
 Technology peripherals
AI
Al Agent--An important implementation direction in the era of large models
Technology peripherals
AI
Al Agent--An important implementation direction in the era of large models
Al Agent--An important implementation direction in the era of large models

1. Overall architecture of LLM-based Agent
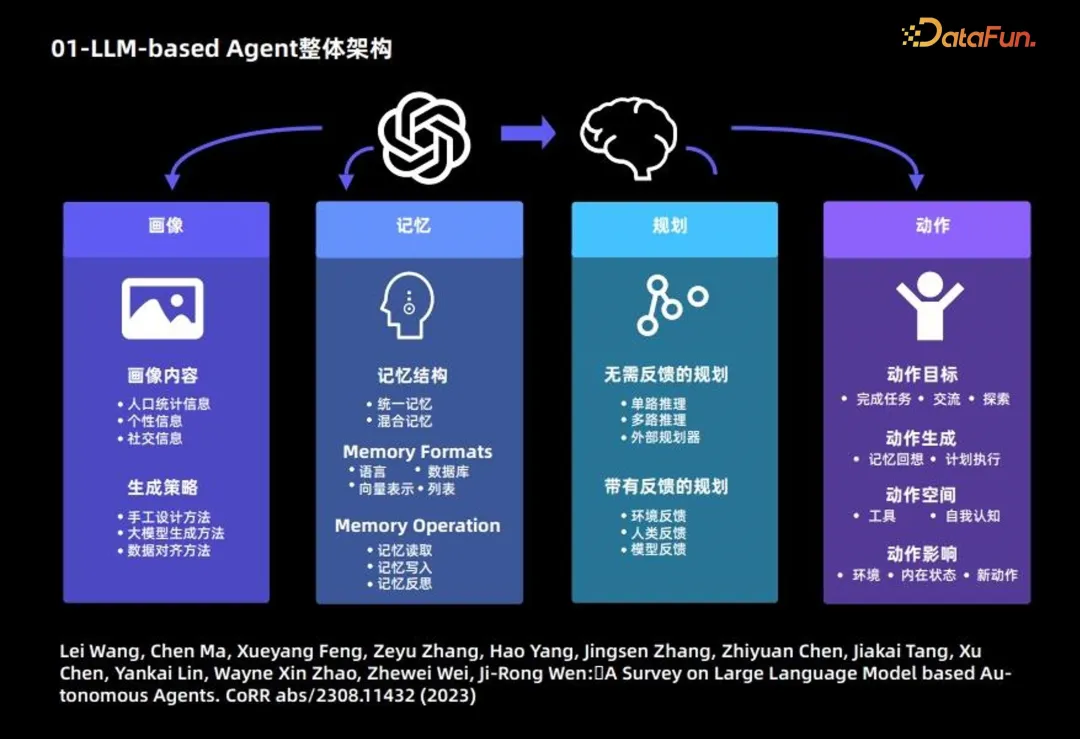
The composition of the large language model Agent is mainly divided into the following 4 Modules:
1. Portrait module: mainly describes the background information of the Agent
The following introduces the main content and generation strategy of the portrait module.
Portrait content is mainly based on 3 types of information: demographic information, personality information and social information.
Generation strategy: 3 strategies are mainly used to generate portrait content:
- Manual design method: Specify by yourself method to write the content of the user portrait into the prompt of the large model; suitable for situations where the number of Agents is relatively small;
- Large model generation method: first specify Use a small number of portraits as examples, and then use a large language model to generate more portraits; suitable for situations with a large number of Agents;
- Data alignment method: required Based on the background information of the characters in the pre-specified data set as the prompt of the large language model, corresponding predictions are made.
2. Memory module: The main purpose is to record Agent behavior and provide support for future Agent decisions
Memory Structure:
- Unified memory: only short-term memory is considered, long-term memory is not considered.
- Hybrid Memory: A combination of long-term and short-term memory.
#Memory form: Mainly based on the following 4 forms.
- Language
- ##Database
- Vector representation
- List
Memory content: Common following 3 operations:
- Memory reading
- Memory writing
- Memory reflection
3. Planning module
- Planning without feedback: The large language model does not require feedback from the external environment during the reasoning process. This type of planning is further subdivided into three types: single-channel based reasoning, which uses a large language model only once to completely output the steps of reasoning; multi-channel based reasoning, drawing on the idea of crowdsourcing, allowing the large language model to generate multiple Reason the path and determine the best path; borrow an external planner.
- Planning with feedback: This planning method requires feedback from the external environment, while the large language model requires feedback from the environment for the next step and subsequent planning. . Providers of this type of planning feedback come from three sources: environmental feedback, human feedback, and model feedback.
4. Action module
- Action goal: The goal of some Agents is to complete a certain There are several tasks, some are communication and some are exploration.
- Action generation: Some agents rely on memory recall to generate actions, and some perform specific actions according to the original plan.
- Action space: Some action spaces are a collection of tools, and some are based on the large language model's own knowledge, considering the entire action space from the perspective of self-awareness.
- Action impact: including the impact on the environment, the impact on the internal state, and the impact on new actions in the future.
The above is the overall framework of Agent. For more information, please refer to the following papers:
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, Ji-Rong Wen: A Survey on Large Language Model based Autonomous Agents. CoRR abs /2308.11432 (2023)
2. Key & Difficult Issues of LLM-based Agent
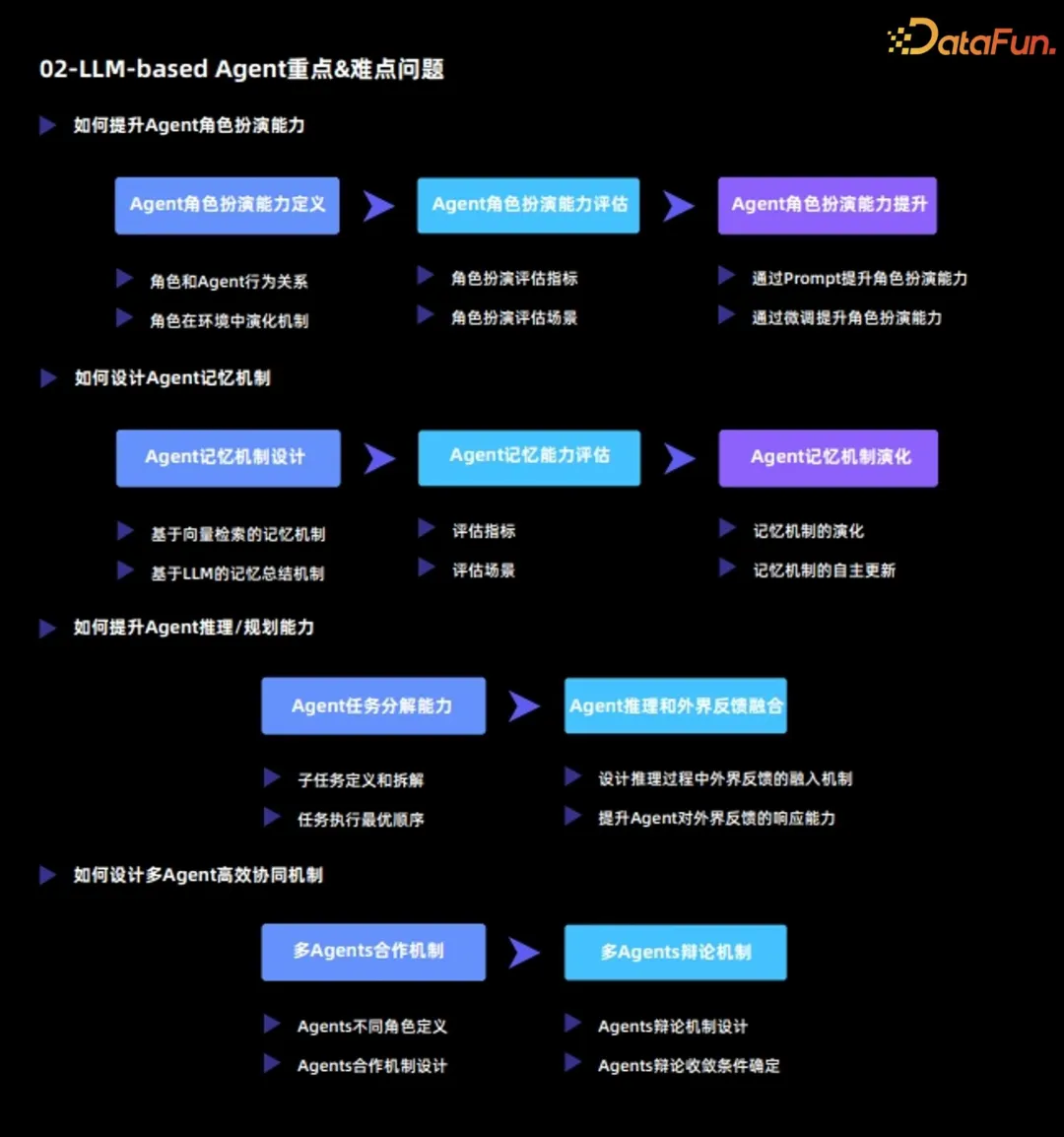
##The key and difficult issues of current large language model Agent mainly include:
1. How to improve Agent’s role-playing ability
The most important function of Agent is to complete specific tasks by playing a certain role , or complete various simulations, so the Agent's role-playing ability is crucial.
(1) Agent role-playing ability definition
Agent role-playing ability is divided into two dimensions:
- The behavioral relationship between the role and the Agent
- The evolution mechanism of the role in the environment
(2)Agent role-playing ability evaluation
After defining the role-playing ability, the next step is to evaluate the Agent role-playing ability from the following two aspects :
- Role-playing evaluation index
- Role-playing evaluation scenario
(3) Improvement of Agent’s role-playing ability
On the basis of the evaluation, the Agent’s role-playing ability needs to be further improved. There are the following two methods:
- Improve role-playing capabilities through prompts: The essence of this method is to stimulate the ability of the original large language model by designing prompts;
- Improve role-playing capabilities through fine-tuning: This method is usually based on external data and re-finetune the large language model to improve role-playing capabilities.
2. How to design the Agent memory mechanism
The biggest difference between Agent and large language model is that Agent can The environment is constantly undergoing self-evolution and self-learning; in this, the memory mechanism plays a very important role. Analyze the Agent's memory mechanism from three dimensions:
(1) Agent memory mechanism design
The following two common memory mechanisms are common:
- Memory mechanism based on vector retrieval
- Memory mechanism based on LLM summary
(2) Agent memory ability evaluation
To evaluate the Agent’s memory ability, it is mainly necessary to determine the following two points:
- Evaluation indicators
- Evaluation scenarios
(3) Agent memory mechanism evolution
Finally, the evolution of Agent memory mechanism needs to be analyzed, including:
- The evolution of memory mechanism
- Autonomous update of memory mechanism
3. How to improve Agent’s reasoning/planning ability
(1) Agent’s task decomposition ability
- Sub-task definition and disassembly
- Optimal order of task execution
(2) Integration of Agent reasoning and external feedback
- Design the integration mechanism of external feedback during the reasoning process: let the Agent and the environment form an interactive whole;
- Improve the Agent's ability to respond to external feedback: On the one hand, the Agent needs to truly respond to the external environment, and on the other hand, the Agent needs to be able to ask questions and seek solutions to the external environment.
4. How to design an efficient multi-Agent collaboration mechanism
(1) Multi-Agents collaboration mechanism
- Agents different role definition
- Agents cooperation mechanism design
(2) Multi-Agents Debate Mechanism
- Agents Debate Mechanism Design
- Agents Debate Convergence Condition Determination
##3. Based on the big User behavior simulation agent of language model
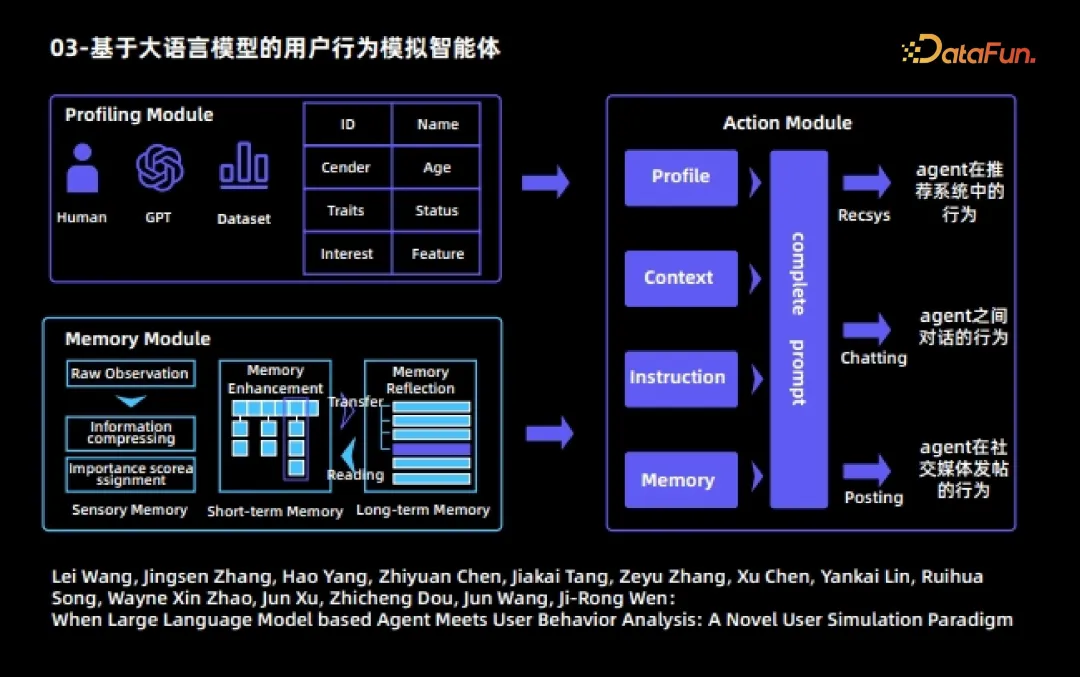
The following will give some actual cases of Agent. The first is a user behavior simulation agent based on a large language model. This agent is also an early work in combining large language model agents with user behavior analysis. In this work, each Agent is divided into three modules:
1. The portrait module
specifies different attributes for different Agents. Such as ID, name, occupation, age, interests and characteristics, etc.
2. Memory module
The memory module includes three sub-modules
(1) Feeling Memory
(2) Short-term memory
- After processing the objectively observed raw observation, the amount of information is generated Higher observations are stored in short-term memory;
- #The storage time of short-term memory contents is relatively short
(3) Long-term memory
- #The content of short-term memory will be automatically transferred to long-term memory after repeated triggering and activation.
- The storage time of long-term memory contents is relatively long
- The contents of long-term memory will be stored according to the Existing memories are subject to independent reflection, sublimation and refinement.
3. Action module
Each Agent can perform three actions:
- Agent’s behavior in the recommendation system, including watching movies, finding the next page, and leaving the recommendation system;
- ## The behavior of conversations between #Agents;
- #Agent’s behavior of posting on social media.
For more information, please refer to the following papers:
Lei Wang, Jingsen Zhang, Hao Yang, Zhiyuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Ruihua Song, Wayne Xin Zhao, Jun Xu, Zhicheng Dou, Jun Wang, Ji-Rong Wen :When Large Language Model based Agent Meets User Behavior Analysis: A Novel User Simulation Paradigm
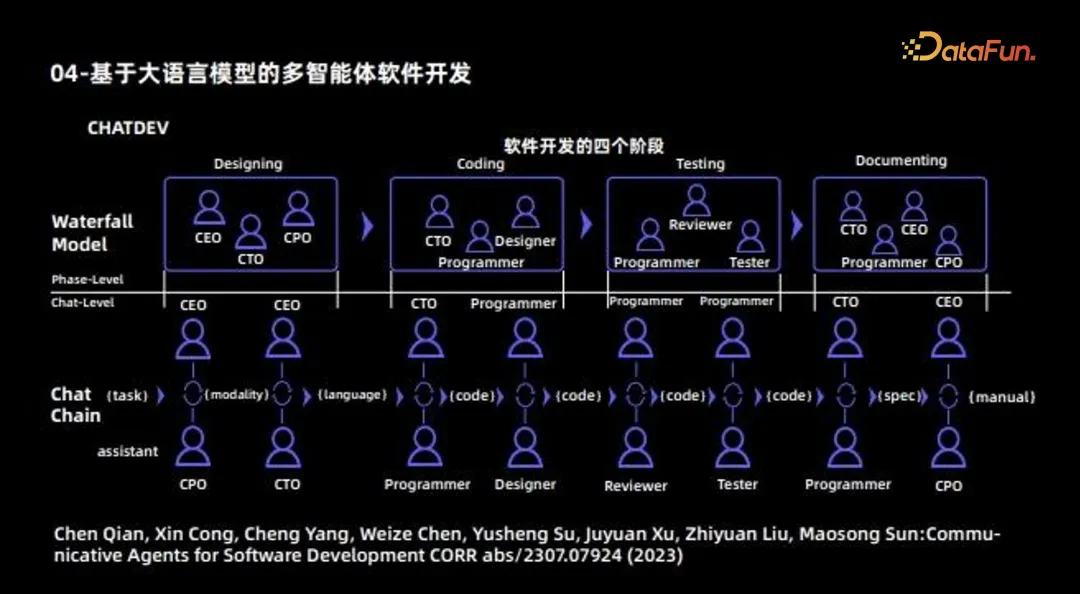
The next Agent example is software development using multi-Agent. This work is also an early work of multi-Agent cooperation, and its main purpose is to use different Agents to develop a complete software. Therefore, it can be regarded as a software company, and different Agents will play different roles: some Agents are responsible for design, including roles such as CEO, CTO, CPO, etc.; some Agents are responsible for coding, and some Agents are mainly responsible for testing; in addition, there are Some agents are responsible for writing documents. In this way, different Agents are responsible for different tasks; finally, the cooperation mechanism between Agents is coordinated and updated through communication, and finally a complete software development process is completed.
Agents of large language models can currently be divided into two major directions: In addition, the current large language model Agent has the following two pain points: The above is the content shared this time, thank you all. 4. Based on Multi-agent software development for large language models
#5. Future direction of LLM-based Agent

Solve specific tasks, such as MetaGPT, ChatDev, Ghost, DESP, etc.
This type of Agent should ultimately be a "superman" aligned with the correct values of mankind, which has two "qualifiers":
Aligned correctly Human values;
#beyond the capabilities of ordinary people.
The abilities required by this type of Agent are completely opposite to the first type. .
Allow Agent to present a variety of values;
We hope that Agent will try to conform to ordinary people instead of going beyond ordinary people.
Illusion problem
Since the Agent needs to continuously interact with the environment, the hallucinations of each step will be accumulated, which will produce a cumulative effect and make the problem more serious; therefore, the hallucination problem of large models needs further attention here. The solutions include:
Design an efficient human-machine collaboration framework;
Design Plan an efficient human intervention mechanism.
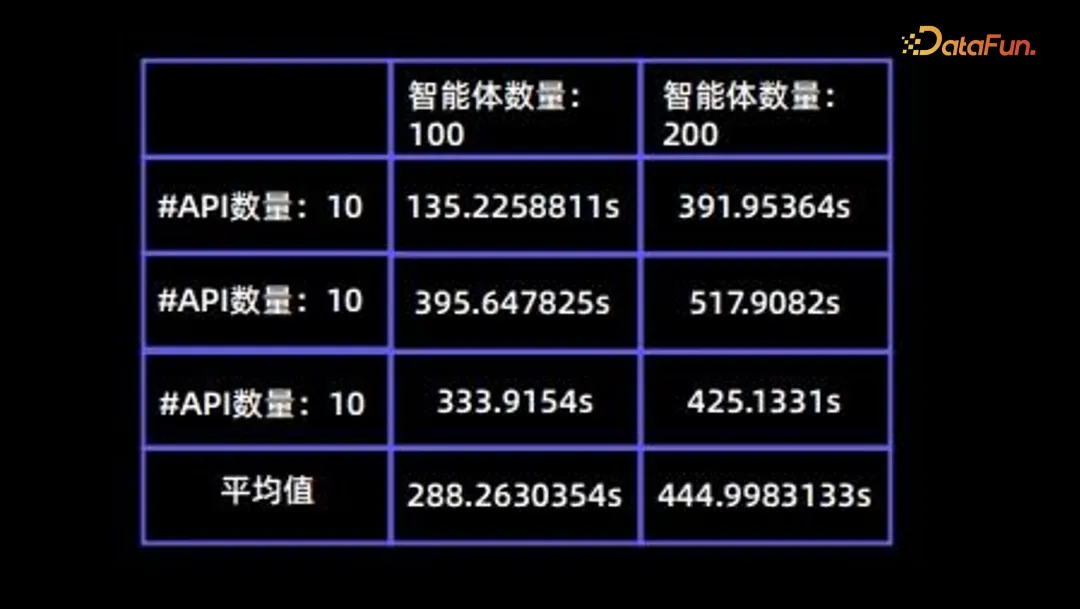
In the simulation process, efficiency is a very important issue; the following table summarizes the time consumption of different Agents under different API numbers.
The above is the detailed content of Al Agent--An important implementation direction in the era of large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Translator | Bugatti Review | Chonglou This article describes how to use the GroqLPU inference engine to generate ultra-fast responses in JanAI and VSCode. Everyone is working on building better large language models (LLMs), such as Groq focusing on the infrastructure side of AI. Rapid response from these large models is key to ensuring that these large models respond more quickly. This tutorial will introduce the GroqLPU parsing engine and how to access it locally on your laptop using the API and JanAI. This article will also integrate it into VSCode to help us generate code, refactor code, enter documentation and generate test units. This article will create our own artificial intelligence programming assistant for free. Introduction to GroqLPU inference engine Groq
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
This article will open source the results of "Local Deployment of Large Language Models in OpenHarmony" demonstrated at the 2nd OpenHarmony Technology Conference. Open source address: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/InferLLM/docs/ hap_integrate.md. The implementation ideas and steps are to transplant the lightweight LLM model inference framework InferLLM to the OpenHarmony standard system, and compile a binary product that can run on OpenHarmony. InferLLM is a simple and efficient L
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
