Introducing hybrid depth, DeepMind’s new design can greatly improve Transformer efficiency.
Needless to say, the importance of Transformer. There are currently many research teams working on improving this transformative technology. One of the important improvement directions is to improve the performance of Transformer. Efficiency, such as allowing it to have adaptive computing capabilities, thereby saving unnecessary calculations. As Illiya Polosukhin, one of the proposers of the Transformer architecture and co-founder of NEAR Protocol, said in a conversation with Jen-Hsun Huang not long ago: "Adaptive computing is the next step. It must appear. We need to pay attention to how much computing resources are spent on specific problems." 
##In fact, humans are born with the ability to adapt to computing - people are solving problems. Different problems will naturally allocate different amounts of time and energy.
#The same should be true for language modeling. In order to obtain accurate prediction results, it is not necessary to invest the same time or resources for all tokens and sequences. However, the Transformer model spends the same amount of computation for each token in a forward pass. This makes people lament: most of the calculations are wasted!
#Ideally, you can reduce the Transformer's computational budget if you can avoid performing unnecessary calculations.
#Conditional calculation is a technique that reduces the total amount of calculations by performing calculations only when they are needed. Many researchers have previously proposed various algorithms that can evaluate when calculations are performed and how much calculations are used.
However, for this challenging problem, commonly used solution forms may not cope well with existing hardware limitations because they tend to introduce dynamic computation graphs . Instead, the most promising conditional computation methods may be those that make consistent use of the current hardware stack, prioritizing the use of static computation graphs and known tensor sizes chosen based on maximum utilization of the hardware.
Recently, Google DeepMind has studied this problem. They hope to use a lower computing budget to reduce the amount of calculation used by Transformer.
- Paper title: Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
- Paper address: https://arxiv.org/pdf/2404.02258.pdf
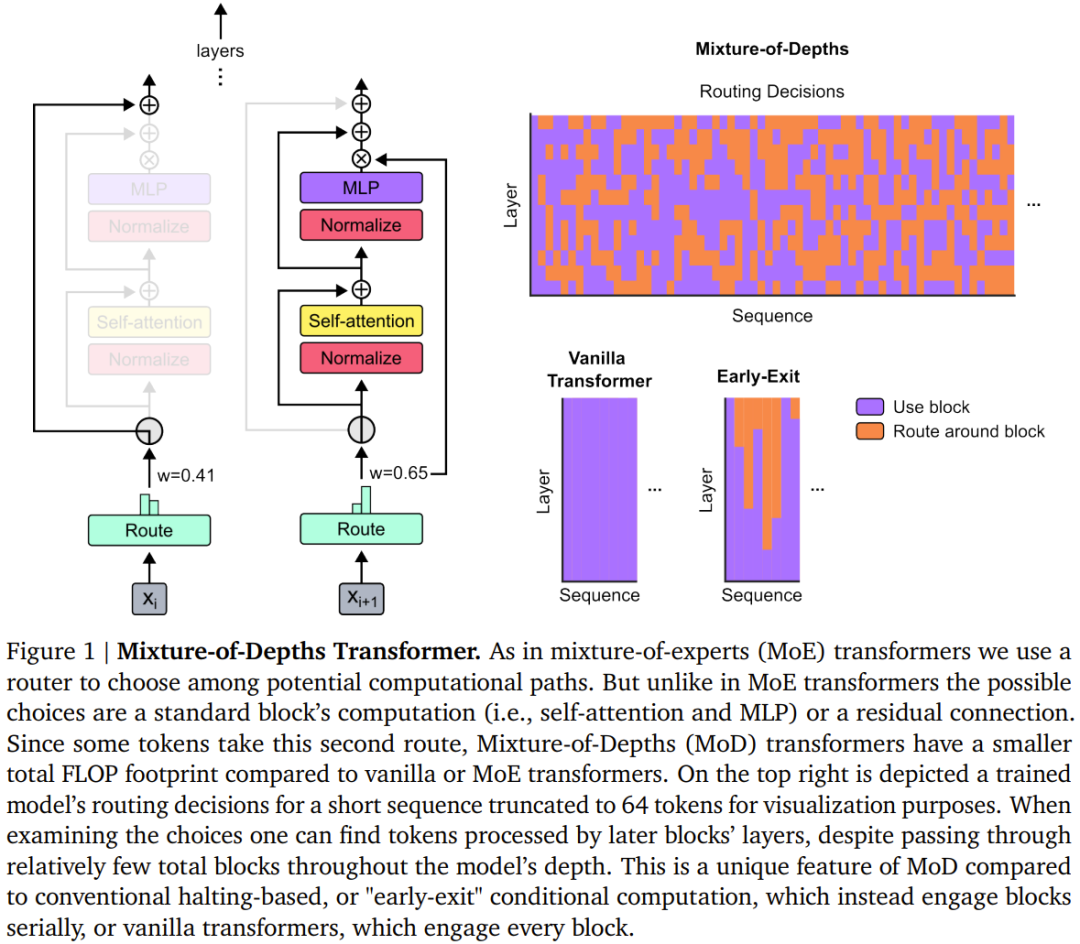
They envisioned: In each layer, the network must learn Decisions are made for each token to dynamically allocate the available computing budget. In their specific implementation, the total computational effort is set by the user before training and never changed, rather than being a function of the network's execution decisions as it works. This allows hardware efficiency gains (such as reduced memory footprint or reduced FLOPs per forward pass) to be anticipated and exploited in advance. The team's experiments show that these gains can be achieved without compromising overall network performance.
#The team at DeepMind adopts an approach similar to the Mixed Expert (MoE) Transformer, where dynamic token-level routing decisions are performed across the entire network depth.
Unlike MoE, their choice here is: either apply the calculation to the token (the same as the standard Transformer), or wrap it around through a residual connection pass it (leave it unchanged, save computation). Another difference from MoE is that this routing mechanism is used for both MLP and multi-head attention. Therefore, this also affects the keys and queries handled by the network, so the route not only decides which tokens are updated, but also which tokens are available for attention.
DeepMind named this strategy Mixture-of-Depths (MoD) to highlight the fact that each token passes through a different number of layers or modules at the Transformer depth . We translate it here as "mixing depth", see Figure 1.
#MoD supports users to weigh performance and speed. On the one hand, users can train the MoD Transformer with the same training FLOPs as a regular Transformer, which can bring up to a 1.5% improvement in the final log-probability training target.The MoD Transformer, on the other hand, uses less computation to achieve the same training loss as a regular Transformer—up to 50% fewer FLOPs per forward pass.
These results show that MoD Transformer can learn to route intelligently (i.e. skip unnecessary computations). Implementing Mixed Depth (MoD) Transformer In summary, the strategy is as follows :
- Set a static calculation budget that is lower than the amount of calculation required by the equivalent regular Transformer; this is done by limiting the amount of calculations in the sequence The number of tokens that can participate in module calculations (ie, self-attention module and subsequent MLP). For example, a regular Transformer may allow all tokens in the sequence to participate in self-attention calculations, but the MoD Transformer can limit the use of only 50% of the tokens in the sequence.
- For each token, there is a routing algorithm in each module that gives a scalar weight; this weight represents the routing preference for each token - whether to participate in the calculation of the module or to bypass it. past.
- In each module, find the top k largest scalar weights, and their corresponding tokens will participate in the calculation of the module. Since only k tokens must participate in the calculation of this module, its calculation graph and tensor size are static during the training process; these tokens are dynamic and context-related tokens recognized by the routing algorithm.
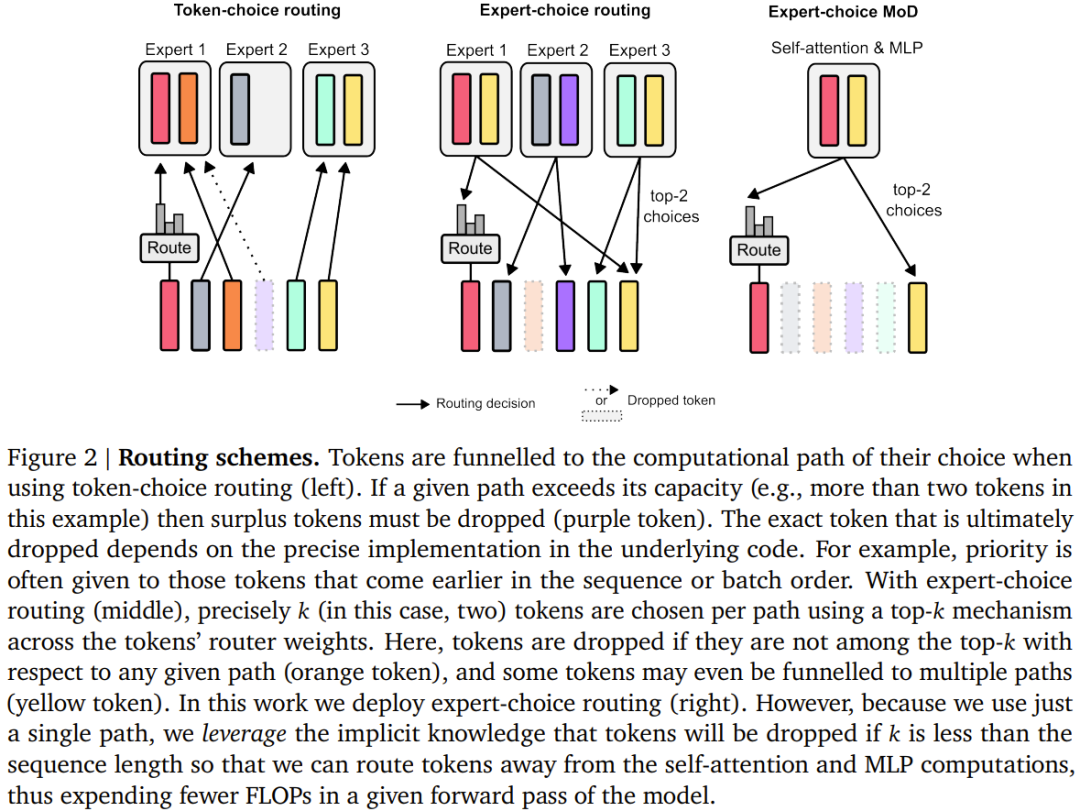
The team considered two The learned routing scheme (see Figure 2): token selection type and expert selection type.
In a token-selective routing scheme, the routing algorithm generates a probability distribution for each token across computational paths (such as across expert identities in MoE Transformer). Tokens are then sent to their preferred path (i.e. the path with the highest probability), and the auxiliary loss ensures that all tokens do not converge to the same path. Token-selective routing may have load balancing issues because tokens are not ensured to be properly divided among possible paths.
Expert selective routing reverses the above scheme: instead of letting tokens choose their preferred paths, each path selects the top k tokens based on token preferences. (top-k). This ensures perfect load balancing as each path is always guaranteed k tokens. However, this may also lead to some tokens being over- or under-processed, because some tokens may be in the top k of multiple paths, and other tokens may have no corresponding path.
DeepMind’s choice is to use expert-selective routing for three reasons.
First, it requires no auxiliary balance loss.
Second, since the operation of selecting the top k depends on the magnitude of the routing weight, this routing scheme allows the use of relative routing weights, which helps determine the current module Calculate which tokens are most needed; the routing algorithm can try to ensure that the most critical tokens are among the top k by appropriately setting the weights - this is something that the token selective routing scheme cannot do. In the specific use case, there is a calculation path that is essentially a null operation, so routing important tokens to null should be avoided.
Third, since routing will only go through two paths, a single top-k operation can efficiently divide the token into two mutually exclusive sets (each Compute a set of paths), which can deal with the over- or under-processing problems mentioned above.
For the specific implementation of this routing scheme, please refer to the original paper.
Although expert selective routing has many advantages, it also has an obvious Problem: Top-k operations are acausal. That is to say, whether the routing weight of a given token is in the top k depends on the value of the routing weight after it, but we cannot obtain these weights when performing autoregressive sampling.
To solve this problem, the team tested two methods.
The first is to introduce a simple auxiliary loss; practice has proven that its impact on the main goal of language modeling is 0.2%−0.3%, but it can make The model samples autoregressively. They used a binary cross-entropy loss, where the output of the routing algorithm provides the logit, and by selecting the top-k of these logits, the target can be provided (i.e., 1 if a token is in top-k, otherwise 0).
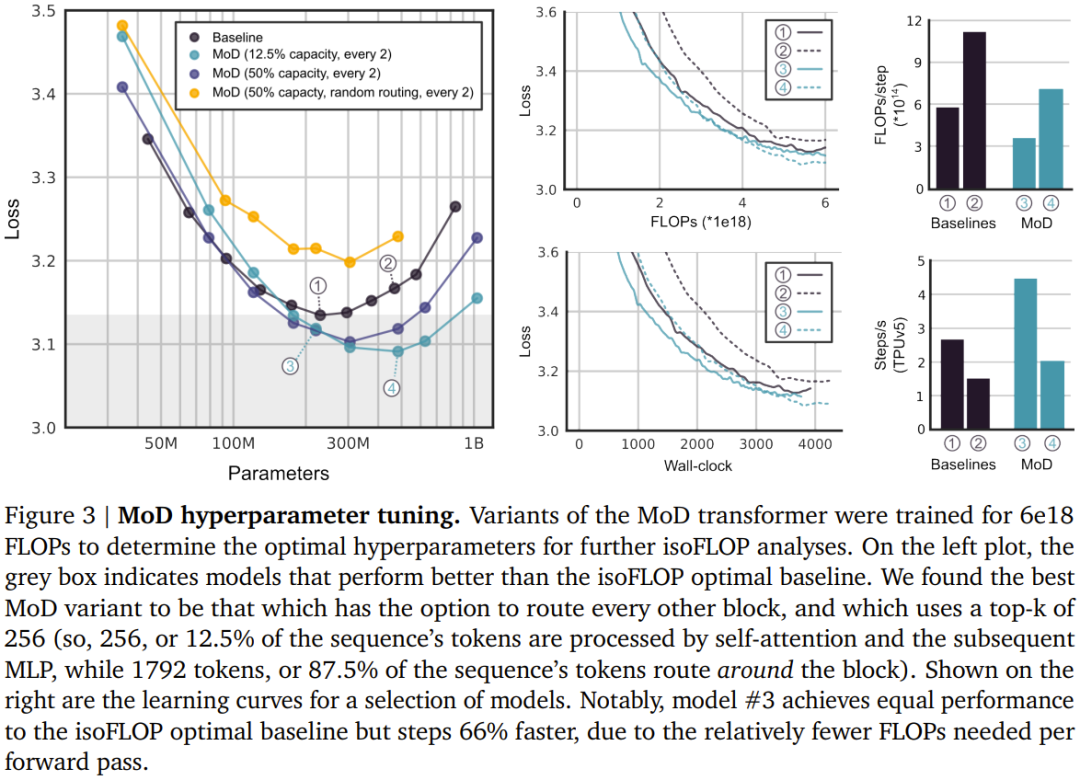
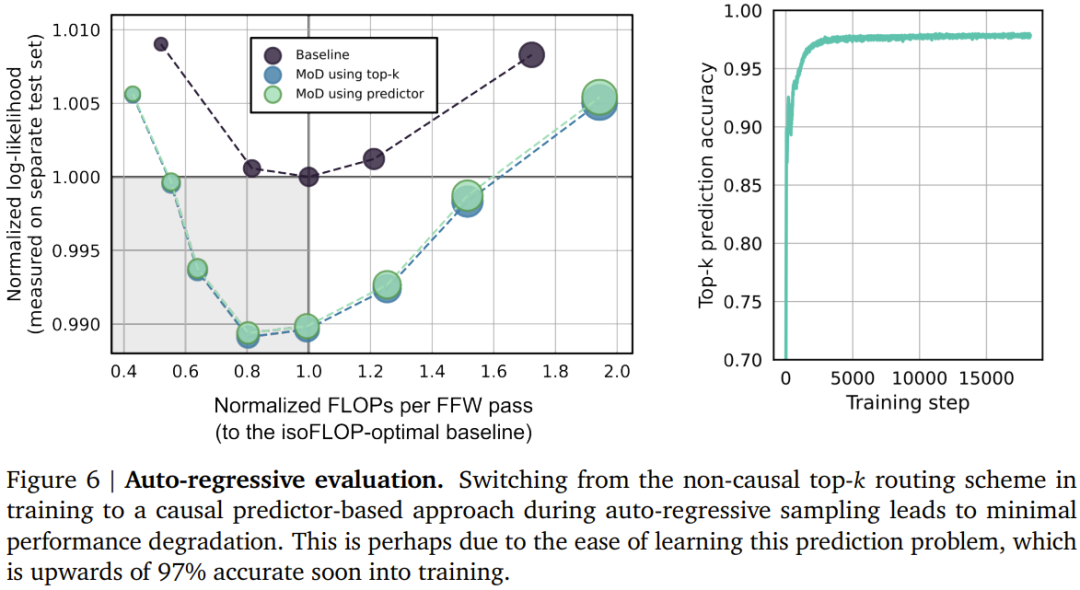
The second method is to introduce a small auxiliary MLP predictor (like another routing algorithm) whose input is the same as the routing algorithm (with stop gradient) , but its output is a prediction result: whether the token is in the top-k of the sequence. This approach does not affect the language modeling goals, and experiments show that it does not significantly affect the speed of this step. With these new methods, it is possible to perform autoregressive sampling by selecting the token to be routed to, or to bypass a module based on the output of the routing algorithm, without dependencies Information about any future tokens. Experimental results show that this is a relatively simple auxiliary task that can quickly achieve 99% accuracy. ##Training, isoFLOP comparison First, the team trained some models with a relatively small FLOP budget (6e18) to determine the optimal hyperparameters (see Figure 3 below).
Overall, you can see that the MoD Transformer drags the baseline isoFLOP curve downward and to the right. In other words, the optimal MoD Transformer has lower loss than the optimal baseline model and also has more parameters. This effect has a lucky result: there are some MoD models that perform as well or better than the optimal baseline model (while being faster in steps), even though they themselves are not isoFLOP-optimal under their hyperparameter settings. . For example, a MoD variant with 220M parameters (model No. 3 in Figure 3) is slightly better than the isoFLOP optimal baseline model (also 220M parameters, model No. 1 in Figure 3), but this MoD variant is Steps during training are over 60% faster.
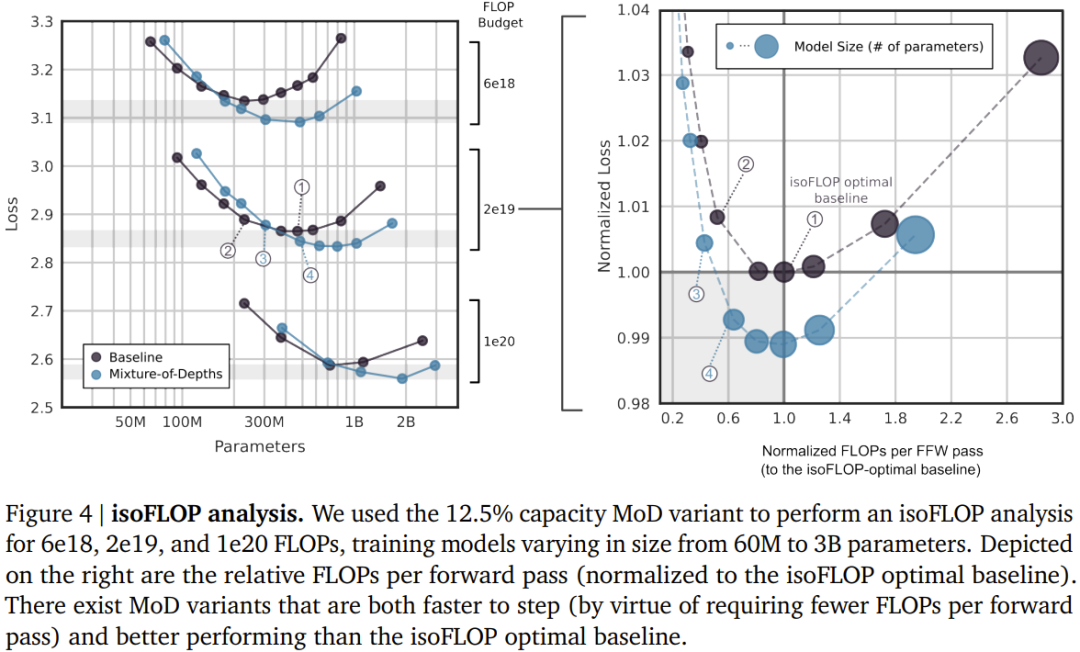
Figure 4 below shows the isoFLOP analysis when the total FLOPs are 6e18, 2e19 and 1e20. As can be seen, the trend continues when the FLOP budget is larger.
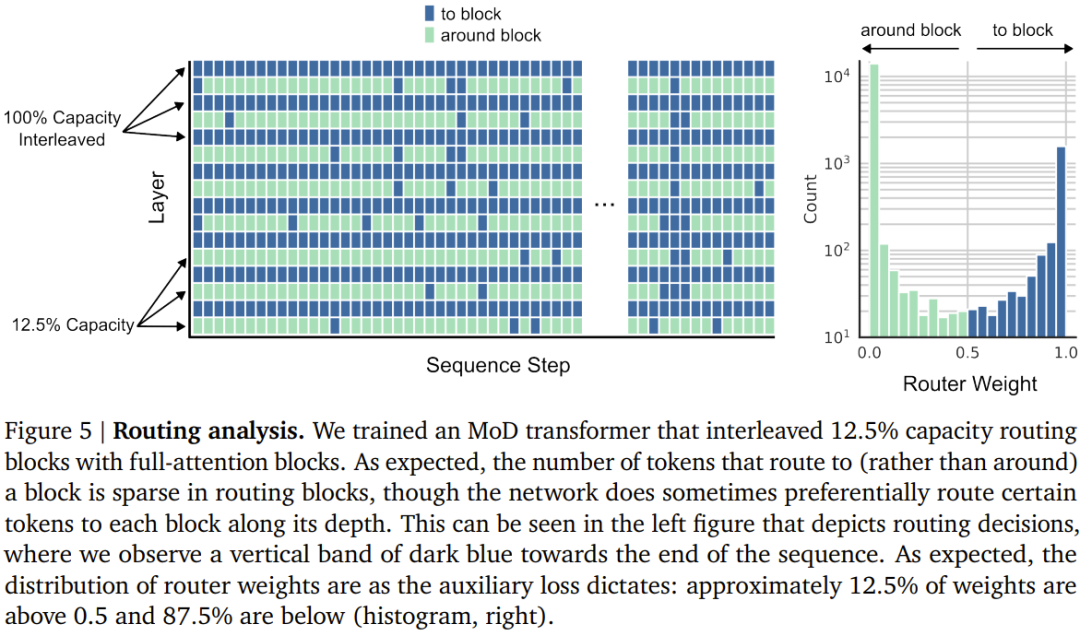
# Figure 5 below shows the routing decision of a MoD Transformer trained using the interleaved routing module. Despite the large number of module bypasses, this MoD Transformer still achieves better performance than the regular Transformer.
Autoregressive evaluationThey also evaluated autoregressive sampling of MoD variants Performance, the results are shown in Figure 6 below. These results demonstrate that the computational savings achieved by the MoD Transformer are not limited to the training setting.
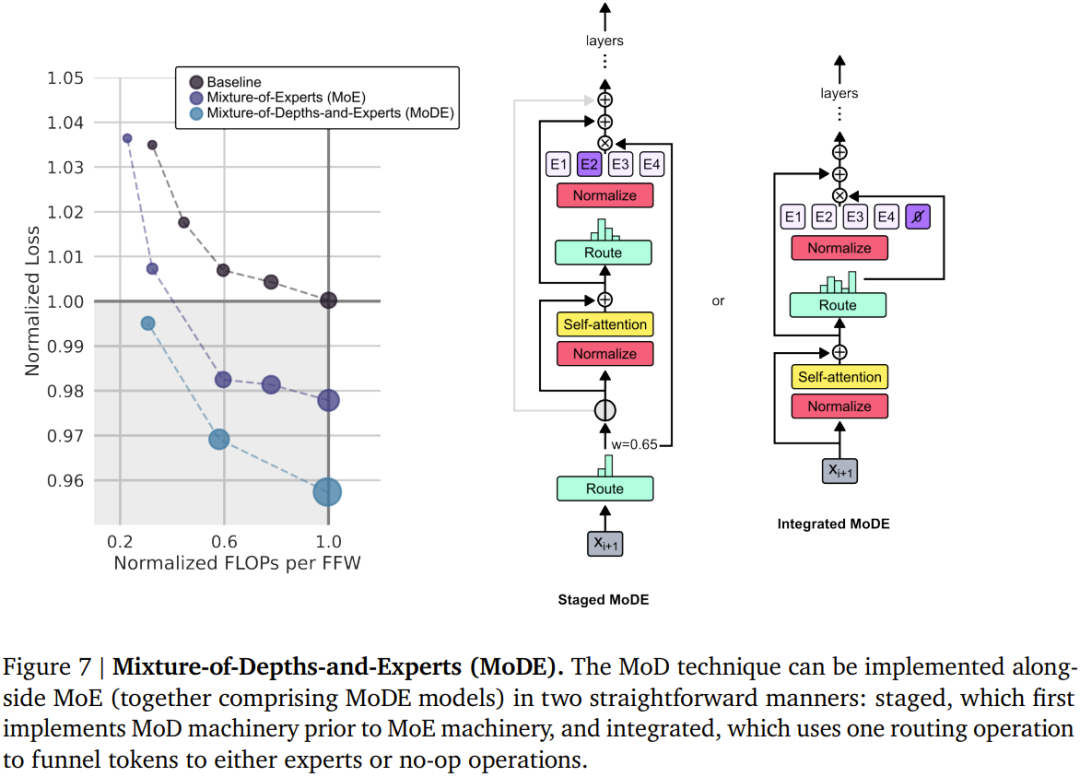
Mixed Depth with Expertise (MoDE) MoD technology works naturally with MoE The models are integrated into so-called MoDE models. Figure 7 below illustrates MoDE and the improvements it brings.
MoDE comes in two variants: staged MoDE and integrated MoDE.
The staged MoDE is to perform routing bypass or reach token operations before the self-attention step; while the integrated MoDE is to integrate between regular MLP experts. "No operation" experts to implement MoD routing. The advantage of the former is that it allows tokens to skip the self-attention step, while the advantage of the latter is that its routing mechanism is simple.
The team noticed that implementing MoDE in an integrated manner is significantly better than designs that directly reduce the capabilities of experts and rely on discarding tokens to achieve residual routing.
The above is the detailed content of DeepMind upgrades Transformer, forward pass FLOPs can be reduced by up to half. For more information, please follow other related articles on the PHP Chinese website!

 Technology peripherals
Technology peripherals
















 1377
1377
 52
52

 What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
 How to run the h5 project
Apr 06, 2025 pm 12:21 PM
How to run the h5 project
Apr 06, 2025 pm 12:21 PM
 Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
 How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
 Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
 How to solve the user_id type conversion problem when using Redis Stream to implement message queues in Go language?
Apr 02, 2025 pm 04:54 PM
How to solve the user_id type conversion problem when using Redis Stream to implement message queues in Go language?
Apr 02, 2025 pm 04:54 PM
 Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
 When using sql.Open, why does not report an error when DSN passes empty?
Apr 02, 2025 pm 12:54 PM
When using sql.Open, why does not report an error when DSN passes empty?
Apr 02, 2025 pm 12:54 PM
