
 Technology peripherals
AI
CVPR 2024 | New framework CustomNeRF accurately edits 3D scenes with only text or image prompts
Technology peripherals
AI
CVPR 2024 | New framework CustomNeRF accurately edits 3D scenes with only text or image prompts
CVPR 2024 | New framework CustomNeRF accurately edits 3D scenes with only text or image prompts

Meitu Imaging Research Institute (MT Lab), together with the Institute of Information Engineering of the Chinese Academy of Sciences, Beijing University of Aeronautics and Astronautics, and Sun Yat-sen University, jointly proposed a 3D scene editing method - CustomNeRF. The research results have been accepted by CVPR 2024. CustomNeRF not only supports text descriptions and reference pictures as editing tips for 3D scenes, but also generates high-quality 3D scenes based on information provided by users.
Neural Radiance Field (NeRF) Since the Neural Radiance Field (NeRF) was proposed in 2020, it has pushed implicit expression to a new level. As one of the most cutting-edge technologies currently, NeRF has been rapidly generalized and applied in fields such as computer vision, computer graphics, augmented reality, and virtual reality, and continues to receive widespread attention. NeRF enables high-quality image synthesis by modeling the radiation and density of each point in the scene, which makes it widely attractive for applications in fields such as computer vision, computer graphics, augmented reality, and virtual reality. NeRF is unique in its ability to generate high-quality images from input scenes without the need for complex 3D scans or dense perspective images. This feature makes NeRF have broad application prospects in many fields, including computer vision, computer graphics, augmented reality, and virtual reality, and continues to receive widespread attention. NeRF enables high-quality image synthesis by modeling the radiance and density of every point in the scene. NeRF can also be used to generate high-quality 3D renderings, which makes it very promising for applications in areas such as virtual reality and augmented reality. The rapid development and widespread application of NeRF will continue to receive widespread attention, and it is expected that more innovations and applications based on NeRF will emerge in the future.
NeRF (Neural Radiation Field) is a feature used for optimization and continuous representation that has many applications in 3D scene reconstruction. It has even driven research in the field of 3D scene editing, such as texture redrawing and stylization of 3D objects or scenes. In order to further improve the flexibility of 3D scene editing, NeRF editing methods based on pre-trained models are also being extensively explored recently. Due to the implicit representation of NeRF and the geometric characteristics of 3D scenes, editing results that comply with text prompts can be obtained. These are Something very easy to implement.
In order to enable text-driven 3D scene editing to achieve precise control, Meitu Imaging Research Institute (MT Lab), the Institute of Information Engineering of the Chinese Academy of Sciences, Beijing University of Aeronautics and Astronautics, and Sun Yat-sen University jointly proposed a method to Text descriptions and reference images are unified into the CustomNeRF framework provided by the editor. This framework has a built-in perspective-specific subject V∗, which is embedded into the hybrid representation to meet general and customized 3D scene editing requirements. The research results have been recorded in CVPR 2024 and the code has been open source.

Paper link: https://arxiv.org/abs/2312.01663
Code link: https://github.com/hrz2000/customnerf

Two major challenges solved by CustomNeRF
Currently, 3D scene editing based on pre-trained diffusion models is the mainstream Methods are mainly divided into two categories.
One is to use the image editing model to iteratively update the images in the data set. However, it is limited by the ability of the image editing model and will fail in some editing situations. Second, the fractional distillation sampling (SDS) loss is used to edit the scene. However, due to the alignment problem between the text and the scene, this method cannot be directly adapted in the real scene and will cause unnecessary distortion in the non-editing area. Modification often requires explicit intermediate expressions such as mesh or voxel. In addition, the current two types of methods mainly focus on text-driven 3D scene editing tasks. Text descriptions are often difficult to accurately express the user's editing needs and cannot customize specific concepts in the image to the 3D scene. , only general editing can be performed on the original 3D scene, so it is difficult to obtain the editing results expected by the user. In fact, the key to obtaining the desired editing results is to accurately identify the image foreground area, which can promote geometrically consistent image foreground editing while maintaining the image background. Therefore, in order to achieve accurate editing of only the foreground area of the image, this paper proposes a training scheme of local-global iterative editing (LGIE), which alternates between image foreground area editing and full image editing. . This solution can accurately locate the image foreground area and only operate on the image foreground while retaining the image background.In addition, in image-driven 3D scene editing, there is a problem of geometric inconsistency in the editing results caused by the fine-tuned diffusion model overfitting to the reference image perspective. In this regard, the paper designs a class-guided regularization, using only class words to represent the subject of the reference image in the local editing stage, and leveraging a general class prior in a pre-trained diffusion model to promote geometrically consistent editing.
The overall process of CustomNeRF
As shown in Figure 2, CustomNeRF uses 3 steps to accurately edit and reconstruct 3D scenes under the guidance of text prompts or reference images. this goal.
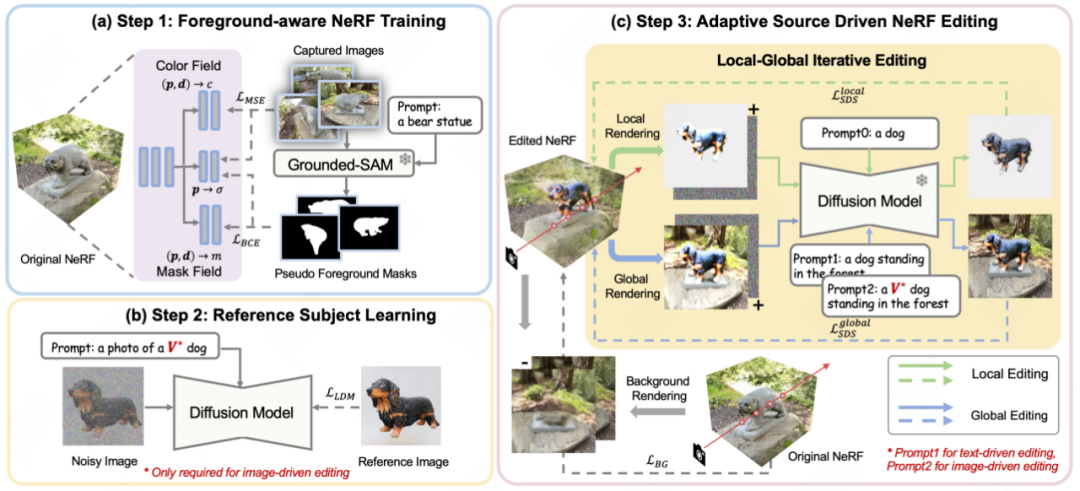
# 图 2 Customnerf's overall flowchart
This is first. When reconstruction of the original 3D scene,, when reconstruction of the original 3D scene, CustomNeRF introduces an additional mask field to estimate edit probabilities in addition to regular color and density. As shown in Figure 2(a), for a set of images that need to reconstruct a 3D scene, the paper first uses Grouded SAM to extract the mask of the image editing area from the natural language description, and combines the original image set to train foreground-aware NeRF. After NeRF reconstruction, the edit probabilities are used to distinguish image regions to be edited (i.e., image foreground regions) from irrelevant image regions (i.e., image background regions) to facilitate decoupled rendering during image editing training.
Secondly, in order to unify image-driven and text-driven 3D scene editing tasks, as shown in Figure 2(b), this paper uses the Custom Diffusion method to fine-tune the reference image under image-driven conditions to Learn the key characteristics of a specific agent. After training, the special word V* can be used as a regular word tag to express the subject concept in the reference image, thus forming a hybrid cue, such as “a photo of a V* dog”. In this way, CustomNeRF enables consistent and efficient editing of adaptive types of data, including images or text.
In the final editing stage, due to the implicit expression of NeRF, optimizing the entire 3D area using the SDS loss will result in significant changes in the background areas that should remain consistent with the original scene after editing. As shown in Figure 2(c), the paper proposes a local-global iterative editing (LGIE) scheme for decoupled SDS training, enabling it to preserve background content while editing the layout area.
Specifically, this paper divides the editing training process of NeRF into a more fine-grained manner. With foreground-aware NeRF, CustomNeRF can flexibly control the rendering process of NeRF during training, that is, under a fixed camera perspective, it can choose to render foreground, background, and regular images containing foreground and background. During training, the current NeRF scene can be edited at different levels using the SDS loss by iteratively rendering the foreground and background, combined with corresponding foreground or background cues. Among them, local foreground training allows you to focus only on the area that needs to be edited during the editing process, simplifying the difficulty of editing tasks in complex scenes; while global training takes the entire scene into consideration and can maintain the coordination of the foreground and background. In order to further keep the non-edited area unchanged, the paper also uses the newly rendered background during the background supervision training process before editing training to maintain the consistency of the background pixels.
Additionally, there are exacerbating geometric inconsistencies in image-driven 3D scene editing. Because the diffusion model that has been fine-tuned with the reference image tends to produce images with a perspective similar to that of the reference image during the inference process, causing multiple perspectives of the edited 3D scene to be front-view geometric problems. To this end, the paper designs a class-guided regularization strategy, using special descriptors V* in global cues and only class words in local cues to take advantage of the class priors included in the pre-trained diffusion model, using more Inject new concepts into the scene in a geometrically consistent manner.
Experimental results
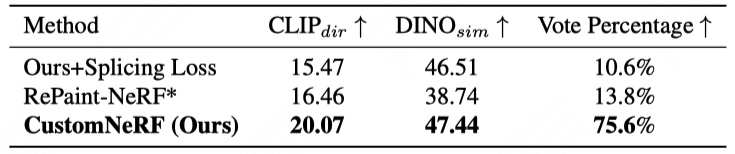
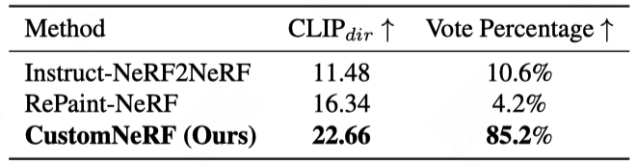
Figure 3 and Figure 4 show the comparison of the 3D scene reconstruction results of CustomNeRF and the baseline method in the reference image and text-driven 3D scene editing tasks , CustomNeRF has achieved good editing results, not only achieving good alignment with the editing prompts, but also keeping the background area consistent with the original scene. In addition, Table 1 and Table 2 show the quantitative comparison of CustomNeRF with the baseline method when driven by images and text. The results show that CustomNeRF surpasses the baseline method in text alignment metrics, image alignment metrics, and human evaluation.

##

## with with text-driven editing # Table 1 Image driver Edit and Edit of the baseline
2 2 Text Drive Edit Quantitative comparison with baseline
 Summary
Summary
This paper innovatively proposes the CustomNeRF model and supports editing prompts for text descriptions or reference images. , and solves two key challenges - precise foreground-only editing and consistency across multiple views when using a single-view reference image. The scheme includes the local-global iterative editing (LGIE) training scheme, which enables editing operations to focus on the foreground while keeping the background unchanged; and class-guided regularization, which alleviates view inconsistencies in image-driven editing, and has been verified through extensive experiments CustomNeRF enables accurate editing of 3D scenes prompted by textual descriptions and reference images in a variety of real-world scenarios.
The above is the detailed content of CVPR 2024 | New framework CustomNeRF accurately edits 3D scenes with only text or image prompts. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 How to download git projects to local
Apr 17, 2025 pm 04:36 PM
How to download git projects to local
Apr 17, 2025 pm 04:36 PM
To download projects locally via Git, follow these steps: Install Git. Navigate to the project directory. cloning the remote repository using the following command: git clone https://github.com/username/repository-name.git
 How to update code in git
Apr 17, 2025 pm 04:45 PM
How to update code in git
Apr 17, 2025 pm 04:45 PM
Steps to update git code: Check out code: git clone https://github.com/username/repo.git Get the latest changes: git fetch merge changes: git merge origin/master push changes (optional): git push origin master
 How to merge code in git
Apr 17, 2025 pm 04:39 PM
How to merge code in git
Apr 17, 2025 pm 04:39 PM
Git code merge process: Pull the latest changes to avoid conflicts. Switch to the branch you want to merge. Initiate a merge, specifying the branch to merge. Resolve merge conflicts (if any). Staging and commit merge, providing commit message.
 What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
What to do if the git download is not active
Apr 17, 2025 pm 04:54 PM
Resolve: When Git download speed is slow, you can take the following steps: Check the network connection and try to switch the connection method. Optimize Git configuration: Increase the POST buffer size (git config --global http.postBuffer 524288000), and reduce the low-speed limit (git config --global http.lowSpeedLimit 1000). Use a Git proxy (such as git-proxy or git-lfs-proxy). Try using a different Git client (such as Sourcetree or Github Desktop). Check for fire protection
 How to use git commit
Apr 17, 2025 pm 03:57 PM
How to use git commit
Apr 17, 2025 pm 03:57 PM
Git Commit is a command that records file changes to a Git repository to save a snapshot of the current state of the project. How to use it is as follows: Add changes to the temporary storage area Write a concise and informative submission message to save and exit the submission message to complete the submission optionally: Add a signature for the submission Use git log to view the submission content
 How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
How to solve the efficient search problem in PHP projects? Typesense helps you achieve it!
Apr 17, 2025 pm 08:15 PM
When developing an e-commerce website, I encountered a difficult problem: How to achieve efficient search functions in large amounts of product data? Traditional database searches are inefficient and have poor user experience. After some research, I discovered the search engine Typesense and solved this problem through its official PHP client typesense/typesense-php, which greatly improved the search performance.
 How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
How to delete a repository by git
Apr 17, 2025 pm 04:03 PM
To delete a Git repository, follow these steps: Confirm the repository you want to delete. Local deletion of repository: Use the rm -rf command to delete its folder. Remotely delete a warehouse: Navigate to the warehouse settings, find the "Delete Warehouse" option, and confirm the operation.
 How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local code in git
Apr 17, 2025 pm 04:48 PM
How to update local Git code? Use git fetch to pull the latest changes from the remote repository. Merge remote changes to the local branch using git merge origin/<remote branch name>. Resolve conflicts arising from mergers. Use git commit -m "Merge branch <Remote branch name>" to submit merge changes and apply updates.
