

ReFT (Representation Finetuning) is a breakthrough method that promises to redefine the way we fine-tune large language models.
In a paper recently (April) published on arxiv by researchers at Stanford University, ReFT is very different from the traditional weight-based fine-tuning method. It provides a more efficient and Efficient ways to adapt these large-scale models to new tasks and domains!

Before introducing this paper, let’s take a look at PeFT.
Parameter Efficient Fine-Tuning (PEFT) is an efficient fine-tuning method for fine-tuning a small number or additional model parameters. . Compared with traditional prediction network fine-tuning methods, using PEFT for fine-tuning can significantly reduce computing and storage costs, while ensuring performance comparable to full fine-tuning. This technology has a wide range of applications and can achieve performance comparable to full trimming.
Based on the idea of PeFT, the LoRA that we are very familiar with has been produced, and there are various variants of LoRA. In addition to the famous LoRA, the commonly used PeFT methods include:
Prefix Tuning: Construct a continuous implicit prompt through virtual token. This is a method released by Stanford in 2021.
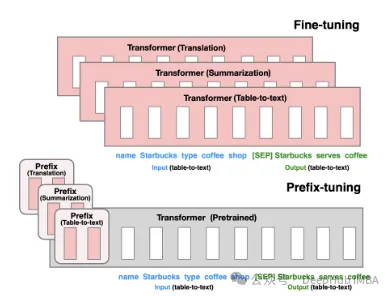
P-Tuning V1/V2 is a technology proposed by Tsinghua University in 2021, aiming to convert discrete models of natural language into trainable Implicit prompt (continuous parameter optimization problem). The V2 version further enhances the performance of the V1 version by adding fine-tunable parameters to each layer before input. This method effectively extends the application scope and flexibility of the model.
Then there is LoRA, which we are familiar with and have been used for the longest time. I won’t introduce it in detail here. We can understand it in a narrow sense that LoRA is currently the best The PeFT method can provide a better comparison with the ReFT we introduce below.
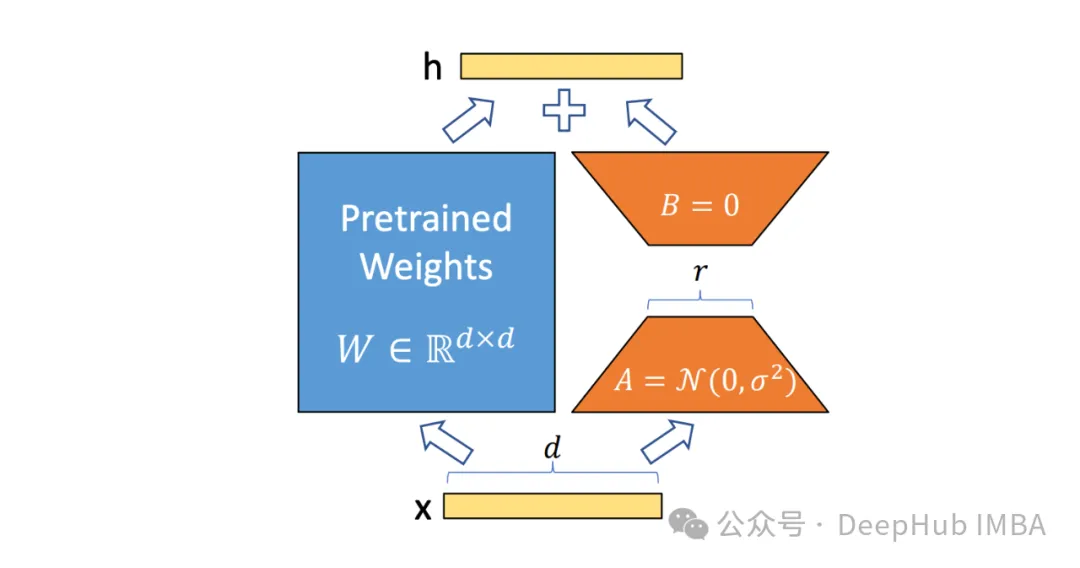
ReFT (Representation Finetuning) is a group that focuses on the reasoning process Hidden representations of the language model learn how to intervene instead of directly modifying its weights.
Unlike traditional fine-tuning methods that update a model's entire parameter set, ReFT operates by strategically manipulating small portions of a model's representation, guiding its behavior to solve downstream tasks more efficiently.
The core idea behind ReFT is inspired by recent research on language model interpretability: rich semantic information is encoded in the representations learned by these models. By intervening in these representations, ReFT aims to unlock and exploit this encoded knowledge, enabling more efficient and effective model adaptation.
A key advantage of ReFT is its parameter efficiency: traditional fine-tuning methods require updating a large portion of the model parameters, which can be computationally expensive and resource-intensive, especially for models with Large language models with billions of parameters. ReFT methods typically require training orders of magnitude fewer parameters, resulting in faster training times and less memory requirements.
ReFT differs from traditional PEFT methods in several key ways:
##PEFT methods, such as LoRA, DoRA and prefix-tuning, focus on modifying the weights of the model or introducing additional weight matrices. ReFT methods do not directly modify the model’s weights; they interfere with the hidden representation calculated by the model during the forward pass.
PEFT methods like LoRA and DoRA learn weight updates or low-rank approximations of the model weight matrix. These weight updates are then incorporated into the base model's weights during inference, resulting in no additional computational overhead. ReFT methods learn to intervene, manipulating the representation of the model at specific layers and locations during inference. This intervention process incurs some computational overhead but allows for more efficient adaptation.
#The main motivation of the PEFT method is the need for effective adaptation of parameters, which reduces the computational cost of tuning large language models and memory requirements. ReFT methods, on the other hand, are inspired by recent research on language model interpretability, which shows that rich semantic information is encoded in the representations learned by these models. The goal of ReFT is to exploit and exploit this encoded knowledge to fit the model more efficiently.
Both the PEFT and ReFT methods are designed for parameter efficiency, but the ReFT method has proven to be higher parameter efficiency in practice. For example, LoReFT (low-rank linear subspace ReFT) methods typically require 10-50 times fewer parameters to train than the state-of-the-art PEFT method (LoRA), while achieving competitive or better performance on various NLP benchmarks.
While the PEFT method mainly focuses on efficient adaptation, the ReFT method provides additional The advantages. By intervening in representations known to encode specific semantic information, ReFT methods can provide insights into how language models process and understand language, potentially leading to more transparent and trustworthy artificial intelligence systems.
The ReFT model architecture defines the general concept of intervention, which basically means hiding during forward pass of the model Represented modifications. We first consider a transformer-based language model that generates contextualized representations of token sequences.
Given a sequence of n input tokens x = (x₁,…,xn), the model first embeds it into a list of representations, in terms of h₁,…,hn. Then the m layer continuously calculates the jth hidden representation. Each hidden representation is a vector h∈λ, where d is the dimension of the representation.
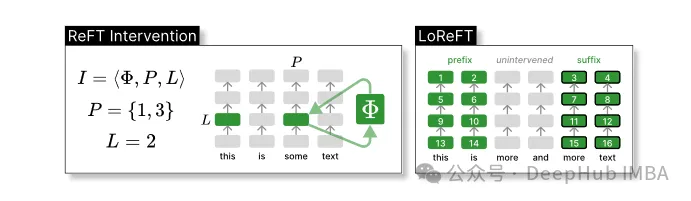
ReFT defines the concept of an intervention that modifies the hidden representation during the forward pass of the model.
Intervention I is a tuple ⟨Φ, P, L , which encapsulates the intervention action of a single inference time represented by the transformer-based LM calculation. This function contains three Parameters:
Intervention function Φ: represented by the learned parameter Φ (Φ).
The set of input positions P≤{1,…,n} to which the intervention is applied.
Intervene on layer L∈{1,…,m}.
Then, the intervention actions are as follows:
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}The intervention is performed immediately after the forward propagation calculation is completed, So it will affect the representation calculated in subsequent layers.
In order to improve the efficiency of calculation, the intervention weights can also be decomposed into low-rank, which is to obtain low-rank linear subspace ReFT (LoReFT).
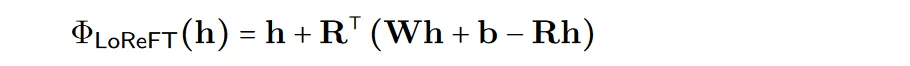
Use the learned projection source Rs = Wh b in the above formula. LoReFT edits the representation in the R-dimensional subspace of R columns to take the values obtained from our linear projection Wh b.
For generation tasks, the ReFT paper uses the training objective of language modeling, focusing on minimizing the cross-entropy loss across all output positions.
Researchers at Stanford University released the paper at the same time as the pyreft library, which is a library built on pyvene A library for executing and training activation interventions on any PyTorch model.
pyreft is compatible with any pre-trained language model available on HuggingFace and can be fine-tuned using the ReFT method. The following is a code example of how to apply a single intervention to the output of layer 19 of the lama-27b model:
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()The rest of the code has nothing to do with the HuggingFace training model. The difference, let’s do a complete demonstration:
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
Once training is completed, you can check the model information:
prompt = tokenizer("GO->", return_tensors="pt").to("cuda") base_unit_location = prompt["input_ids"].shape[-1] - 1# last position _, reft_response = reft_model.generate( prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True))Finally let’s take a look at its outstanding performance in various NLP benchmarks. The following is the data shown by researchers at Stanford University.
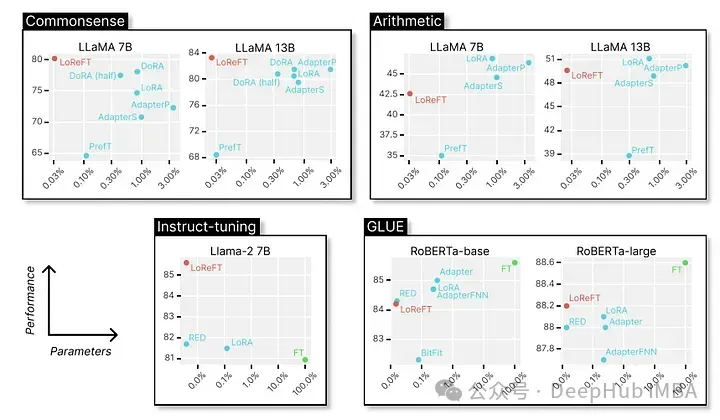
LoReFT achieves state-of-the-art performance on 8 challenging datasets, including BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c and OBQA. Despite using significantly fewer parameters than existing PEFT methods (10-50x fewer), LoReFT significantly outperforms all other methods, demonstrating its effectiveness in capturing and leveraging common sense knowledge encoded in large language models. ability.
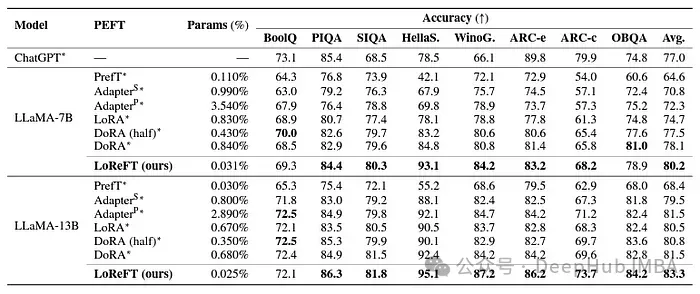
Although LoReFT does not outperform existing PEFT methods on mathematical reasoning tasks, it performs better on datasets such as AQuA, GSM8K, MAWPS, and SVAMP. Demonstrated competitive performance. The researchers noted that LoReFT's performance improves with model size, suggesting that its capabilities expand as language models continue to grow.
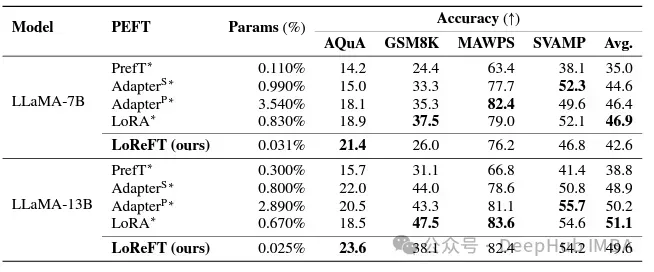
In the field of instruction following, LoReFT achieved remarkable results, outperforming all fine-tuning methods on the Alpaca-Eval v1.0 benchmark. , including complete fine-tuning (pay attention to the explanation). When trained on the llama-27b model, LoReFT is 1% better than the GPT-3.5 Turbo model, while using far fewer parameters than other PEFT methods.
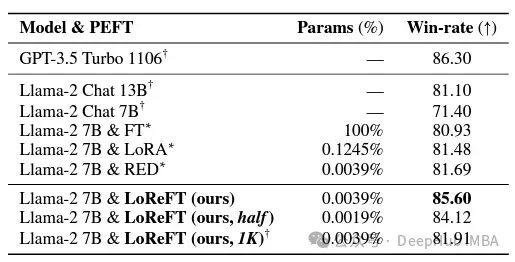
LoReFT also demonstrated its capabilities in natural language understanding tasks, when applied to RoBERTa-base and RoBERTa-large models, in GLUE Comparable performance to existing PEFT methods is achieved in benchmark tests.
When matching the previous most effective PEFT method in number of parameters, LoReFT achieved similar scores on a variety of tasks, including sentiment analysis and natural language reasoning.
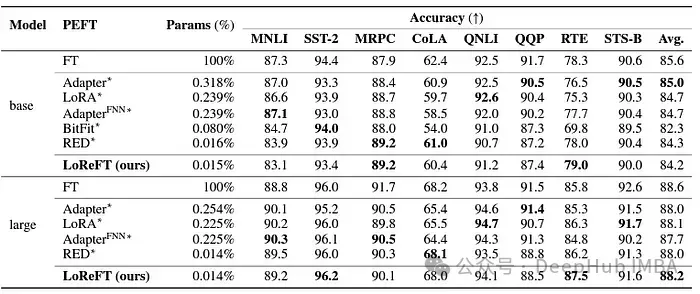
The success of ReFT, and especially LoReFT, has great implications for the future of natural language processing and large languages The practical application of the model is of great significance. The parameter efficiency of ReFT makes it an effective solution for adapting large language models to specific tasks or domains while minimizing computational resources and training time.
And ReFT also provides a unique perspective to enhance the interpretability of large language models. Success in tasks such as common sense reasoning, arithmetic reasoning, and instruction following demonstrates the effectiveness of this approach. At present, ReFT is expected to open up new possibilities and overcome the limitations of traditional tuning methods.
The above is the detailed content of ReFT (Representation Fine-tuning): a new large language model fine-tuning technology that is better than PeFT. For more information, please follow other related articles on the PHP Chinese website!
 How to generate bin file with mdk
How to generate bin file with mdk
 html to txt
html to txt
 delete an element from js array
delete an element from js array
 What are the main differences between linux and windows
What are the main differences between linux and windows
 How to turn off windows security center
How to turn off windows security center
 How to deal with blocked file downloads in Windows 10
How to deal with blocked file downloads in Windows 10
 Domestic Bitcoin buying and selling platform
Domestic Bitcoin buying and selling platform
 How to implement jsp paging function
How to implement jsp paging function








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



