
 Technology peripherals
AI
CVPR 2024 | Byte proposes a new generation of data set COCONut, which is denser than COCO granular segmentation
Technology peripherals
AI
CVPR 2024 | Byte proposes a new generation of data set COCONut, which is denser than COCO granular segmentation
CVPR 2024 | Byte proposes a new generation of data set COCONut, which is denser than COCO granular segmentation

The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

Paper link: https://arxiv.org/abs/2404.08639 Code and data Set link: https://xdeng7.github.io/coconut.github.io/

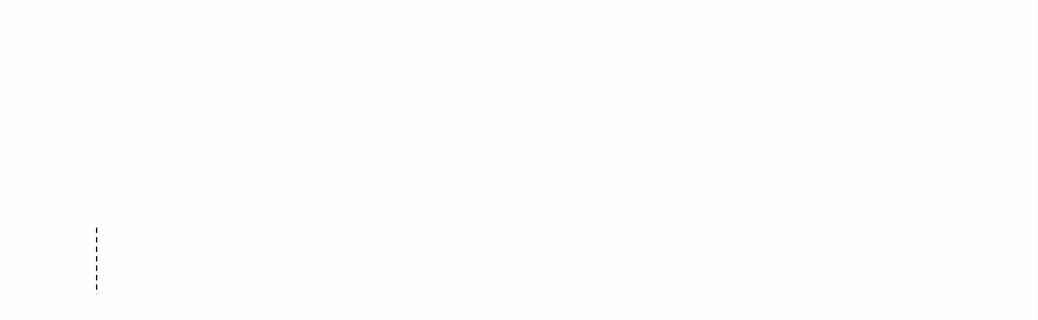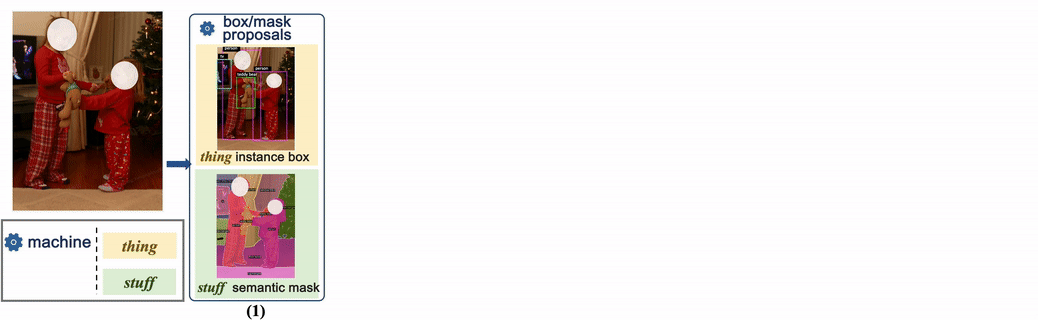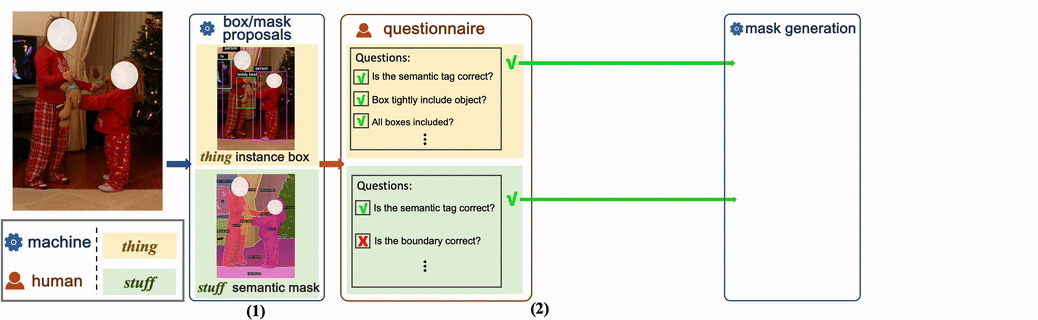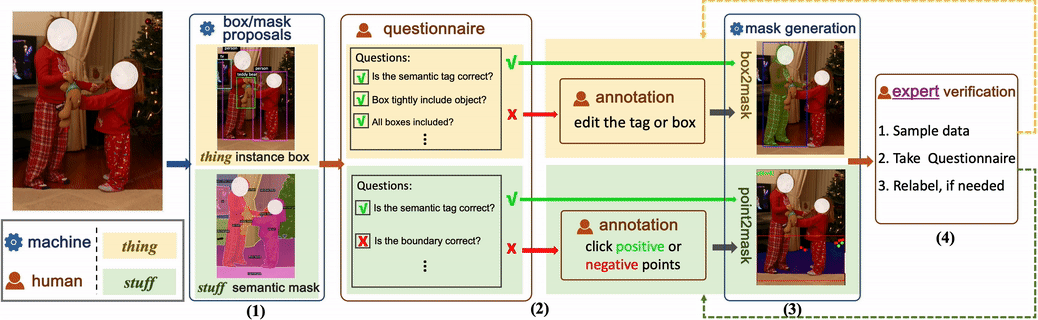


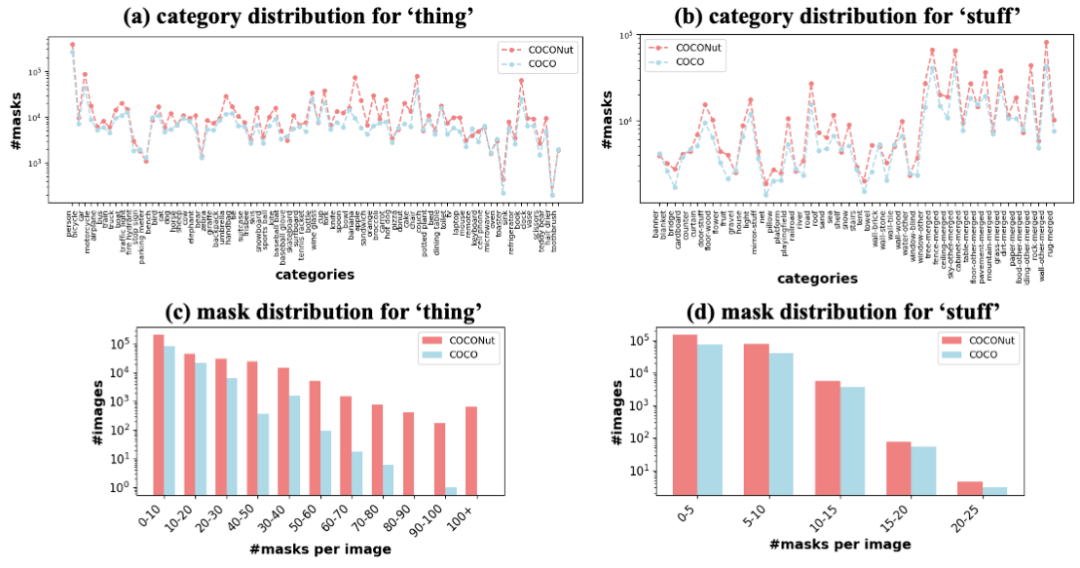
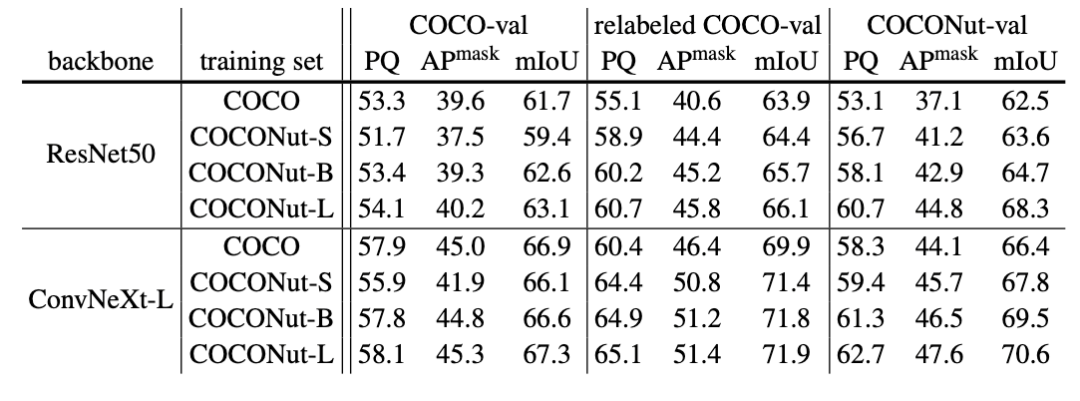
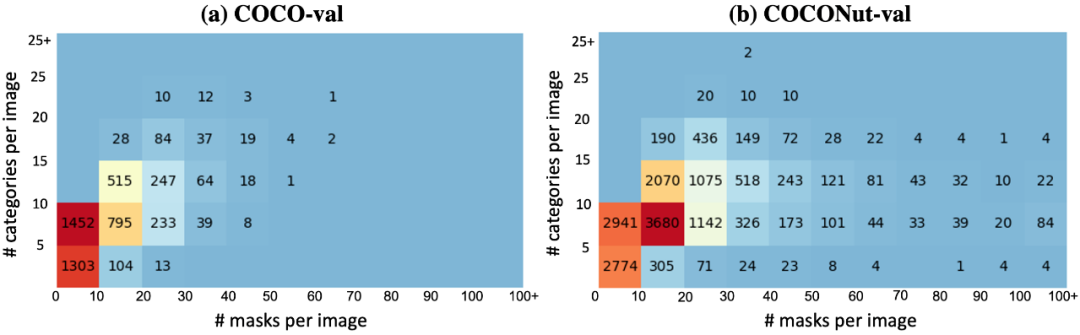
The above is the detailed content of CVPR 2024 | Byte proposes a new generation of data set COCONut, which is denser than COCO granular segmentation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
What libraries are used for floating point number operations in Go?
Apr 02, 2025 pm 02:06 PM
The library used for floating-point number operation in Go language introduces how to ensure the accuracy is...
 Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
Significantly surpassing SFT, the secret behind o1/DeepSeek-R1 can also be used in multimodal large models
Mar 12, 2025 pm 01:03 PM
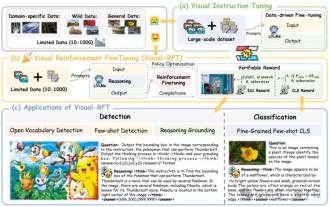
Researchers from Shanghai Jiaotong University, Shanghai AILab and the Chinese University of Hong Kong have launched the Visual-RFT (Visual Enhancement Fine Tuning) open source project, which requires only a small amount of data to significantly improve the performance of visual language big model (LVLM). Visual-RFT cleverly combines DeepSeek-R1's rule-based reinforcement learning approach with OpenAI's reinforcement fine-tuning (RFT) paradigm, successfully extending this approach from the text field to the visual field. By designing corresponding rule rewards for tasks such as visual subcategorization and object detection, Visual-RFT overcomes the limitations of the DeepSeek-R1 method being limited to text, mathematical reasoning and other fields, providing a new way for LVLM training. Vis
 Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or provided by well-known open source projects?
Apr 02, 2025 pm 04:12 PM
Which libraries in Go are developed by large companies or well-known open source projects? When programming in Go, developers often encounter some common needs, ...
 Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
Gitee Pages static website deployment failed: How to troubleshoot and resolve single file 404 errors?
Apr 04, 2025 pm 11:54 PM
GiteePages static website deployment failed: 404 error troubleshooting and resolution when using Gitee...
 How to obtain the shipping region data of the overseas version? What are some ready-made resources available?
Apr 01, 2025 am 08:15 AM
How to obtain the shipping region data of the overseas version? What are some ready-made resources available?
Apr 01, 2025 am 08:15 AM
Question description: How to obtain the shipping region data of the overseas version? Are there ready-made resources available? Get accurate in cross-border e-commerce or globalized business...
 Typecho route matching conflict: Why is my /test/tag/his/10086 matching TestTagIndex instead of TestTagPage?
Apr 01, 2025 am 09:03 AM
Typecho route matching conflict: Why is my /test/tag/his/10086 matching TestTagIndex instead of TestTagPage?
Apr 01, 2025 am 09:03 AM
Typecho routing matching rules analysis and problem investigation This article will analyze and answer questions about the inconsistent results of the Typecho plug-in routing registration and actual matching results...
 Python hourglass graph drawing: How to avoid variable undefined errors?
Apr 01, 2025 pm 06:27 PM
Python hourglass graph drawing: How to avoid variable undefined errors?
Apr 01, 2025 pm 06:27 PM
Getting started with Python: Hourglass Graphic Drawing and Input Verification This article will solve the variable definition problem encountered by a Python novice in the hourglass Graphic Drawing Program. Code...
 How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
How to specify the database associated with the model in Beego ORM?
Apr 02, 2025 pm 03:54 PM
Under the BeegoORM framework, how to specify the database associated with the model? Many Beego projects require multiple databases to be operated simultaneously. When using Beego...
