
 Technology peripherals
AI
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
Technology peripherals
AI
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!
The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!

Ollama is a super practical tool that allows you to easily run open source models such as Llama 2, Mistral, and Gemma locally. In this article, I will introduce how to use Ollama to vectorize text. If you don't have Ollama installed locally, you can read this article.
In this article we will use the nomic-embed-text[2] model. It is a text encoder that outperforms OpenAI text-embedding-ada-002 and text-embedding-3-small on short context and long context tasks.
Start the nomic-embed-text service
After you have successfully installed ollama, use the following command to pull the nomic-embed-text model:
ollama pull nomic-embed-text
After successfully pulling the model, enter the following command in the terminal to start the ollama service:
ollama serve
After that, we can use curl to verify whether the embedding service can run normally:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Using the nomic-embed-text service
Next, we will introduce how to use langchainjs and the nomic-embed-text service to perform embeddings operations on local txt documents . The corresponding process is shown in the figure below:
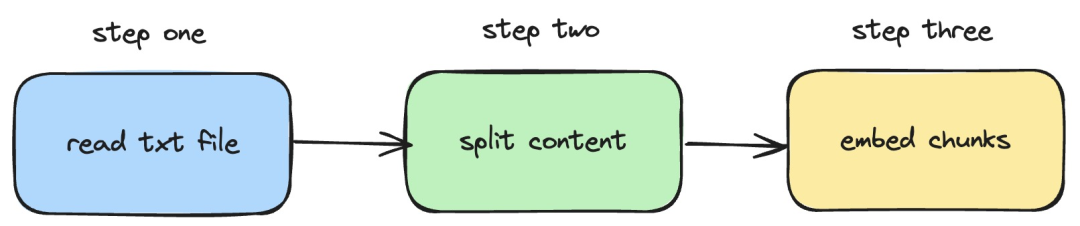 Picture
Picture
1. Read the local txt file
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}In the above code, we define a load function, which internally uses the TextLoader provided by langchainjs to read the local txt document.
2. Split the txt content into text blocks
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}In the above code, we use RecursiveCharacterTextSplitter to cut the read txt text and set each text The block size is 500.
3. Perform embeddings operations on text blocks
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}In the above code, we define an embedding function, in which the load defined earlier will be called and split function. Then traverse the generated text block and call the locally started nomic-embed-text embedding service. The sendRequest function is used to send embedding requests. Its implementation code is very simple, which is to use the fetch API to call the existing REST API.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Next, we continue to define an embedTxtFile function, directly call the existing embedding function inside the function and add corresponding exception handling.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Finally, we use the npx esno src/index.ts command to quickly execute the local ts file. If the code in index.ts is successfully executed, the following results will be output in the terminal:
 Picture
Picture
In fact, in addition to using the above method, We can also directly use the [OllamaEmbeddings](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") object in the @langchain/community module, which internally encapsulates the logic of calling the ollama embedding service:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);This article introduces the process of establishing a knowledge base content index when developing a RAG system. If you don’t know about the RAG system, you can read related articles.
References
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/ library/nomic-embed-text
The above is the detailed content of The local running performance of the Embedding service exceeds that of OpenAI Text-Embedding-Ada-002, which is so convenient!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
Yolov10: Detailed explanation, deployment and application all in one place!
Jun 07, 2024 pm 12:05 PM
1. Introduction Over the past few years, YOLOs have become the dominant paradigm in the field of real-time object detection due to its effective balance between computational cost and detection performance. Researchers have explored YOLO's architectural design, optimization goals, data expansion strategies, etc., and have made significant progress. At the same time, relying on non-maximum suppression (NMS) for post-processing hinders end-to-end deployment of YOLO and adversely affects inference latency. In YOLOs, the design of various components lacks comprehensive and thorough inspection, resulting in significant computational redundancy and limiting the capabilities of the model. It offers suboptimal efficiency, and relatively large potential for performance improvement. In this work, the goal is to further improve the performance efficiency boundary of YOLO from both post-processing and model architecture. to this end
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
 Tsinghua University took over and YOLOv10 came out: the performance was greatly improved and it was on the GitHub hot list
Jun 06, 2024 pm 12:20 PM
Tsinghua University took over and YOLOv10 came out: the performance was greatly improved and it was on the GitHub hot list
Jun 06, 2024 pm 12:20 PM
The benchmark YOLO series of target detection systems has once again received a major upgrade. Since the release of YOLOv9 in February this year, the baton of the YOLO (YouOnlyLookOnce) series has been passed to the hands of researchers at Tsinghua University. Last weekend, the news of the launch of YOLOv10 attracted the attention of the AI community. It is considered a breakthrough framework in the field of computer vision and is known for its real-time end-to-end object detection capabilities, continuing the legacy of the YOLO series by providing a powerful solution that combines efficiency and accuracy. Paper address: https://arxiv.org/pdf/2405.14458 Project address: https://github.com/THU-MIG/yo
 Performance comparison of different Java frameworks
Jun 05, 2024 pm 07:14 PM
Performance comparison of different Java frameworks
Jun 05, 2024 pm 07:14 PM
Performance comparison of different Java frameworks: REST API request processing: Vert.x is the best, with a request rate of 2 times SpringBoot and 3 times Dropwizard. Database query: SpringBoot's HibernateORM is better than Vert.x and Dropwizard's ORM. Caching operations: Vert.x's Hazelcast client is superior to SpringBoot and Dropwizard's caching mechanisms. Suitable framework: Choose according to application requirements. Vert.x is suitable for high-performance web services, SpringBoot is suitable for data-intensive applications, and Dropwizard is suitable for microservice architecture.
 ChatGPT is now available for macOS with the release of a dedicated app
Jun 27, 2024 am 10:05 AM
ChatGPT is now available for macOS with the release of a dedicated app
Jun 27, 2024 am 10:05 AM
Open AI’s ChatGPT Mac application is now available to everyone, having been limited to only those with a ChatGPT Plus subscription for the last few months. The app installs just like any other native Mac app, as long as you have an up to date Apple S
 How to optimize the performance of multi-threaded programs in C++?
Jun 05, 2024 pm 02:04 PM
How to optimize the performance of multi-threaded programs in C++?
Jun 05, 2024 pm 02:04 PM
Effective techniques for optimizing C++ multi-threaded performance include limiting the number of threads to avoid resource contention. Use lightweight mutex locks to reduce contention. Optimize the scope of the lock and minimize the waiting time. Use lock-free data structures to improve concurrency. Avoid busy waiting and notify threads of resource availability through events.
 Google Gemini 1.5 technical report: Easily prove Mathematical Olympiad questions, the Flash version is 5 times faster than GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Google Gemini 1.5 technical report: Easily prove Mathematical Olympiad questions, the Flash version is 5 times faster than GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
In February this year, Google launched the multi-modal large model Gemini 1.5, which greatly improved performance and speed through engineering and infrastructure optimization, MoE architecture and other strategies. With longer context, stronger reasoning capabilities, and better handling of cross-modal content. This Friday, Google DeepMind officially released the technical report of Gemini 1.5, which covers the Flash version and other recent upgrades. The document is 153 pages long. Technical report link: https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf In this report, Google introduces Gemini1
