infini-Transformer ends the context length debate

I wonder if Gemini 1.5 Pro uses this technology.
Google has made another big move and released the next generation Transformer model Infini-Transformer.
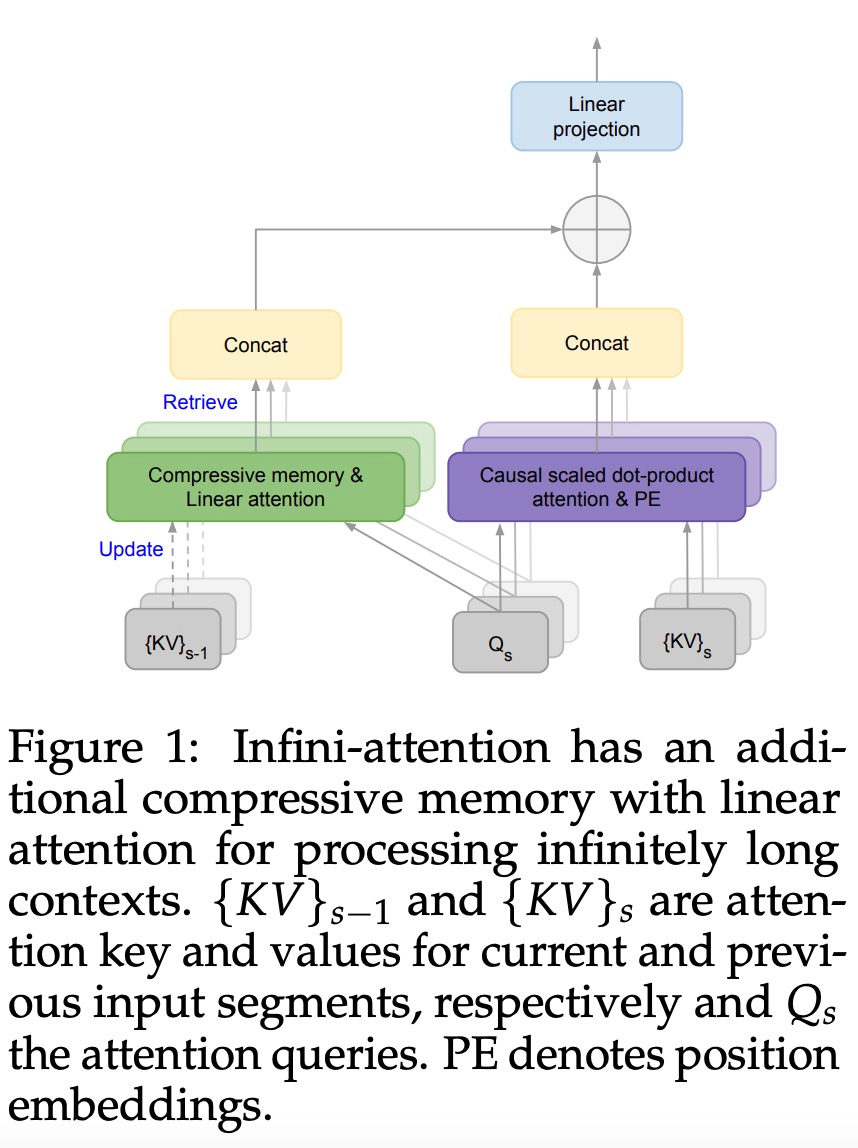
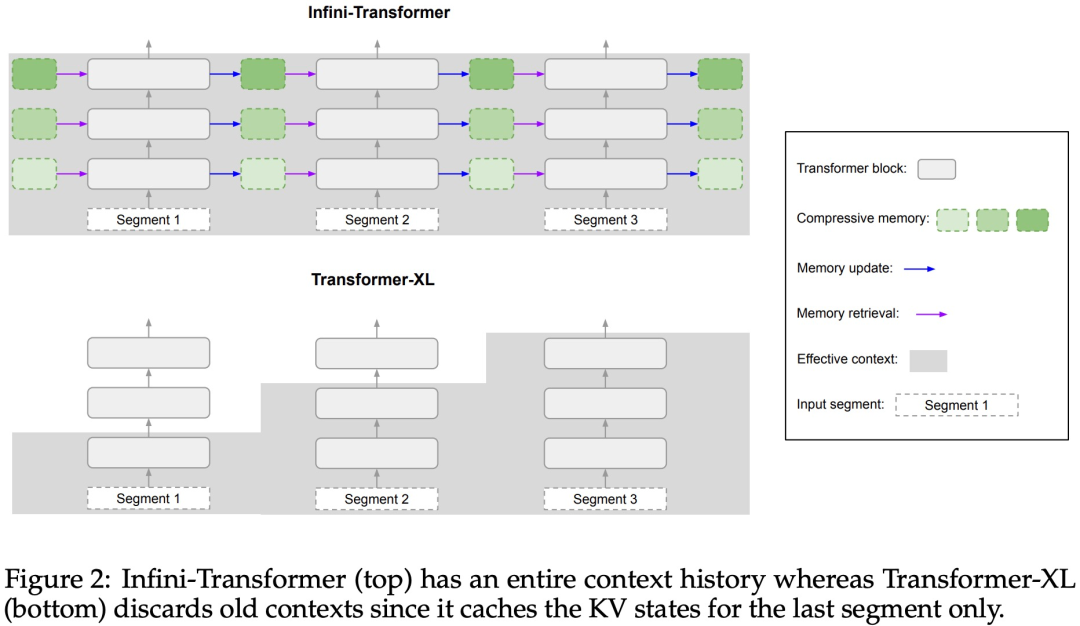
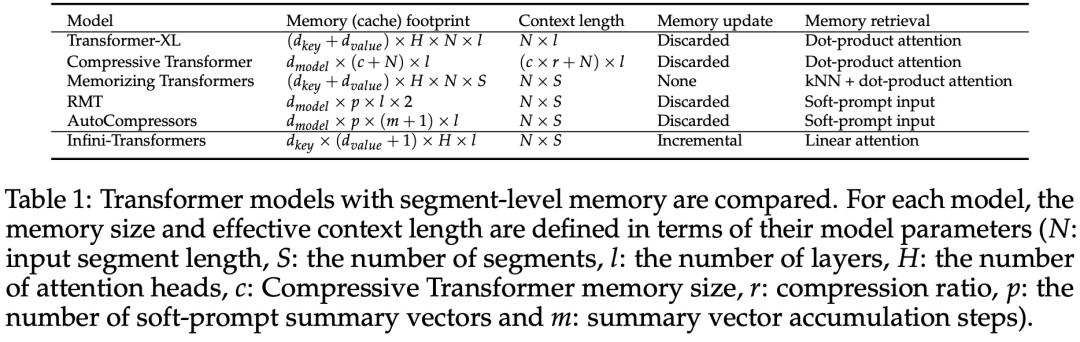
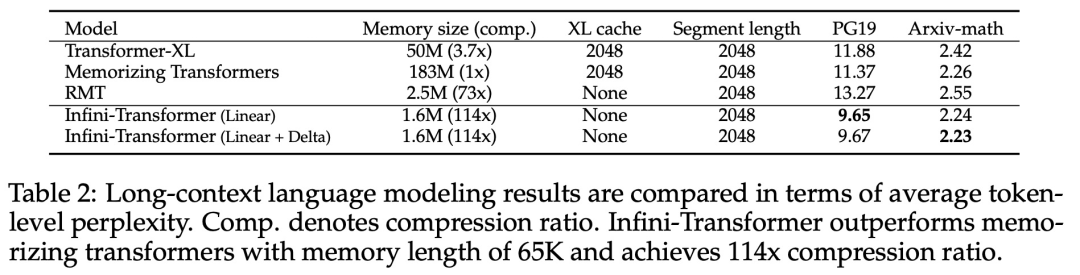
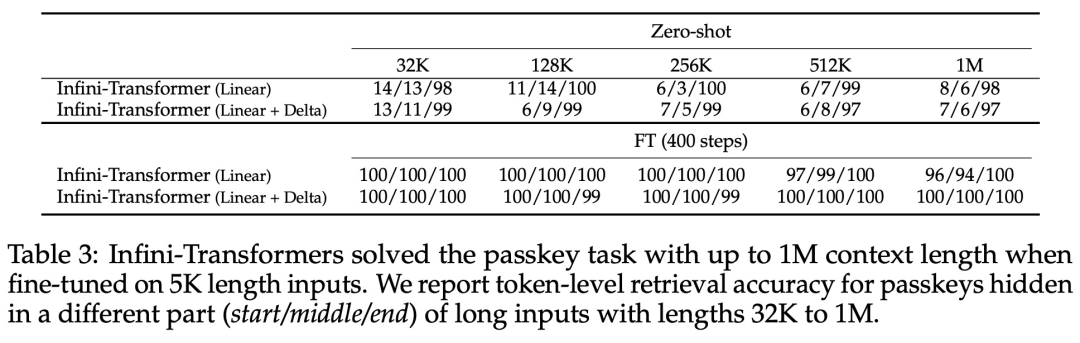
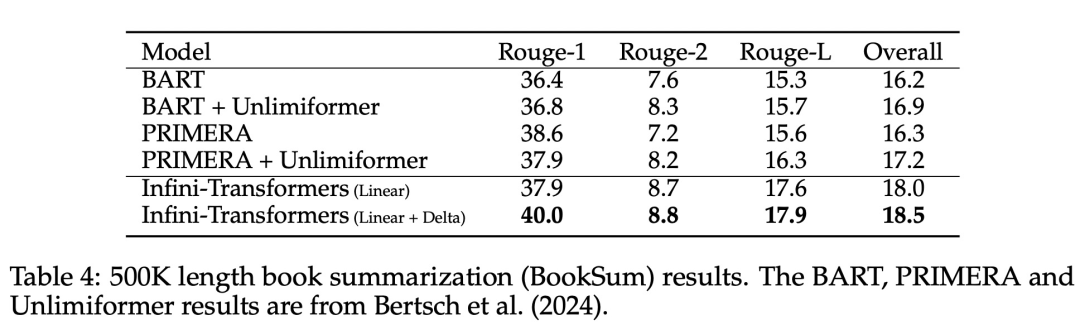
Introduces a practical and powerful attention Force mechanism Infini-attention - with long-term compressed memory and local causal attention, can be used to effectively model long-term and short-term context dependencies; Infini-attention has a standard scaling dot product Attention (standard scaled dot-product attention) is minimally changed and is designed to support plug-and-play continuous pre-training and long-context adaptation; This approach enables Transformer LLM is capable of processing extremely long inputs in a streaming manner, scaling to infinitely long contexts with limited memory and computing resources.

- ## Paper link: https://arxiv.org/pdf/2404.07143.pdf
- Paper title: Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention


The above is the detailed content of Directly expands to infinite length, Google Infini-Transformer ends the context length debate. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
This article recommends the top ten cryptocurrency trading platforms worth paying attention to, including Binance, OKX, Gate.io, BitFlyer, KuCoin, Bybit, Coinbase Pro, Kraken, BYDFi and XBIT decentralized exchanges. These platforms have their own advantages in terms of transaction currency quantity, transaction type, security, compliance, and special features. For example, Binance is known for its largest transaction volume and abundant functions in the world, while BitFlyer attracts Asian users with its Japanese Financial Hall license and high security. Choosing a suitable platform requires comprehensive consideration based on your own trading experience, risk tolerance and investment preferences. Hope this article helps you find the best suit for yourself
 Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Web Page Login Latest version gateio official website entrance
Mar 04, 2025 pm 11:48 PM
A detailed introduction to the login operation of the Sesame Open Exchange web version, including login steps and password recovery process. It also provides solutions to common problems such as login failure, unable to open the page, and unable to receive verification codes to help you log in to the platform smoothly.
 How to register and download the latest app on Bitget official website
Mar 05, 2025 am 07:54 AM
How to register and download the latest app on Bitget official website
Mar 05, 2025 am 07:54 AM
This guide provides detailed download and installation steps for the official Bitget Exchange app, suitable for Android and iOS systems. The guide integrates information from multiple authoritative sources, including the official website, the App Store, and Google Play, and emphasizes considerations during download and account management. Users can download the app from official channels, including app store, official website APK download and official website jump, and complete registration, identity verification and security settings. In addition, the guide covers frequently asked questions and considerations, such as
 Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
Tutorial on how to register, use and cancel Ouyi okex account
Mar 31, 2025 pm 04:21 PM
This article introduces in detail the registration, use and cancellation procedures of Ouyi OKEx account. To register, you need to download the APP, enter your mobile phone number or email address to register, and complete real-name authentication. The usage covers the operation steps such as login, recharge and withdrawal, transaction and security settings. To cancel an account, you need to contact Ouyi OKEx customer service, provide necessary information and wait for processing, and finally obtain the account cancellation confirmation. Through this article, users can easily master the complete life cycle management of Ouyi OKEx account and conduct digital asset transactions safely and conveniently.
 CS-Week 3
Apr 04, 2025 am 06:06 AM
CS-Week 3
Apr 04, 2025 am 06:06 AM
Algorithms are the set of instructions to solve problems, and their execution speed and memory usage vary. In programming, many algorithms are based on data search and sorting. This article will introduce several data retrieval and sorting algorithms. Linear search assumes that there is an array [20,500,10,5,100,1,50] and needs to find the number 50. The linear search algorithm checks each element in the array one by one until the target value is found or the complete array is traversed. The algorithm flowchart is as follows: The pseudo-code for linear search is as follows: Check each element: If the target value is found: Return true Return false C language implementation: #include#includeintmain(void){i
 Ouyi okx official version download APP entrance
Mar 04, 2025 pm 11:24 PM
Ouyi okx official version download APP entrance
Mar 04, 2025 pm 11:24 PM
This article provides the latest download information about the official version of Ouyi OKX. This article will guide readers on how to securely and conveniently access the exchange's Android and iOS apps. This article contains step-by-step instructions and important tips designed to help readers easily download and install the Ouyi OKX app.
 How to optimize jieba word segmentation to improve the keyword extraction effect of scenic spot comments?
Apr 01, 2025 pm 06:24 PM
How to optimize jieba word segmentation to improve the keyword extraction effect of scenic spot comments?
Apr 01, 2025 pm 06:24 PM
How to optimize jieba word segmentation to improve keyword extraction of scenic spot comments? When using jieba word segmentation to process scenic spot comment data, if the word segmentation results are ignored...
 What are the free market software and apps abroad?
Mar 04, 2025 pm 07:57 PM
What are the free market software and apps abroad?
Mar 04, 2025 pm 07:57 PM
This article introduces several commonly used free financial market software and APPs abroad, so that investors can understand global market trends in a timely manner and reduce investment costs. The article covers stock tracking (Yahoo Finance, Google Finance, Investing.com, MarketWatch, TradingView), Forex trading (MetaTrader 4/5, Forex Factory), and cryptocurrency markets (CoinMarketCap, CoinGecko). Although these free tools are convenient and practical, you need to be aware of the possible delay in data and be cautious about advertising and privacy issues. You also need to understand free
