
 Technology peripherals
AI
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Technology peripherals
AI
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!

Written in front & starting point
The end-to-end paradigm uses a unified framework to achieve multi-tasking in the autonomous driving system. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. Furthermore, motion prediction and planning are revisited, while a more reasonable motion planning framework is designed. On the challenging nuScenes dataset, SparseAD achieves state-of-the-art full-task performance in an end-to-end approach and reduces the performance gap between the end-to-end paradigm and single-task approaches.
Field Background
Autonomous driving systems need to make correct decisions in complex driving scenarios to ensure driving safety and comfort. Typically, autonomous driving systems integrate multiple tasks such as detection, tracking, online mapping, motion prediction, and planning. As shown in Figure 1a, the traditional modular paradigm splits complex systems into multiple individual tasks, each of which is optimized independently. In this paradigm, manual post-processing is required between independent single-task modules, which makes the entire process more cumbersome. On the other hand, due to the loss of scene information compression between stacked tasks, errors in the entire system accumulate, which may lead to potential safety issues.
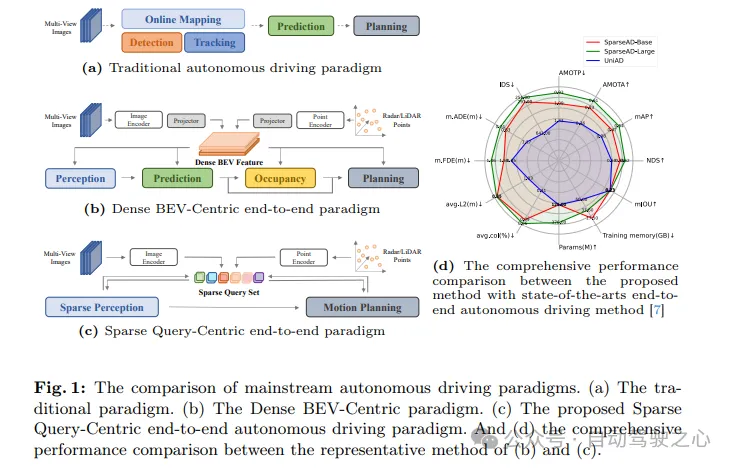
Regarding the above issues, the end-to-end autonomous driving system takes raw perceptron data as input and returns the planning results in a more concise way. Early work proposed skipping intermediate tasks and predicting planning results directly from raw perceptron data. Although this approach is more straightforward, it is not satisfactory in terms of model optimization, interpretability, and planning performance. Another multi-faceted paradigm with better interpretability is to integrate multiple parts of autonomous driving into a modular end-to-end model, which introduces multi-dimensional supervision to improve the understanding of complex driving scenarios, And brings the ability to multi-task.
As shown in Figure 1b, in most advanced modular end-to-end methods, the entire driving scenario is characterized by a dense collection of Bird’s Eye View (BEV) features, which include multi-sensor and temporal information, and serve as input to full-stack driver tasks including sensing, prediction, and planning. Although densely aggregated BEV features play a key role in achieving multi-modality and multi-tasking across space and time, previous end-to-end methods using BEV representation are summarized as the Dense BEV-Centric paradigm. Despite the simplicity and interpretability of these methods, their performance on each subtask of autonomous driving still lags far behind the corresponding single-task methods. In addition, under the Dense BEV-Centric paradigm, long-term temporal fusion and multi-modal fusion are mainly achieved through multiple BEV feature maps, which leads to a significant increase in computing costs and memory usage, and brings a greater burden to actual deployment. .
A novel sparse search-centered end-to-end automatic driving paradigm (SparseAD) is proposed here. In this paradigm, the spatial and temporal elements in the entire driving scene are represented by sparse lookup tables, abandoning the traditional dense ensemble Bird's Eye View (BEV) feature, as shown in Figure 1c. This sparse representation enables end-to-end models to more efficiently utilize longer historical information and scale to more modes and tasks while significantly reducing computational cost and memory footprint.
The modular end-to-end architecture has been redesigned and simplified into a concise structure consisting of sparse sensing and motion planners. In the sparse perception module, a universal temporal decoder is utilized to unify perception tasks including detection, tracking and online mapping. In this process, multi-sensor features and historical records are treated as tokens, while object queries and map queries represent obstacles and road elements in the driving scene respectively. In the motion planner, sparse perception queries are used as environment representation, and multi-modal motion predictions are performed on the vehicle and surrounding agents simultaneously to obtain multiple initial planning solutions for the self-vehicle. Subsequently, multi-dimensional driving constraints are fully considered to generate the final planning results.
Main contributions:
- proposes a novel sparse query-centric end-to-end autonomous driving paradigm (SparseAD), which abandons the traditional dense bird's-eye view (BEV) representation method and therefore has great potential to be able to Efficiently scale to more modalities and tasks.
- Simplify the modular end-to-end architecture into two parts: sparse sensing and motion planning. In the sparse perception part, perception tasks such as detection, tracking, and online mapping are unified in a completely sparse manner; while in the motion planning part, motion prediction and planning are carried out under a more reasonable framework.
- On the challenging nuScenes dataset, SparseAD achieves state-of-the-art performance among end-to-end methods and significantly narrows the performance gap between the end-to-end paradigm and single-task methods. This fully demonstrates the huge potential of the proposed sparse end-to-end paradigm. SparseAD not only improves the performance and efficiency of autonomous driving systems, but also provides new directions and possibilities for future research and applications.
SparseAD network structure
As shown in Figure 1c, in the proposed sparse query-centered paradigm, different sparse queries completely represent the entire The driving scene is not only responsible for information transfer and interaction between modules, but also propagates reverse gradients in multi-tasks for optimization in an end-to-end manner. Different from previous dense set bird's-eye view (BEV)-centered methods, no view projection and dense BEV features are used in SparseAD, thus avoiding heavy computational and memory burdens. The detailed architecture of SparseAD is shown in Figure 2.
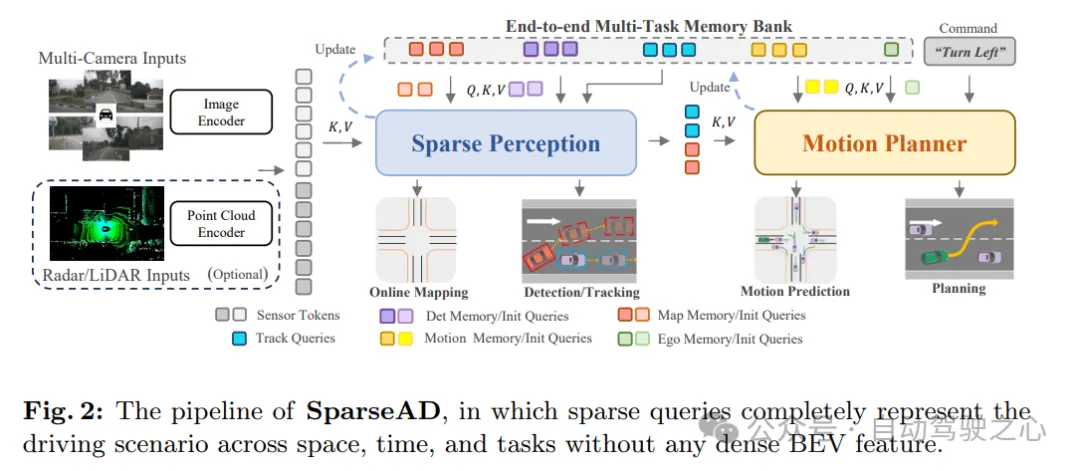
From the architectural diagram, SparseAD mainly consists of three parts, including sensor encoder, sparse perception and motion planner. Specifically, the sensor encoder takes as input multi-view camera images, radar or lidar points and encodes them into high-dimensional features. These features are then input into the sparse sensing module as sensor tokens along with position embeddings (PE). In the sparse sensing module, raw data from sensors will be aggregated into a variety of sparse sensing queries, such as detection queries, tracking queries, and map queries, which respectively represent different elements in the driving scene and will be further propagated to downstream tasks. In the motion planner, the perception query is treated as a sparse representation of the driving scene and is fully exploited for all surrounding agents and the self-vehicle. At the same time, multiple driving constraints are considered to generate a final plan that is both safe and dynamically compliant.
In addition, an end-to-end multi-task memory library is introduced in the architecture to uniformly store the timing information of the entire driving scene, which allows the system to benefit from the aggregation of long-term historical information to complete full-stack driving tasks .
As shown in Figure 3, SparseAD’s sparse perception module unifies multiple perception tasks in a sparse manner, including detection, tracking and online mapping. Specifically, there are two structurally identical temporal decoders that exploit long-term historical information from the memory bank. One of the decoders is used for obstacle sensing and the other is used for online mapping.
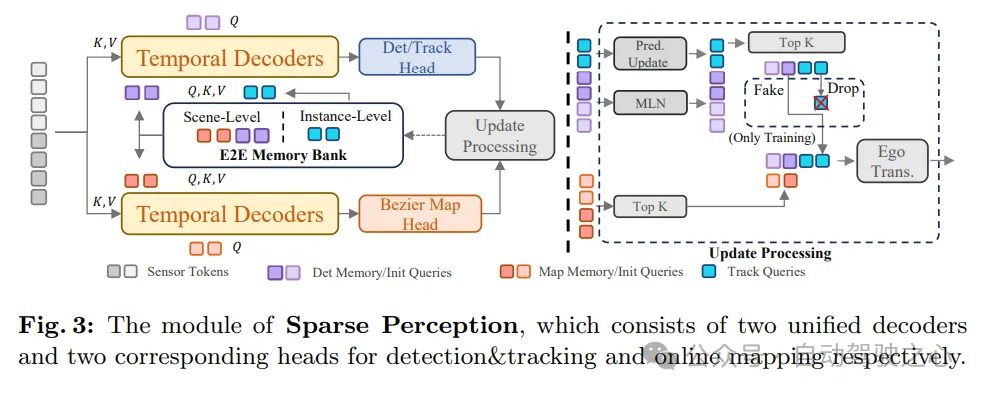
After information aggregation through perception queries corresponding to different tasks, the detection and tracking heads and the map part are used to decode and output obstacles and map elements respectively. After that, an update process is performed, which filters and saves the high-confidence sensing query of the current frame and updates the memory bank accordingly, which will benefit the sensing process of the next frame.
In this way, SparseAD’s sparse perception module achieves efficient and accurate perception of the driving scene, providing an important information basis for subsequent motion planning. At the same time, by utilizing historical information in the memory bank, the module can further improve the accuracy and stability of perception and ensure the reliable operation of the autonomous driving system.
Sparse Perception
In terms of obstacle perception, joint detection and tracking are adopted within a unified decoder without any additional manual post-processing. There is a significant imbalance between detection and tracking queries, which can lead to significant degradation in detection performance. In order to alleviate the above problems, the performance of obstacle sensing has been improved from multiple angles. First, a two-level memory mechanism is introduced to propagate temporal information across frames. Among them, scene-level memory maintains query information without cross-frame correlation, while instance-level memory maintains the correspondence between adjacent frames of tracking obstacles. Secondly, considering the different origins and tasks of the two, different update strategies are adopted for scene-level and instance-level memories. Specifically, scene-level memory is updated via MLN, while instance-level memory is updated with future predictions for each obstacle. Furthermore, during the training process, an enhancement strategy is also adopted for tracking queries to balance the supervision between the two levels of memory, thereby enhancing detection and tracking performance. Afterwards, by detecting and tracking the head, a 3D bounding box with attributes and a unique ID can be decoded from the detection or tracking query and then further used in downstream tasks.
Online map construction is a complex and important task. According to current knowledge, existing online map construction methods mostly rely on dense bird's-eye view (BEV) features to represent the driving environment. This approach has difficulties in extending the sensing range or leveraging historical information because it requires large amounts of memory and computing resources. We firmly believe that all map elements can be represented in a sparse manner, therefore, we try to complete online map construction under the sparse paradigm. Specifically, the same temporal decoder structure as in the obstacle perception task is adopted. Initially, map queries with prior categories are initialized to be uniformly distributed on the driving plane. In the temporal decoder, map queries interact with sensor markers and historical memory markers. These historical memory markers are actually composed of highly confident map queries from previous frames. The updated map query then carries valid information about the map elements of the current frame and can be pushed to the memory bank for use in future frames or downstream tasks.
Obviously, the process of online map construction is roughly the same as obstacle perception. That is, sensing tasks including detection, tracking, and online map construction are unified into a common sparse approach that is more efficient when scaling to larger ranges (e.g., 100m × 100m) or long-term fusion , and does not require any complex operations (such as deformable attention or multi-point attention). To the best of our knowledge, this is the first to implement online map construction in a unified perception architecture in a sparse manner. Subsequently, the piecewise Bezier map Head is used to return the piecewise Bezier control points of each sparse map element, and these control points can be easily transformed to meet the requirements of downstream tasks.
Motion Planner
We re-examined the problem of motion prediction and planning in autonomous driving systems and found that many previous methods ignored this problem when predicting the motion of surrounding vehicles. The dynamics of the ego-vehicle. While this may not be apparent in most situations, it can be a potential risk in scenarios such as intersections where there is close interaction between nearby vehicles and the host vehicle. Inspired by this, a more reasonable motion planning framework was designed. In this framework, the motion predictor predicts the motion of surrounding vehicles and the own vehicle simultaneously. Subsequently, the prediction results of the own vehicle are used as motion priors in subsequent planning optimizers. During the planning process, we consider different aspects of constraints to produce a final planning result that meets both safety and dynamics requirements.
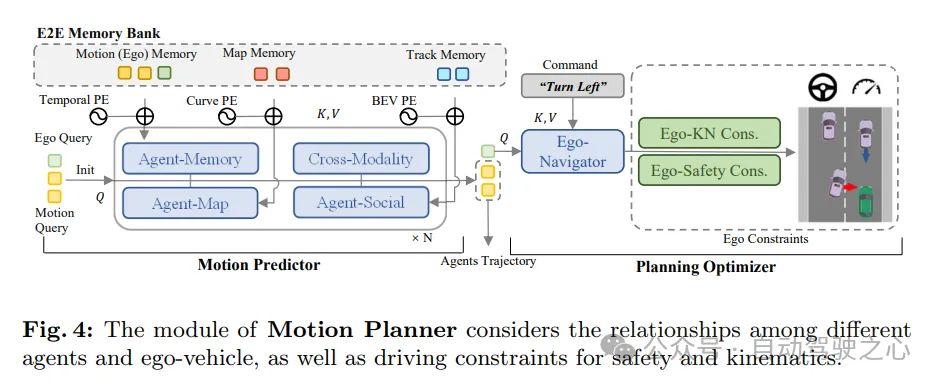
As shown in Figure 4, the motion planner in SparseAD treats perception queries (including trajectory queries and map queries) as a sparse representation of the current driving scene. Multimodal motion queries are used as a medium to enable understanding of driving scenarios, perception of interactions between all vehicles (including the own vehicle), and gaming of different future possibilities. The vehicle's multimodal motion query is then fed into a planning optimizer, which takes into account driving constraints including high-level instructions, safety and dynamics.
Motion Predictor. Following previous methods, the perception and integration between motion queries and current driving scene representations (including trajectory queries and map queries) are achieved through standard transformer layers. In addition, self-vehicle agent and cross-modal interaction are applied to jointly model the interaction between surrounding agents and the self-vehicle in future spatio-temporal scenes. Through module synergy within and between multi-layer stacking structures, motion queries are able to aggregate rich semantic information from both static and dynamic environments.
In addition to the above, two strategies are also introduced to further improve the performance of motion predictors. First, a simple and straightforward prediction is made using the instance-level temporal memory of the trajectory query as part of the initialization of the surrounding agent motion query. In this way, motion predictors are able to benefit from prior knowledge gained from upstream tasks. Second, thanks to the end-to-end memory library, useful information can be assimilated from the saved historical motion queries in a streaming manner through the agent memory aggregator at almost negligible cost.
It should be noted that the multi-modal motion query of this vehicle is updated at the same time. In this way, the motion prior of the own vehicle can be obtained, which can further facilitate the planning learning process.
Planning Optimizer. With the motion prior provided by the motion predictor, better initialization is obtained, resulting in fewer detours during training. As a key component of the motion planner, the design of the cost function is crucial as it will greatly affect or even determine the quality of the final performance. In the proposed SparseAD motion planner, two major constraints, safety and dynamics, are mainly considered, aiming to generate satisfactory planning results. Specifically, in addition to the constraints determined in VAD, it also focuses on the dynamic safety relationship between the vehicle and nearby agents, and considers their relative positions in future moments. For example, if agent i continues to remain in the front left area relative to the vehicle, thereby preventing the vehicle from changing lanes to the left, then agent i will obtain a left label, indicating that agent i imposes a leftward constraint on the vehicle. Constraints are therefore classified as front, back, or none in the longitudinal direction, and as left, right, or none in the transverse direction. In the planner, we decode the relationship between other agents and the vehicle in the horizontal and vertical directions from the corresponding query. This process involves determining the probabilities of all constraints between other agents and the own vehicle in these directions. Then, we utilize focal loss as the cost function of the Ego-Agent relationship (EAR) to effectively capture the potential risks brought by nearby agents:
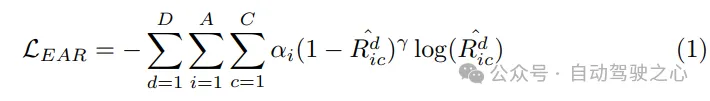
Since the planned trajectory must follow the control The dynamic laws of system execution embed auxiliary tasks in the motion planner to promote the learning of the vehicle's dynamic state. Query Qego to decode states such as speed, acceleration, and yaw angle from the own vehicle, and use dynamics losses to supervise these states:
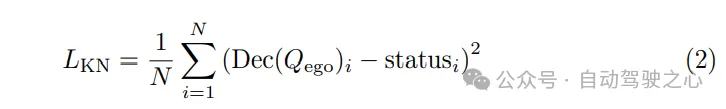
Experimental results
Extensive experiments were conducted on the nuScenes dataset to demonstrate the effectiveness and superiority of the method. To be fair, the performance of each complete task will be evaluated and compared with previous methods. The experiments in this section use three different configurations of SparseAD, namely SparseAD-B and SparseAD-L that only use image input, and SparseAD-BR that uses radar point cloud and image multi-modal input. Both SparseAD-B and SparseAD-BR use V2-99 as the image backbone network, and the input image resolution is 1600 × 640. SparseAD-L further uses ViTLarge as the image backbone network, and the input image resolution is 1600×800.
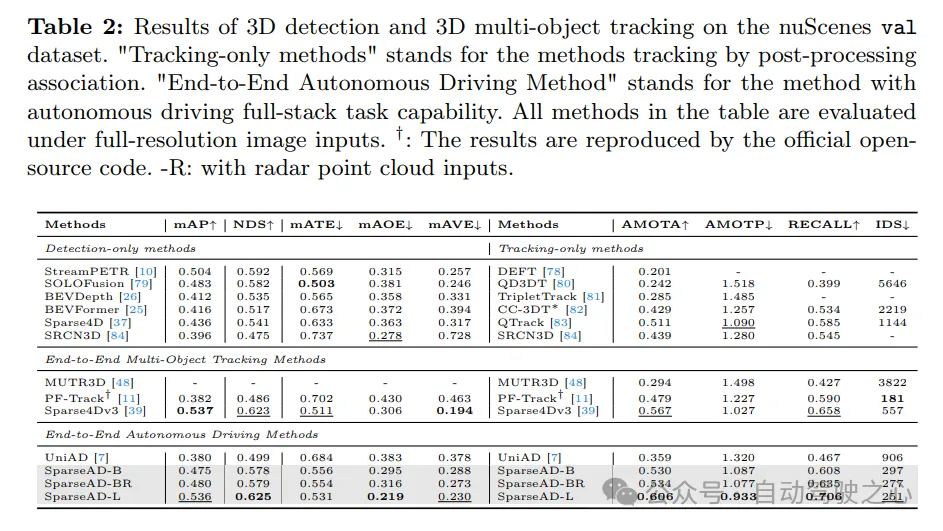
The 3D detection and 3D multi-target tracking results on the nuScenes validation data set are as follows. "Tracking only methods" refers to methods that are tracked through post-processing correlation. “End-to-end autonomous driving method” refers to a method that is capable of full-stack autonomous driving tasks. All methods in the table are evaluated with full resolution image input. †: The results are reproduced through official open source code. -R: Indicates that radar point cloud input is used.
The performance comparison with the online mapping method is as follows. The results are evaluated under the threshold of [1.0m, 1.5m, 2.0m]. ‡: Result reproduced through official open source code. †: Based on the needs of the planning module in SparseAD, we further subdivided the boundary into road segments and lanes and evaluated them separately. ∗: Cost of backbone network and sparse sensing module. -R: Indicates that radar point cloud input is used.

Multi-Task Result
Obstacle Perception. The detection and tracking performance of SparseAD is compared with other methods on the nuScenes validation set in Tab. 2. Obviously, SparseAD-B performs well in most popular detection-only, tracking-only and end-to-end multi-object tracking methods, while performing equivalently to SOTA methods such as StreamPETR and QTrack on the corresponding tasks. By scaling up with a more advanced backbone network, SparseAD-Large achieves overall better performance, with mAP of 53.6%, NDS of 62.5%, and AMOTA of 60.6%, which is overall better than the previous best method Sparse4Dv3.
Online mapping. Tab. 3 shows the comparison results of online mapping performance between SparseAD and other previous methods on the nuScenes validation set. It should be pointed out that according to planning needs, we subdivided the boundary into road segments and lanes and evaluated them separately, while extending the range from the usual 60m × 30m to 102.4m × 102.4m to be consistent with obstacle perception. Without losing fairness, SparseAD achieves 34.2% mAP in a sparse end-to-end manner without any dense BEV representation, which is better than most previously popular methods, such as HDMapNet, VectorMapNet and MapTR, in terms of performance It has obvious advantages in terms of training cost and cost. Although the performance is slightly inferior to StreamMapNet, our method demonstrates that online mapping can be done in a uniform sparse manner without any dense BEV representation, which has implications for practical deployment of end-to-end autonomous driving at significantly lower cost. Significance. Admittedly, how to effectively utilize useful information from other modalities (such as radar) is still a task worthy of further exploration. We believe there is still much room for exploration in a sparse manner.
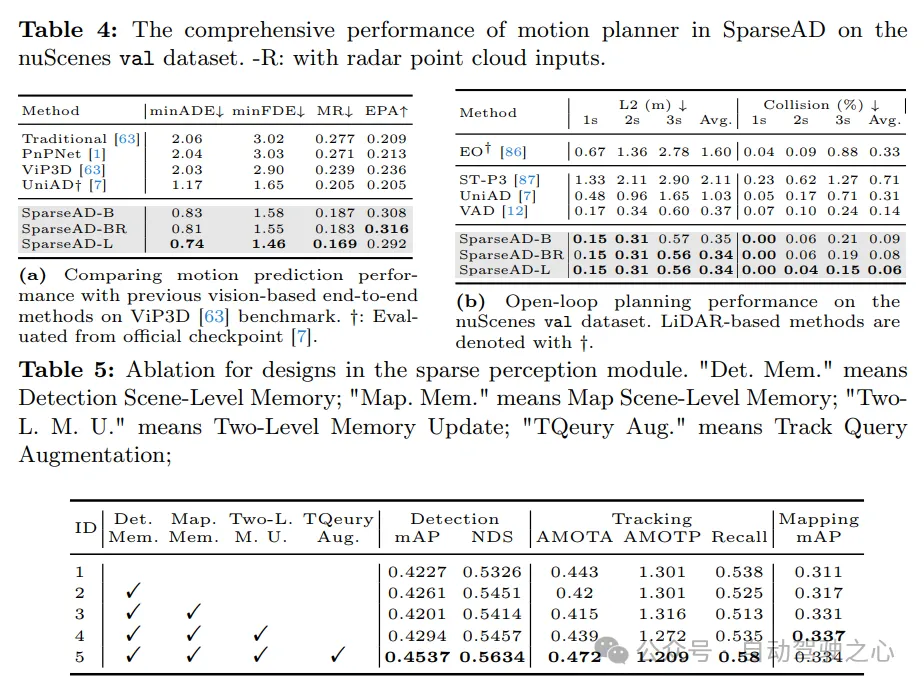
Motion prediction. The comparison results of motion prediction are shown in Tab. 4a, where the indicators are consistent with VIP3D. SparseAD achieves the best performance among all end-to-end methods, with the lowest 0.83m minADE, 1.58m minFDE, 18.7% miss rate, and the highest 0.308 EPA, which is a huge advantage. In addition, thanks to the efficiency and scalability of the sparse query center paradigm, SparseAD can effectively expand to more modalities and benefit from the advanced backbone network to further significantly improve prediction performance.
planning. The results of the planning are presented in Tab. 4b. Thanks to the superior design of the upstream perception module and motion planner, all versions of SparseAD achieve state-of-the-art performance on the nuScenes validation dataset. Specifically, SparseAD-B achieves the lowest average L2 error and collision rate compared to all other methods including UniAD and VAD, which demonstrates the superiority of our approach and architecture. Similar to upstream tasks including obstacle perception and motion prediction, SparseAD further improves performance with radar or a more powerful backbone network.

The above is the detailed content of nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 What to do if your Huawei phone has insufficient memory (Practical methods to solve the problem of insufficient memory)
Apr 29, 2024 pm 06:34 PM
What to do if your Huawei phone has insufficient memory (Practical methods to solve the problem of insufficient memory)
Apr 29, 2024 pm 06:34 PM
Insufficient memory on Huawei mobile phones has become a common problem faced by many users, with the increase in mobile applications and media files. To help users make full use of the storage space of their mobile phones, this article will introduce some practical methods to solve the problem of insufficient memory on Huawei mobile phones. 1. Clean cache: history records and invalid data to free up memory space and clear temporary files generated by applications. Find "Storage" in the settings of your Huawei phone, click "Clear Cache" and select the "Clear Cache" button to delete the application's cache files. 2. Uninstall infrequently used applications: To free up memory space, delete some infrequently used applications. Drag it to the top of the phone screen, long press the "Uninstall" icon of the application you want to delete, and then click the confirmation button to complete the uninstallation. 3.Mobile application to
 Detailed steps for cleaning memory in Xiaohongshu
Apr 26, 2024 am 10:43 AM
Detailed steps for cleaning memory in Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Open Xiaohongshu, click Me in the lower right corner 2. Click the settings icon, click General 3. Click Clear Cache
 How to fine-tune deepseek locally
Feb 19, 2025 pm 05:21 PM
How to fine-tune deepseek locally
Feb 19, 2025 pm 05:21 PM
Local fine-tuning of DeepSeek class models faces the challenge of insufficient computing resources and expertise. To address these challenges, the following strategies can be adopted: Model quantization: convert model parameters into low-precision integers, reducing memory footprint. Use smaller models: Select a pretrained model with smaller parameters for easier local fine-tuning. Data selection and preprocessing: Select high-quality data and perform appropriate preprocessing to avoid poor data quality affecting model effectiveness. Batch training: For large data sets, load data in batches for training to avoid memory overflow. Acceleration with GPU: Use independent graphics cards to accelerate the training process and shorten the training time.
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
The familiar open source large language models such as Llama3 launched by Meta, Mistral and Mixtral models launched by MistralAI, and Jamba launched by AI21 Lab have become competitors of OpenAI. In most cases, users need to fine-tune these open source models based on their own data to fully unleash the model's potential. It is not difficult to fine-tune a large language model (such as Mistral) compared to a small one using Q-Learning on a single GPU, but efficient fine-tuning of a large model like Llama370b or Mixtral has remained a challenge until now. Therefore, Philipp Sch, technical director of HuggingFace
 What to do if the Edge browser takes up too much memory What to do if the Edge browser takes up too much memory
May 09, 2024 am 11:10 AM
What to do if the Edge browser takes up too much memory What to do if the Edge browser takes up too much memory
May 09, 2024 am 11:10 AM
1. First, enter the Edge browser and click the three dots in the upper right corner. 2. Then, select [Extensions] in the taskbar. 3. Next, close or uninstall the plug-ins you do not need.
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
