
 Technology peripherals
AI
Thoughts and practice on assisted generation of B-end front-end code under large models
Technology peripherals
AI
Thoughts and practice on assisted generation of B-end front-end code under large models
Thoughts and practice on assisted generation of B-end front-end code under large models

1. Background
During the reconstruction work, code specifications: During the B-end front-end development process, developers will always face the pain point of repeated development. The element modules of many CRUD pages are basically similar, but still It requires manual development and spends time on building simple elements, which reduces the development efficiency of business requirements. At the same time, because the coding styles of different developers are inconsistent, it makes it more expensive for others to get started during iterations.
AI replaces simple brainpower: With the continuous development of large AI models, it already has simple understanding capabilities and can convert language into instructions. General instructions for building basic pages can meet the needs of daily basic page building and improve the efficiency of business development in general scenarios.
2. List of generated links
B-side page lists, forms, and details all support generation. Links can be roughly divided into the following steps.
 Picture
Picture
- Input natural language
- Combined with the large model to extract the corresponding construction information according to the specified rules
- Build information combined with code template and AST output front-end code
3. Express requirements
Graphic configuration
The first step is to tell it what kind of interface to develop. When mentioning this, the first thing we think of is page configuration, which is the current mainstream form of low-code products. Users build pages through a series of graphical configurations, as shown below:
 Picture
Picture
It has a good efficiency improvement effect on general scenarios (such as CURD pages with relatively simple background management) or specific business scenarios (such as conference venue construction). For relatively complex requirements that require continuous iteration of logic, since configuration is done through graphical operations, the requirements for interactive design are higher, and there is a certain cost to get started. At the same time, as the complexity of the requirements becomes higher and higher, the configuration Form interactions are becoming more and more complex and maintenance costs are getting higher and higher. Therefore, the use of front-end fields in page configuration is relatively restrained.
AI directly generates code
AI generated code is mostly used in tool function scenarios, but for the needs of specific business scenarios within the company, You may need to consider the following points:
- Generate customization: The company team has its own technology stack and heavy-duty common components. This knowledge needs to be pre-trained. Currently, the pre-training content for long texts is only Supports single session injection, and consumes a high number of tokens;
- Accuracy: The accuracy challenge of AI-generated code is relatively large, and pre-training includes a large section of prompts because the code output contains too many details. , coupled with model illusion, the failure rate of business code is currently relatively high, and accuracy is the core indicator for considering auxiliary coding. If this cannot be solved, the effect of auxiliary coding will be greatly reduced;
- Generate Incomplete content: Due to the limitation of a single GPT session, for complex requirements, there is a certain chance that code generation will be truncated, affecting the generation success rate.
Natural language to instruction
#GPT actually has a very important ability, that is, natural language to instruction, the instruction is Action, for example: Let's assume that a function method is implemented, and the input is natural language. Combined with GPT and the built-in prompt, let it output certain words stably. Can we take further actions by outputting these words? ? This has the following advantages over graphical configuration:
- Low learning threshold: because natural language itself is the native language of human beings, you only need to describe the page according to your ideas, of course. The content needs to follow some specifications, but the efficiency is significantly improved compared to graphical configuration;
- Complexity black box: The complexity of graphical configuration will increase with the complexity of the configuration page. Rise, and this complexity will be displayed in front of the user at a glance. The user may get lost in the complex configuration page interaction, and the configuration cost will gradually increase;
- Agile iteration: If you want to add a new one on the user side For page configuration functions, the interaction method based on large models may only require the addition of a few prompts, but graphical configuration requires the development of complex forms to facilitate quick input.
You may have a question here:
Wouldn’t the generated command information also show the illusion of a large model? How to ensure that the command information generated each time is stable and consistent?
Natural language conversion to instructions is feasible for the following reasons:
- Converting long text to key information belongs to summary content, and the accuracy of large models in summary scenarios is much higher than that in diffusion scenarios;
- Since the instruction information only extracts key information in the requirements, it does not Pre-training on the code technology stack is required, so there is a lot of room for optimization of prompts. By optimizing and improving prompt content, the output accuracy can be effectively improved;
- The accuracy can be verified, and different expression requirements are required for each scenario. Input, the accuracy can be verified through the single test prediction output. When a badCase occurs, we will access the single test for the badCase after optimization. Ensure accuracy continues to improve.
Let us look at the final information conversion results:
For code assistance, based on the user's demand description, such information can be obtained through PROMPT processing. Provide basic information for code generation.
 Picture
Picture
4. Convert information into code
Get the codable information corresponding to natural language through the large model (i.e. the above example JSON in), we can convert the code based on this information. For a page with a clear scenario, it can generally be divided into main code template (list, form, description frame) and business components.
Conversion process
 Picture
Picture
How do we Developing code?
In fact, this step is very similar to developing the code ourselves. After we get the requirements, our brain will extract the key information, that is, the natural language conversion instructions mentioned above, and then we will Create a file in vscode, and then perform the following operations:
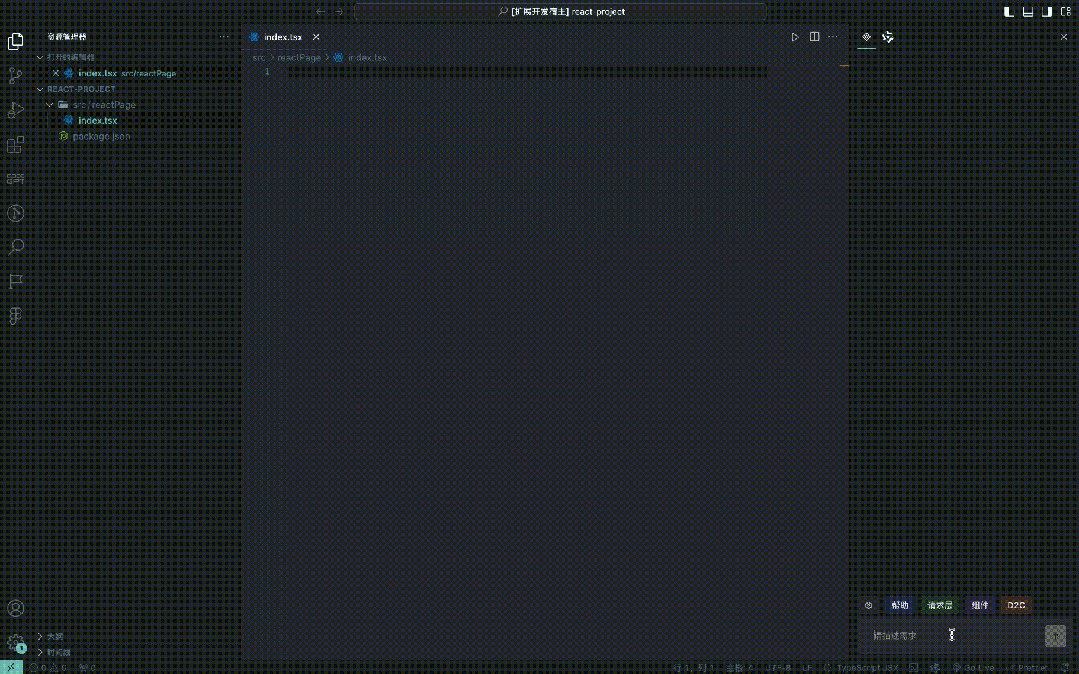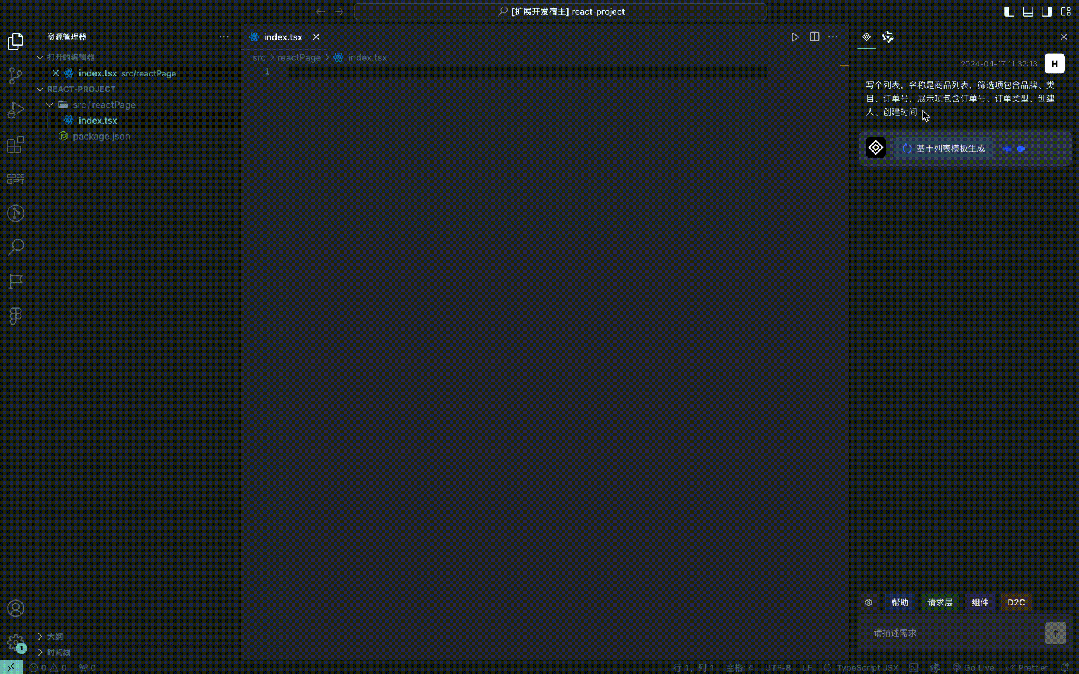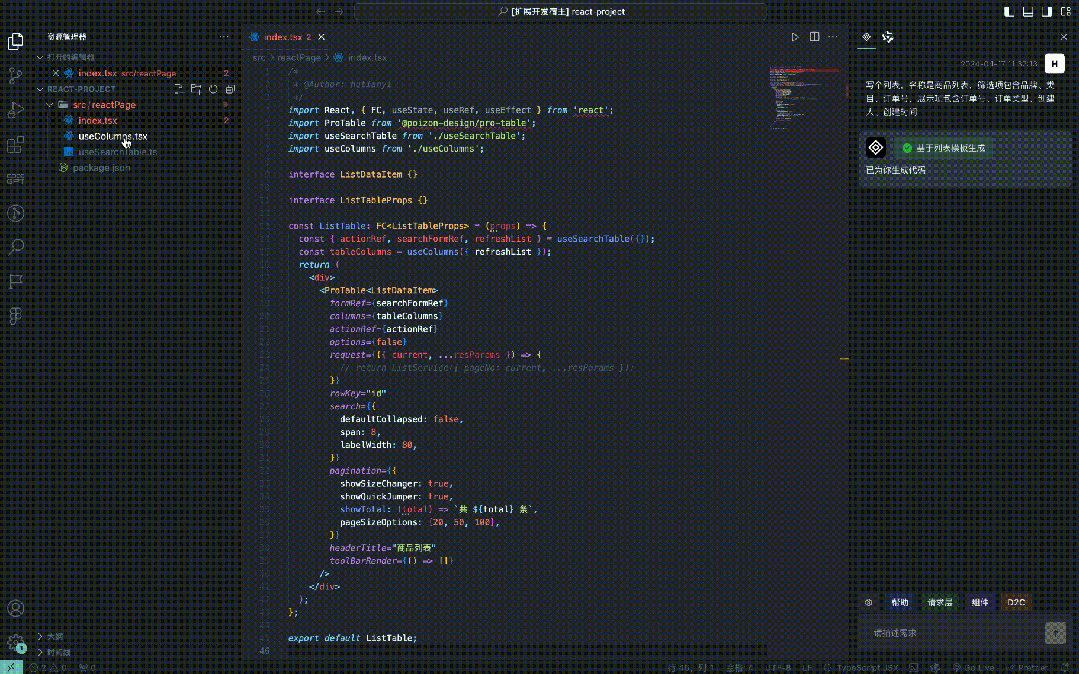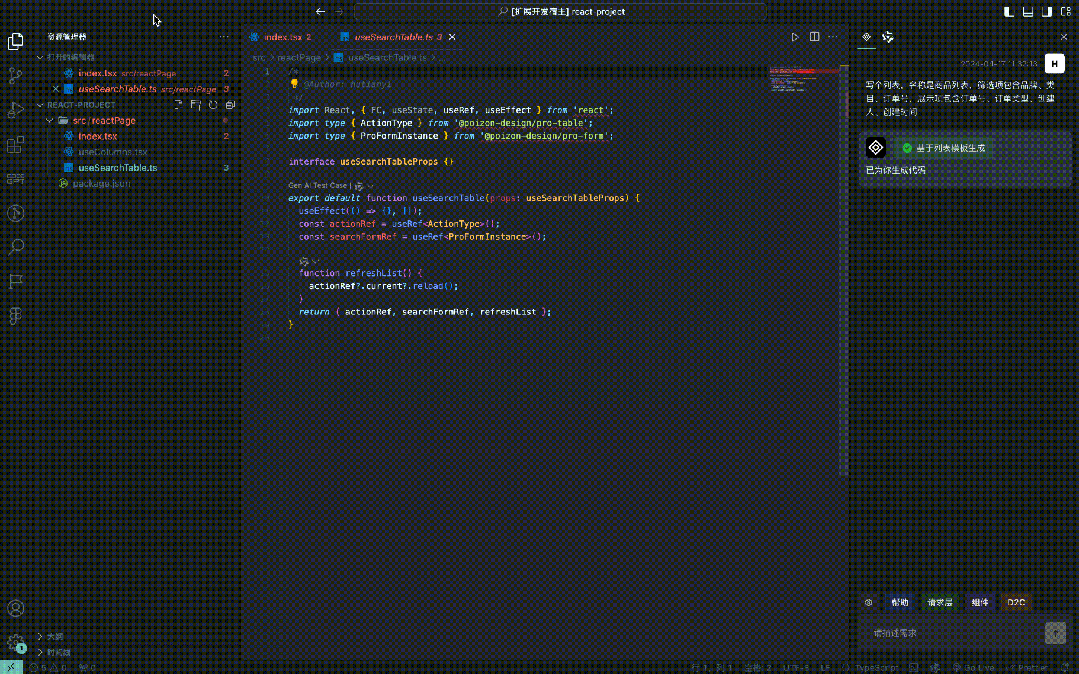
First, you must create a code template, and then introduce corresponding heavy-duty components according to the scenario. For example, ProTable is introduced for lists, and ProForm is introduced for forms.
Based on heavy-duty components such as ProTable and adding some properties to it, such as headerTitle, pageSize and other list-related information.
Introduce components according to the demand description. For example, if it is recognized that there is a category selection in the filter item, a new business component will be added in useColumns. If it is recognized that there is an import and export component in the demand description, a new import will be added at the specified position on the page. Export business components.
Get the mock link, add a request layer, and introduce it at the specified location on the page.
The above common code insertion scenarios can be encapsulated into JSON, and then the corresponding code is generated through code templates combined with AST insertion or string template replacement.
5. Source code generation
Positioning
Source code assistance mainly helps developers reduce repetitive work and improve coding efficiency. It is a completely different track from low-code page construction. Low-code focuses on building a complete page in a specific scenario, and the number of page functions is enumerable. There are also excellent practices in low-code construction in the industry. The source code auxiliary tool is designed to help users initialize as much business requirement code as possible, and subsequent modification and maintenance is handed over to users at the code level to improve the development efficiency of new pages.
See the specific functional architecture below:
 Picture
Picture
6. Component vector search and embedding
For the front-end In terms of development, the essence of efficiency improvement is to develop less code. Faster page generation is one aspect. Good component extraction is a very important part. We combined vectors to optimize the introduction links of components. In the initialization template Quickly search and locate components in existing codes.
Component vector introduction link
 Picture
Picture
Component information entry
Supports quick acquisition of component description content and component introduction paradigm. Enter components with one click, and the component description will be converted into vector data and stored in the vector database.
 Picture
Picture
Component vector search
After the user enters the description, it will The description is converted into a vector, and the component list is compared based on cosine similarity to find the TOP N components with the highest similarity.
 Picture
Picture
Quick insertion of components
Users can quickly insert Search the component with the highest matching degree by description and press Enter to insert.
 Picture
Picture
7. Future Outlook
- Component embedding template: Currently, the component supports vector search and is generated by combining the source code page. Dynamically match components and embed templates;
- Editing and generating existing code: Currently only source code generation for new pages is supported, and local code addition for existing pages will be supported in the future;
- Code template pipeline: AST's code operation tooling further connects natural language and code writing, improving the efficiency of scene expansion.
The above is the detailed content of Thoughts and practice on assisted generation of B-end front-end code under large models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1376
1376
 52
52

 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
How to solve mysql cannot be started
Apr 08, 2025 pm 02:21 PM
There are many reasons why MySQL startup fails, and it can be diagnosed by checking the error log. Common causes include port conflicts (check port occupancy and modify configuration), permission issues (check service running user permissions), configuration file errors (check parameter settings), data directory corruption (restore data or rebuild table space), InnoDB table space issues (check ibdata1 files), plug-in loading failure (check error log). When solving problems, you should analyze them based on the error log, find the root cause of the problem, and develop the habit of backing up data regularly to prevent and solve problems.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Understand ACID properties: The pillars of a reliable database
Apr 08, 2025 pm 06:33 PM
Detailed explanation of database ACID attributes ACID attributes are a set of rules to ensure the reliability and consistency of database transactions. They define how database systems handle transactions, and ensure data integrity and accuracy even in case of system crashes, power interruptions, or multiple users concurrent access. ACID Attribute Overview Atomicity: A transaction is regarded as an indivisible unit. Any part fails, the entire transaction is rolled back, and the database does not retain any changes. For example, if a bank transfer is deducted from one account but not increased to another, the entire operation is revoked. begintransaction; updateaccountssetbalance=balance-100wh
 Can mysql return json
Apr 08, 2025 pm 03:09 PM
Can mysql return json
Apr 08, 2025 pm 03:09 PM
MySQL can return JSON data. The JSON_EXTRACT function extracts field values. For complex queries, you can consider using the WHERE clause to filter JSON data, but pay attention to its performance impact. MySQL's support for JSON is constantly increasing, and it is recommended to pay attention to the latest version and features.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 MySQL can't be installed after downloading
Apr 08, 2025 am 11:24 AM
MySQL can't be installed after downloading
Apr 08, 2025 am 11:24 AM
The main reasons for MySQL installation failure are: 1. Permission issues, you need to run as an administrator or use the sudo command; 2. Dependencies are missing, and you need to install relevant development packages; 3. Port conflicts, you need to close the program that occupies port 3306 or modify the configuration file; 4. The installation package is corrupt, you need to download and verify the integrity; 5. The environment variable is incorrectly configured, and the environment variables must be correctly configured according to the operating system. Solve these problems and carefully check each step to successfully install MySQL.
 Laravel Eloquent ORM in Bangla partial model search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent ORM in Bangla partial model search)
Apr 08, 2025 pm 02:06 PM
LaravelEloquent Model Retrieval: Easily obtaining database data EloquentORM provides a concise and easy-to-understand way to operate the database. This article will introduce various Eloquent model search techniques in detail to help you obtain data from the database efficiently. 1. Get all records. Use the all() method to get all records in the database table: useApp\Models\Post;$posts=Post::all(); This will return a collection. You can access data using foreach loop or other collection methods: foreach($postsas$post){echo$post->
