
 Technology peripherals
AI
CVPR 2024 | AI can also highly restore the flying skirt when dancing. Nanyang Polytechnic proposes a new paradigm for dynamic human body rendering
Technology peripherals
AI
CVPR 2024 | AI can also highly restore the flying skirt when dancing. Nanyang Polytechnic proposes a new paradigm for dynamic human body rendering
CVPR 2024 | AI can also highly restore the flying skirt when dancing. Nanyang Polytechnic proposes a new paradigm for dynamic human body rendering


The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

Paper title: SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering Paper address : https://arxiv.org/pdf/2404.01225.pdf Project homepage: https://taohuumd.github.io/projects/SurMo Github link: https://github.com/TaoHuUMD/SurMo

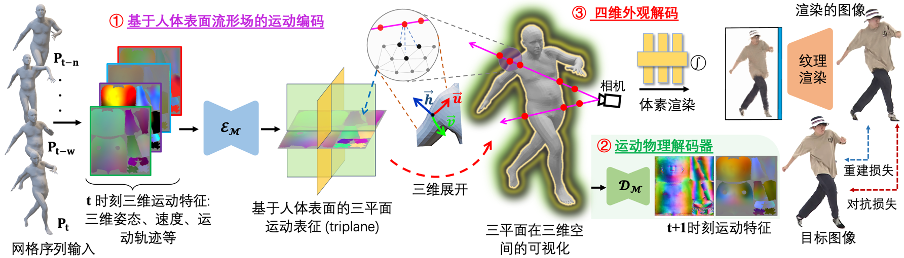
Different from existing methods that model motion in sparse three-dimensional space, SurMo proposes Four-dimensional (XYZ-T) motion modeling based on the human body surface manifold field (or compact two-dimensional texture UV space), and through three planes (surface -based triplane) to represent motion. - Propose a motion physics decoder to predict the motion state of the next frame based on the current motion features (such as three-dimensional posture, speed, motion trajectory, etc.), such as the spatial partial derivative of motion—surface normal vector and time derivative-velocity to model the continuity of motion characteristics.
- Four-dimensional appearance decoding, decoding motion features in time series to render three-dimensional free-viewpoint video, mainly realized through hybrid volumetric-texture neural rendering (Hybrid Volumetric-Textural Rendering, HVTR [Hu et al. 2022]).
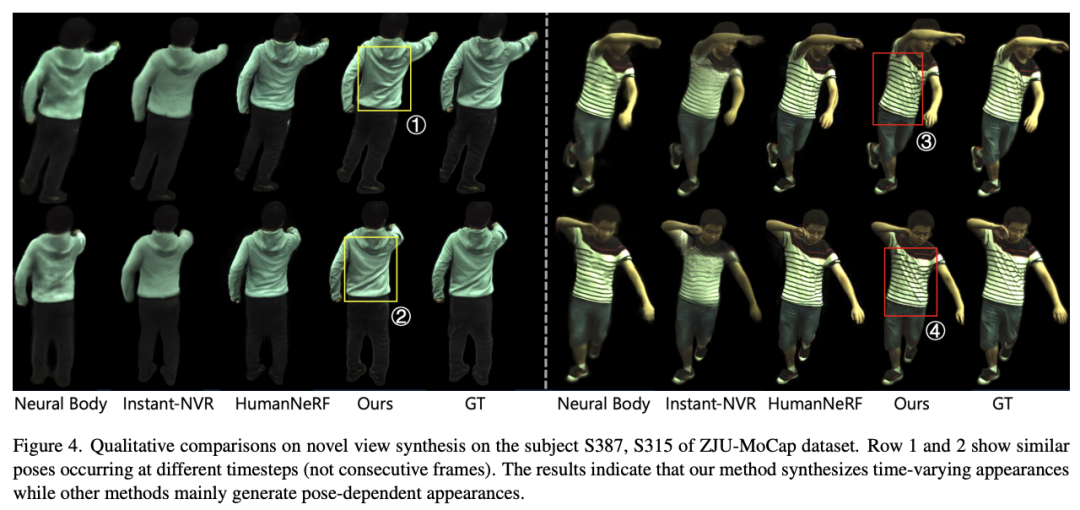
##This study explores the new viewpoint on the ZJU-MoCap data set Next, we studied the dynamic rendering effect of a time sequence (time-varying appearances), especially 2 sequences, as shown in the figure below. Each sequence contains similar gestures but appear in different motion trajectories, such as ①②, ③④, ⑤⑥. SurMo can model motion trajectories and therefore generate dynamic effects that change over time, while related methods generate results that only depend on posture, with the folds of clothes being almost the same under different trajectories.

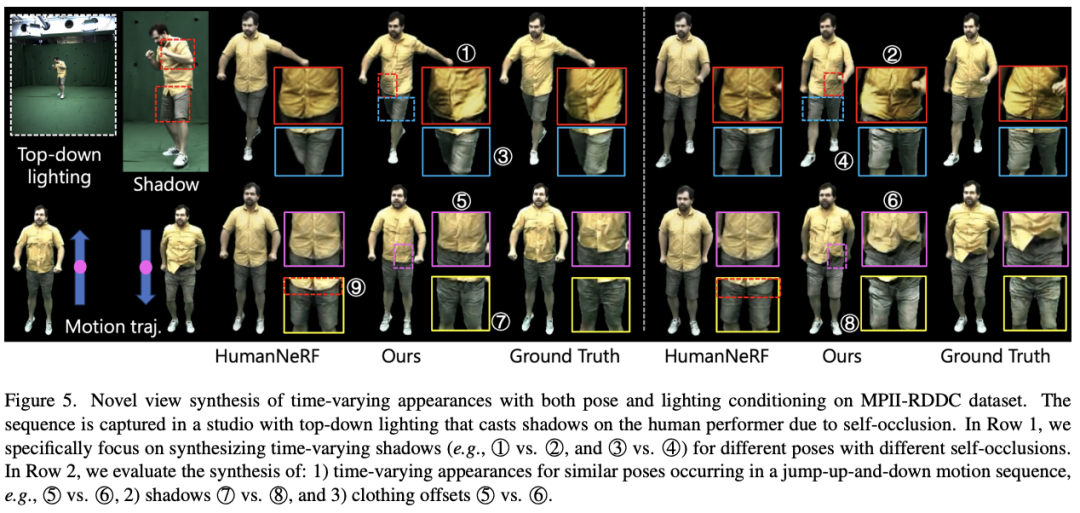
SurMo at MPII-RRDC The data set explores motion-related shadows and clothing-affiliated movements, as shown in the figure below. The sequence was shot on an indoor soundstage, and the lighting conditions produced motion-related shadows on the performers due to self-occlusion issues.
SurMo can restore these shadows under new viewpoint rendering, such as ①②, ③④, ⑦⑧. The contrasting method HumanNeRF [Weng et al.] is unable to recover motion-related shadows. In addition, SurMo can reconstruct the motion of clothing accessories that changes with the motion trajectory, such as different folds in jumping movements ⑤⑥, while HumanNeRF cannot reconstruct this dynamic effect.
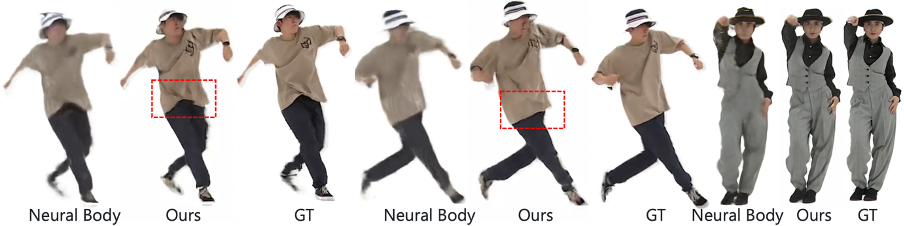
SurMo Also from Render the human body in fast-moving videos and recover the movement-related details of clothing folds that contrasting methods cannot render.
(1) Human body surface movement Modeling
This study compared two different motion modeling methods: the currently commonly used motion modeling in voxel space (Volumetric space), and the motion modeling proposed by SurMo In the motion modeling of the human body surface manifold field (Surface manifold), Volumetric triplane and Surface-based triplane are specifically compared, as shown in the figure below.
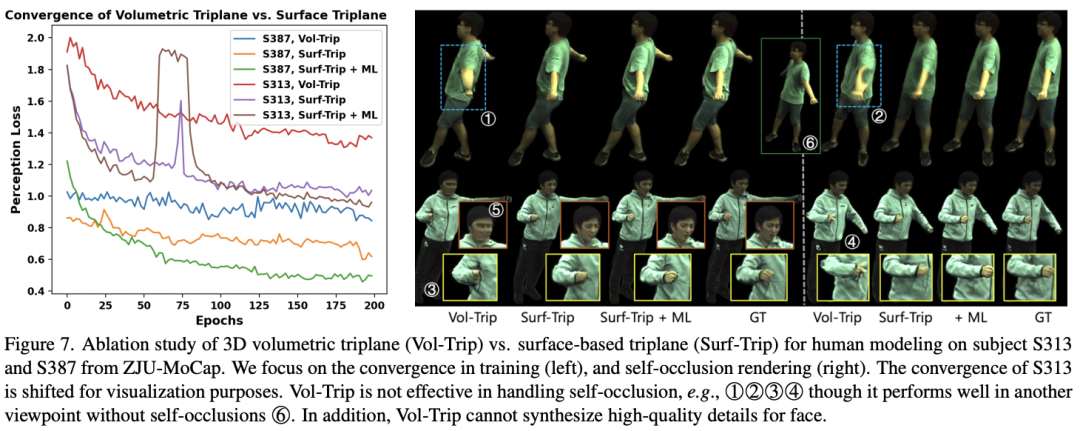

The above is the detailed content of CVPR 2024 | AI can also highly restore the flying skirt when dancing. Nanyang Polytechnic proposes a new paradigm for dynamic human body rendering. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
The library used for floating-point number operation in Go language introduces how to ensure the accuracy is...
 How to run the h5 project
Apr 06, 2025 pm 12:21 PM
How to run the h5 project
Apr 06, 2025 pm 12:21 PM
Running the H5 project requires the following steps: installing necessary tools such as web server, Node.js, development tools, etc. Build a development environment, create project folders, initialize projects, and write code. Start the development server and run the command using the command line. Preview the project in your browser and enter the development server URL. Publish projects, optimize code, deploy projects, and set up web server configuration.
 Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
GiteePages static website deployment failed: 404 error troubleshooting and resolution when using Gitee...
 How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
Under the BeegoORM framework, how to specify the database associated with the model? Many Beego projects require multiple databases to be operated simultaneously. When using Beego...
 Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or well-known open source projects? When programming in Go, developers often encounter some common needs, ...
 How to solve the user_id type conversion problem when using Redis Stream to implement message queues in Go language?
Apr 02, 2025 pm 04:54 PM
How to solve the user_id type conversion problem when using Redis Stream to implement message queues in Go language?
Apr 02, 2025 pm 04:54 PM
The problem of using RedisStream to implement message queues in Go language is using Go language and Redis...
 Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
Does H5 page production require continuous maintenance?
Apr 05, 2025 pm 11:27 PM
The H5 page needs to be maintained continuously, because of factors such as code vulnerabilities, browser compatibility, performance optimization, security updates and user experience improvements. Effective maintenance methods include establishing a complete testing system, using version control tools, regularly monitoring page performance, collecting user feedback and formulating maintenance plans.
 When using sql.Open, why does not report an error when DSN passes empty?
Apr 02, 2025 pm 12:54 PM
When using sql.Open, why does not report an error when DSN passes empty?
Apr 02, 2025 pm 12:54 PM
When using sql.Open, why doesn’t the DSN report an error? In Go language, sql.Open...
