
 Technology peripherals
AI
CVPR\'24 | LightDiff: Diffusion model in low-light scenes, directly lighting up the night!
Technology peripherals
AI
CVPR\'24 | LightDiff: Diffusion model in low-light scenes, directly lighting up the night!
CVPR\'24 | LightDiff: Diffusion model in low-light scenes, directly lighting up the night!

Original title: Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Paper link: https://arxiv.org/pdf/2404.04804.pdf
Author affiliation: Cleveland State University, University of Texas at Austin, A*STAR, New York University, University of California, Los Angeles

Thesis idea:
LightDiff is a technology that improves the efficiency and scalability of vision-centered perception systems for autonomous driving. LiDAR systems have received considerable attention recently. However, these systems often experience difficulties in low-light conditions, potentially affecting their performance and safety. To solve this problem, this article introduces LightDiff, an automated framework designed to improve low-light image quality in autonomous driving applications. Specifically, this paper adopts a multi-condition controlled diffusion model. LightDiff eliminates the need for manually collected pairwise data and instead exploits a dynamic data degradation process. It incorporates a novel multi-condition adapter that is able to adaptively control input weights from different modalities, including depth maps, RGB images, and text captions, to simultaneously maintain content consistency under low-light and low-light conditions. Furthermore, to match the augmented images with the knowledge of the detection model, LightDiff uses perceptron-specific scores as rewards to guide the diffusion training process through reinforcement learning. Extensive experiments on the nuScenes dataset show that LightDiff can significantly improve the performance of multiple state-of-the-art 3D detectors in nighttime conditions while achieving high visual quality scores, highlighting its potential for ensuring autonomous driving safety.
Main contributions:
This paper proposes the Lighting Diffusion (LightDiff) model to enhance low-light camera images in autonomous driving, reducing the need for large amounts of nighttime data collection demand and maintain performance capabilities during the day.
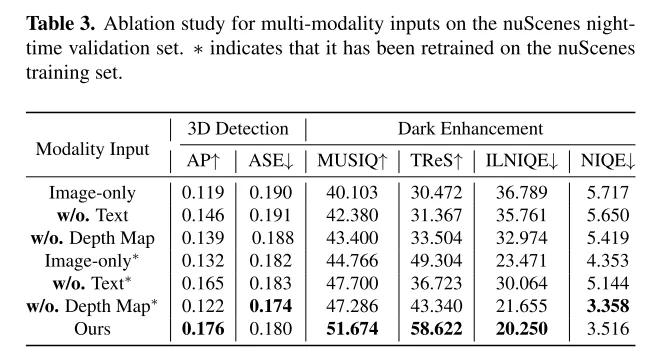
This paper integrates multiple input modes including depth maps and image captions, and proposes a multi-condition adapter to ensure semantic integrity in image conversion while maintaining high visual quality. This paper adopts a practical process to generate day and night image pairs from daytime data to achieve efficient model training.
This paper introduces a fine-tuning mechanism using reinforcement learning, combined with perceptually customized domain knowledge (credible lidar and consistency of statistical distributions) to ensure that the diffusion process has a strength conducive to human visual perception , and use the perceptual model to perform perceptual model. This method has significant advantages in human visual perception and also has the advantages of perceptual models.
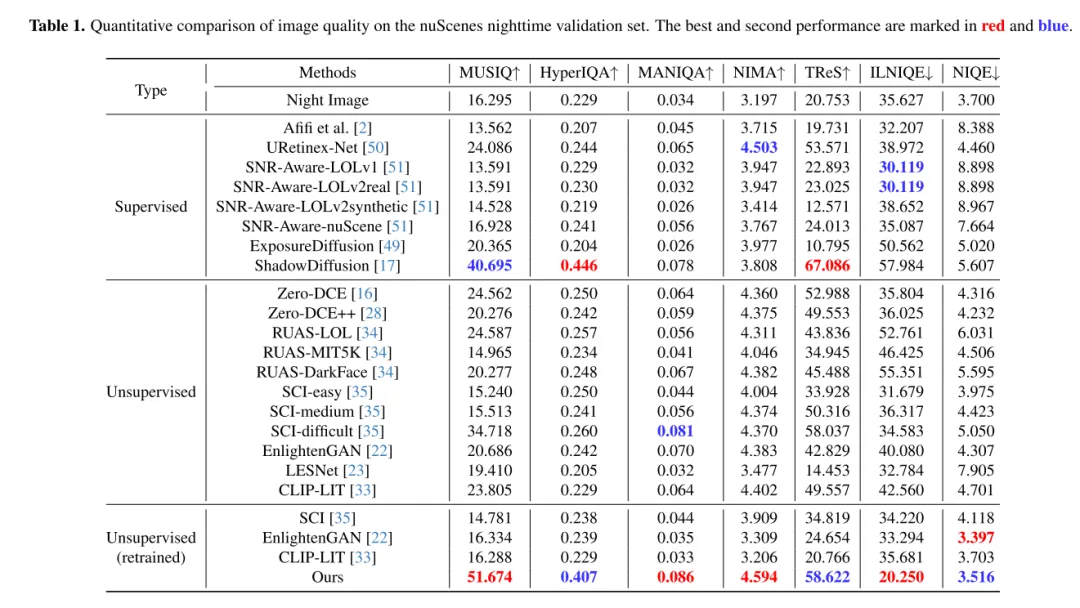
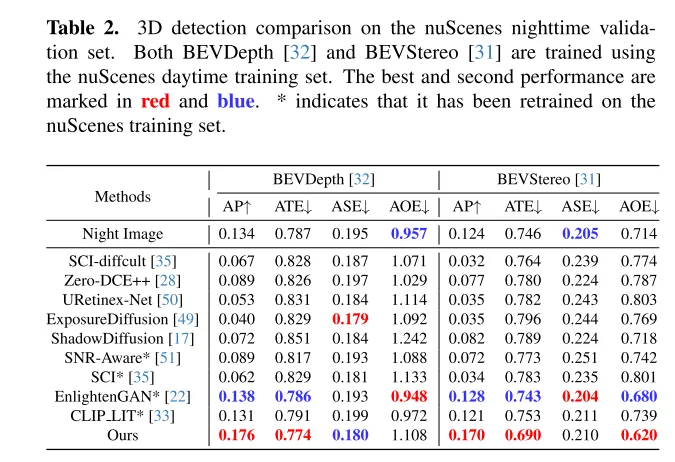
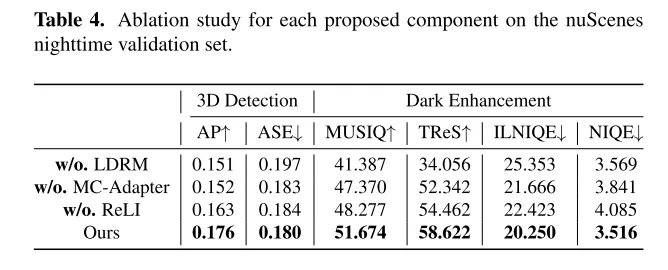
Extensive experiments on the nuScenes dataset show that LightDiff significantly improves the performance of 3D vehicle detection at night and outperforms other generative models on multiple perspective metrics.
Network Design:
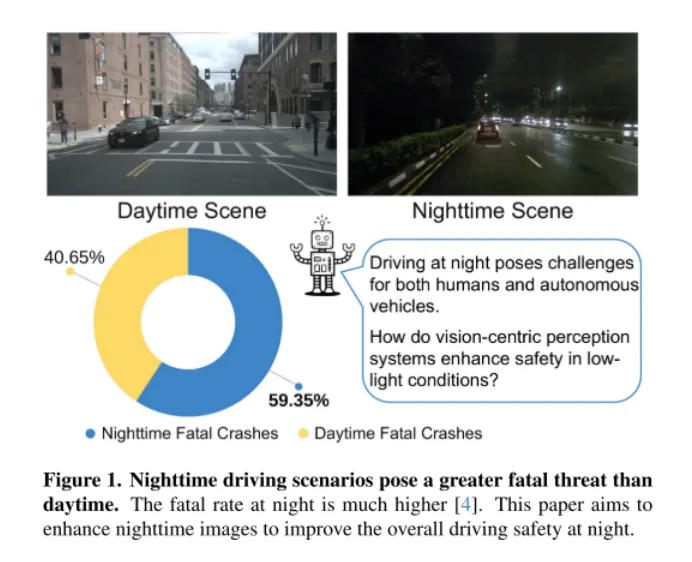
Figure 1. Driving scenarios at night are more deadly than during the day. The fatality rate is much higher at night [4]. This article aims to enhance nighttime images to improve the overall safety of nighttime driving.
As shown in Figure 1, night driving is challenging for humans, especially for autonomous vehicles. This challenge was highlighted by a catastrophic incident on March 18, 2018, when a self-driving car from Uber Advanced Technologies Group struck and killed a pedestrian in Arizona [37]. The incident, which was caused by the vehicle's failure to accurately detect a pedestrian in low-light conditions, has brought safety issues for autonomous vehicles to the forefront, especially in such demanding environments. As vision-centric autonomous driving systems increasingly rely on camera sensors, addressing safety concerns in low-light conditions has become increasingly critical to ensure the overall safety of these vehicles.
An intuitive solution is to collect large amounts of nighttime driving data. However, this method is not only labor-intensive and costly, but also may harm the performance of the daytime model due to the difference in image distribution between nighttime and daytime. To address these challenges, this paper proposes the Lighting Diffusion (LightDiff) model, a novel approach that eliminates the need for manual data collection and maintains daytime model performance.
The goal of LightDiff is to enhance low-light camera images and improve the performance of perceptual models. By using a dynamic low-light attenuation process, LightDiff generates synthetic day-night image pairs for training from existing daytime data. Next, this paper adopts Stable Diffusion [44] technology due to its ability to produce high-quality visual effects that effectively transform nighttime scenes into daytime equivalents. However, maintaining semantic consistency is crucial in autonomous driving, which was a challenge faced by the original Stable Diffusion model. To overcome this, LightDiff combines multiple input modalities, such as estimated depth maps and camera image captions, with a multi-condition adapter. This adapter intelligently determines the weight of each input modality, ensuring the semantic integrity of the converted image while maintaining high visual quality. In order to guide the diffusion process not only in the direction of being brighter for human vision, but also for perception models, this paper further uses reinforcement learning to fine-tune this paper's LightDiff, adding domain knowledge tailored for perception into the loop. This paper conducts extensive experiments on the autonomous driving dataset nuScenes [7] and demonstrates that our LightDiff can significantly improve the average accuracy (AP) of nighttime 3D vehicle detection for two state-of-the-art models, BEVDepth [32] and BEVStereo. [31] improved by 4.2% and 4.6%.
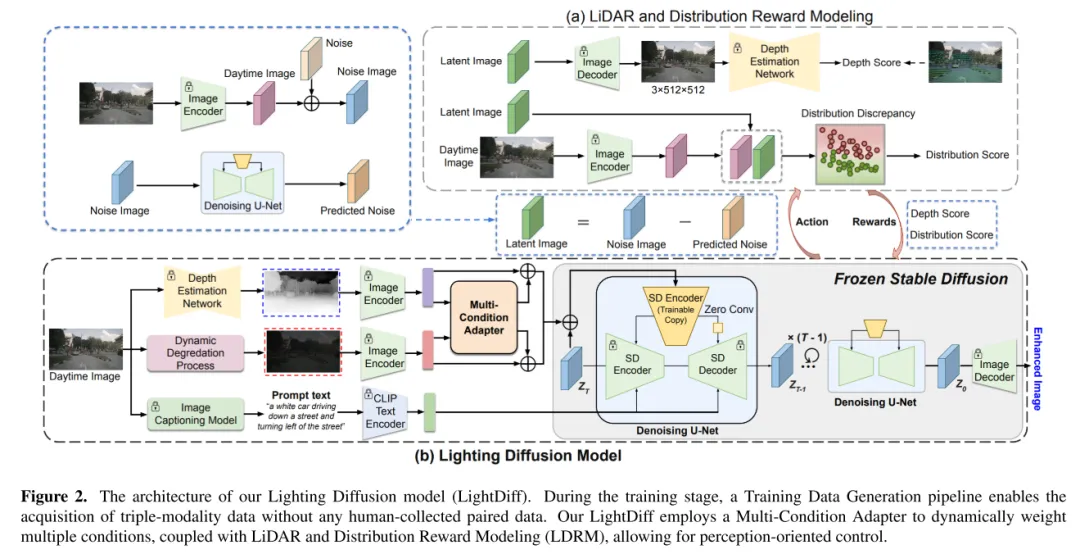
Figure 2. The architecture of the Lighting Diffusion model (LightDiff) in this article. During the training phase, a training data generation process enables the acquisition of trimodal data without any manual collection of paired data. Our LightDiff uses a multi-condition adapter to dynamically weight multiple conditions, combined with lidar and distributed reward modeling (LDRM), allowing for perception-oriented control.
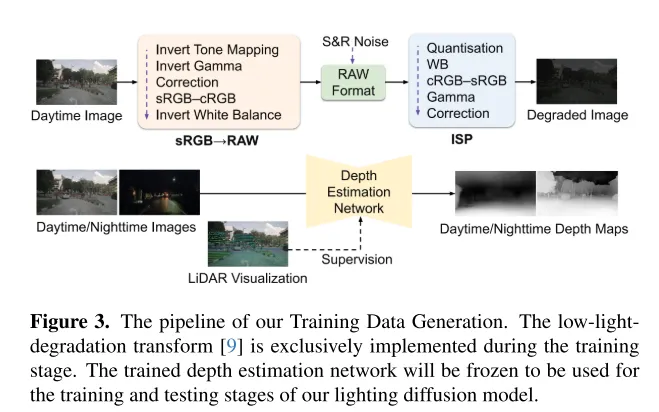
Figure 3. The training data generation process of this article. Low-light degradation transformation [9] is only implemented during the training phase. The trained depth estimation network will be frozen and used for the training and testing phases of the Lighting Diffusion model in this article.
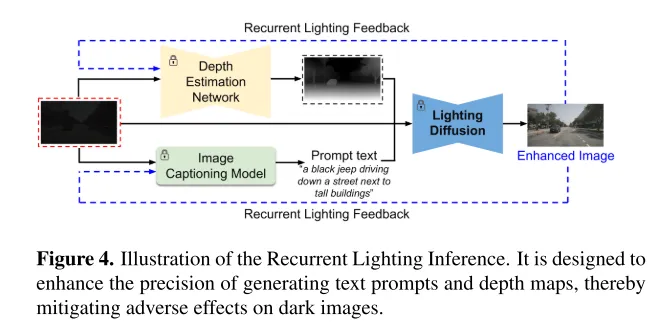
Figure 4. Schematic diagram of Recurrent Lighting Inference. It is designed to improve the accuracy of generating text hints and depth maps, thereby mitigating the detrimental effects of dark images.
Experimental results:

Figure 5. Visual comparison on a sample of nighttime images in the nuScenes validation set.

Figure 6. Visualization of 3D detection results on an example of nighttime images in the nuScenes validation set. This paper uses BEVDepth [32] as a three-dimensional detector and visualizes the front view and Bird’s-Eye-View of the camera.

Figure 7. Shows the visual effect of LightDiff in this article with or without the MultiCondition Adapter. The input to ControlNet [55] remains consistent, including the same text cues and depth maps. Multi-condition adapters enable better color contrast and richer details during enhancement.
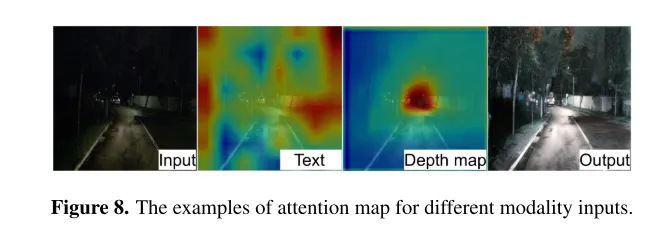
Figure 8. Examples of attention maps for different modal inputs.

Figure 9. Schematic diagram of enhanced multi-modal generation through Recurrent Lighting Inference (ReLI). By calling ReLI once, the accuracy of text hints and depth map predictions is improved.
Summary:
This article introduces LightDiff, a tool designed for autonomous driving applications. Domain-specific framework designed to improve image quality in low-light environments and alleviate challenges faced by vision-centric perception systems. By leveraging a dynamic data degradation process, multi-condition adapters for different input modalities, and perceptually specific score-guided reward modeling using reinforcement learning, LightDiff significantly improves nighttime image quality and 3D performance on the nuScenes dataset Vehicle detection performance. This innovation not only eliminates the need for large amounts of nighttime data, but also ensures semantic integrity in image transformation, demonstrating its potential to improve safety and reliability in autonomous driving scenarios. In the absence of realistic paired day-night images, it is quite difficult to synthesize dim driving images with car lights, which limits research in this field. Future research could focus on better collection or generation of high-quality training data.
Citation:
@ARTICLE{2024arXiv240404804L,
author = {{Li}, Jinlong and {Li}, Baolu and {Tu}, Zhengzhong and { Liu}, Xinyu and {Guo}, Qing and {Juefei-Xu}, Felix and {Xu}, Runsheng and {Yu}, Hongkai},
title = "{Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving}",
journal = {arXiv e-prints},
keywords = {Computer Science - Computer Vision and Pattern Recognition},
year = 2024,
month = apr,
eid = {arXiv:2404.04804},
pages = {arXiv:2404.04804},
doi = {10.48550/arXiv.2404.04804},
archivePrefix = {arXiv},
eprint = {2404.04804},
primaryClass = {cs.CV},
adsurl = {https://ui.adsabs.harvard.edu/abs/2024arXiv240404804L},
adsnote = {Provided by the SAO /NASA Astrophysics Data System}
}
The above is the detailed content of CVPR\'24 | LightDiff: Diffusion model in low-light scenes, directly lighting up the night!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
Evaluating the cost/performance of commercial support for a Java framework involves the following steps: Determine the required level of assurance and service level agreement (SLA) guarantees. The experience and expertise of the research support team. Consider additional services such as upgrades, troubleshooting, and performance optimization. Weigh business support costs against risk mitigation and increased efficiency.
 Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!
Jun 08, 2024 pm 09:30 PM
Towards 'Closed Loop' | PlanAgent: New SOTA for closed-loop planning of autonomous driving based on MLLM!
Jun 08, 2024 pm 09:30 PM
The deep reinforcement learning team of the Institute of Automation, Chinese Academy of Sciences, together with Li Auto and others, proposed a new closed-loop planning framework for autonomous driving based on the multi-modal large language model MLLM - PlanAgent. This method takes a bird's-eye view of the scene and graph-based text prompts as input, and uses the multi-modal understanding and common sense reasoning capabilities of the multi-modal large language model to perform hierarchical reasoning from scene understanding to the generation of horizontal and vertical movement instructions, and Further generate the instructions required by the planner. The method is tested on the large-scale and challenging nuPlan benchmark, and experiments show that PlanAgent achieves state-of-the-art (SOTA) performance on both regular and long-tail scenarios. Compared with conventional large language model (LLM) methods, PlanAgent
 Review! Comprehensively summarize the important role of basic models in promoting autonomous driving
Jun 11, 2024 pm 05:29 PM
Review! Comprehensively summarize the important role of basic models in promoting autonomous driving
Jun 11, 2024 pm 05:29 PM
Written above & the author’s personal understanding: Recently, with the development and breakthroughs of deep learning technology, large-scale foundation models (Foundation Models) have achieved significant results in the fields of natural language processing and computer vision. The application of basic models in autonomous driving also has great development prospects, which can improve the understanding and reasoning of scenarios. Through pre-training on rich language and visual data, the basic model can understand and interpret various elements in autonomous driving scenarios and perform reasoning, providing language and action commands for driving decision-making and planning. The base model can be data augmented with an understanding of the driving scenario to provide those rare feasible features in long-tail distributions that are unlikely to be encountered during routine driving and data collection.
 How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
The learning curve of a PHP framework depends on language proficiency, framework complexity, documentation quality, and community support. The learning curve of PHP frameworks is higher when compared to Python frameworks and lower when compared to Ruby frameworks. Compared to Java frameworks, PHP frameworks have a moderate learning curve but a shorter time to get started.
 How do the lightweight options of PHP frameworks affect application performance?
Jun 06, 2024 am 10:53 AM
How do the lightweight options of PHP frameworks affect application performance?
Jun 06, 2024 am 10:53 AM
The lightweight PHP framework improves application performance through small size and low resource consumption. Its features include: small size, fast startup, low memory usage, improved response speed and throughput, and reduced resource consumption. Practical case: SlimFramework creates REST API, only 500KB, high responsiveness and high throughput
 Golang framework documentation best practices
Jun 04, 2024 pm 05:00 PM
Golang framework documentation best practices
Jun 04, 2024 pm 05:00 PM
Writing clear and comprehensive documentation is crucial for the Golang framework. Best practices include following an established documentation style, such as Google's Go Coding Style Guide. Use a clear organizational structure, including headings, subheadings, and lists, and provide navigation. Provides comprehensive and accurate information, including getting started guides, API references, and concepts. Use code examples to illustrate concepts and usage. Keep documentation updated, track changes and document new features. Provide support and community resources such as GitHub issues and forums. Create practical examples, such as API documentation.
 How to choose the best golang framework for different application scenarios
Jun 05, 2024 pm 04:05 PM
How to choose the best golang framework for different application scenarios
Jun 05, 2024 pm 04:05 PM
Choose the best Go framework based on application scenarios: consider application type, language features, performance requirements, and ecosystem. Common Go frameworks: Gin (Web application), Echo (Web service), Fiber (high throughput), gorm (ORM), fasthttp (speed). Practical case: building REST API (Fiber) and interacting with the database (gorm). Choose a framework: choose fasthttp for key performance, Gin/Echo for flexible web applications, and gorm for database interaction.
 Java Framework Learning Roadmap: Best Practices in Different Domains
Jun 05, 2024 pm 08:53 PM
Java Framework Learning Roadmap: Best Practices in Different Domains
Jun 05, 2024 pm 08:53 PM
Java framework learning roadmap for different fields: Web development: SpringBoot and PlayFramework. Persistence layer: Hibernate and JPA. Server-side reactive programming: ReactorCore and SpringWebFlux. Real-time computing: ApacheStorm and ApacheSpark. Cloud Computing: AWS SDK for Java and Google Cloud Java.
